***********写在前面*************************************************************************************************
本文章所有内容都是我从其他前辈处摘录过来的,本人只是做了相应的整理,在文章中也标注了某一段的来源,文章结尾附了链接~~~~~~~~~~
***********以下是正文***********************************************************************************************
(泣血整理,内容很全,可以右侧查看目录,每个算法都有参考代码附上)
一、 决策树与线性模型、逻辑回归的区别
1. 决策树与线性模型
树形模型是一个一个特征进行处理,线性模型是所有特征给予权重相加得到一个新的值。
2. 决策树与逻辑回归
逻辑回归是将所有特征变换为概率后,通过大于某一概率阈值的划分为一类,小于某一概率阈值的为另一类;而决策树是对每一个特征做一个划分。另外逻辑回归只能找到线性分割(输入特征x与logit之间是线性的,除非对x进行多维映射),而决策树可以找到非线性分割。
树形模型更加接近人的思维方式,可以产生可视化的分类规则,产生的模型具有可解释性(可以抽取规则)。树模型拟合出来的函数其实是分区间的阶梯函数。(以上来源于参考链接【1】)
二、决策树

(二分树示例图,来源于【2】)
1. 基础介绍 :
决策树是一种机器学习的方法。决策树是一种树形结构,其中每个内部节点表示一个属性上的判断,每个分支代表一个判断结果的输出,最后每个叶节点代表一种分类结果。
决策树是一种十分常用的分类方法,属于有监督学习(Supervised Learning)。所谓有监管学习,就是给出一堆样本,每个样本都有一组属性和一个分类结果,也就是分类结果已知,那么通过学习这些样本得到一个决策树,这个决策树能够对新的数据给出正确的分类。
2. 一个简单的例子:
下面通过一个简单的例子来说明决策树的生成过程:
【样本】:学生情况数据
【样本量】:10
【变量】:分数,出勤率,回答问题次数,作业提交率
【目标变量】:是否为好学生
然后用这一组附带分类结果的样本可以训练出多种多样的决策树,这里为了简化过程,我们假设决策树为二叉树,且类似于下面的左图:
(左图) (右图)
通过学习上表的数据,可以得到A,B,C,D,E的具体值,而A,B,C,D,E则称为阈值。当然也可以有和左图完全不同的树形,比如右图这种的。
所以决策树的生成主要分以下两步,这两步通常通过学习已经知道分类结果的样本来实现。
- 节点的分裂:一般当一个节点所代表的属性无法给出判断时,则选择将这一节点分成2个子节点(如不是二叉树的情况会分成n个子节点)
- 阈值的确定:选择适当的阈值使得分类错误率最小 (Training Error)。
3. 常用决策树算法:
比较常用的决策树算法有ID3,C4.5和CART(Classification And Regression Tree),CART的分类效果一般优于其他决策树。下面具体介绍每一种决策树的构造过程。(以上来源于参考链接【3】)
(A)ID3算法
- ID3概述
ID3算法是由Quinlan首先提出的,该算法是以信息论为基础,以信息熵和信息增益为衡量标准,从而实现对数据的归纳分类。
- ID3要解决的问题
在ID3算法中,选择信息增益最大的属性作为当前的特征对数据集分类。信息增益的概念将在下面介绍,通过不断的选择特征对数据集不断划分;
2. 如何判断划分的结束?
第一种为划分出来的类属于同一个类;第二种为已经没有属性可供再分了。此时就结束了。

- ID3划分数据的依据
ID3算法是以信息熵和信息增益作为衡量标准的分类算法。
1. 信息熵(Entropy):
熵的概念主要是指信息的混乱程度,变量的不确定性越大,熵的值也就越大,熵的公式可以表示为:
其中,
是类别
在样本
中出现的频率。
2. 信息增益(Information gain):
信息增益指的是划分前后熵的变化,可以用下面的公式表示:
其中,
代表样本的属性,
代表属性
是属性
是
(以上来源于参考链接【4】)
- ID3参考代码
#!/usr/bin/env python
# encoding:utf-8
from math import log
def calEntropy(dataSet):
"""calcuate entropy(s)
@dateSet a training set
"""
size = len(dataSet)
laberCount = {}
for item in dataSet:
laber = item[-1]
if laber not in laberCount.keys():
laberCount[laber] = 0
laberCount[laber] += 1
entropy = 0.0
for laber in laberCount:
prob = float(laberCount[laber])/size
entropy -= prob * log(prob, 2)
return entropy
def splitDataSet(dataSet, i, value):
"""split data set by value with a laber
@dataSet a training sets
@i the test laber axis
@value the test value
"""
retDataSet = []
for item in dataSet:
if item[i] == value:
newData = item[:i]
newData.extend(item[i+1:])
retDataSet.append(newData)
return retDataSet
def chooseBestLaber(dataSet):
"""choose the best laber in labers
@dataSet a traing set
"""
numLaber = len(dataSet[0]) - 1
baseEntropy = calEntropy(dataSet)
maxInfoGain = 0.0
bestLaber = -1
size = len(dataSet)
for i in range(numLaber):
uniqueValues = set([item[i] for item in dataSet])
newEntropy = 0.0
for value in uniqueValues:
subDataSet = splitDataSet(dataSet, i, value)
prob = float(len(subDataSet))/size
newEntropy += prob * calEntropy(subDataSet)
infoGain = baseEntropy - newEntropy
if infoGain > maxInfoGain:
maxInfoGain = infoGain
bestLaber = i
return bestLaber
class Node:
"""the node of tree"""
def __init__(self, laber, val):
self.val = val
self.left = None
self.right = None
self.laber = laber
def setLeft(self, node):
self.left = node
def setRight(self, node):
self.right = node
signalNode = []
def generateNode(lastNode, dataSet, labers):
leftDataSet = filter(lambda x:x[-1]==0, dataSet)
rightDataSet = filter(lambda x:x[-1]==1, dataSet)
print "left:", leftDataSet
print "right:", rightDataSet
print "labers:", labers
if len(leftDataSet) == 0 and len(rightDataSet) == 0:
return
next = 0
print "%s ->generate left"%lastNode.laber
if len(leftDataSet) == 0:
print ">>> pre:%s %d stop no"%(lastNode.laber, 0)
lastNode.setLeft(Node("no", 0))
elif len(leftDataSet) == len(dataSet):
print ">>> pre:%s %d stop yes"%(lastNode.laber, 0)
lastNode.setLeft(Node("yes", 0))
else:
laber = chooseBestLaber(leftDataSet)
if laber == -1:
print ">>> can't find best one"
laber = next
next = (next + 1)%len(labers)
print ">>> ",labers[laber]
leftLabers = labers[:laber] + labers[laber+1:]
leftDataSet = map(lambda x:x[0:laber] + x[laber+1:], leftDataSet)
node = Node(labers[laber], 0)
lastNode.setLeft(node)
generateNode(node, leftDataSet, leftLabers)
print "%s ->generate right"%lastNode.laber
if len(rightDataSet) == 0:
print ">>> pre:%s %d no"%(lastNode.laber, 1)
lastNode.setRight(Node("no", 1))
elif len(rightDataSet) == len(dataSet):
print ">>> pre:%s %d yes"%(lastNode.laber, 1)
lastNode.setRight(Node("yes", 1))
else:
laber = chooseBestLaber(rightDataSet)
if laber == -1:
print ">>> can't find best one"
laber = next
next = (next + 1)%len(labers)
print ">>> ",labers[laber]
rightLabers = labers[:laber] + labers[laber+1:]
rightDataSet = map(lambda x:x[0:laber] + x[laber+1:], rightDataSet)
node = Node(labers[laber], 0)
lastNode.setRight(node)
generateNode(node, rightDataSet, rightLabers)
def generateDecisionTree(dataSet, labers):
"""generate a decision tree
@dataSet a training sets
@labers a list of feature laber
"""
root = None
laber = chooseBestLaber(dataSet)
if laber == -1:
print "can't find a best laber in labers"
return None
print ">>>> ",labers[laber]
root = Node(labers[laber], 1)
labers = labers[:laber] + labers[laber+1:]
dataSet = map(lambda x:x[0:laber] + x[laber+1:], dataSet)
generateNode(root, dataSet, labers)
return root
"""
price size color result
---- ---- ---- ----
cheap big white like
cheap small white like
expensive big white like
expensive small white like
cheap small black don't like
cheap big black don't like
expensive big black don't like
expensive small black don't like
"""
dataSet = [
[0, 1, 1, 1],
[0, 0, 1, 1],
[1, 1, 1, 1],
[1, 0, 1, 1],
[0, 0, 0, 0],
[0, 1, 0, 0],
[1, 1, 0, 0],
[1, 0, 0, 0]]
labers = ["price", "size", "color"]
if __name__ == "__main__":
generateDecisionTree(dataSet, labers)(参考代码来源于参考链接【2】)
(B)C4.5算法
- C4.5概述
C4.5 算法是对 ID3 算法的改进,既然是改进,那么必然是解决了一些问题,而且这些问题还是比较突出的。
1. 解决了信息增益(IG)的缺点:
上文在说 ID3 算法时,了解到 IG 是描述某一个特征属性的存在与否,对总体信息熵的变化量影响。通过 IG 的公式,可以推测出,当某一个时刻总的信息熵固定时,只要条件熵(就是某一特征属性的信息熵) Entropy(S|T) 越小,那么 IG 的值就越大。通过条件熵的计算公式,又可以推测出,如果某一个特性属性的取值越多,那么这个条件熵的值就会越小。从而,采用 IG 最大法选择构建决策,在某一程度上可以理解成选择多取值的特征属性。对于这个问题,C4.5 的做法是引入分裂信息,然后计算信息增益率(IGR)。
(其中,IG 为信息增益,IV 为分裂信息)
(其中,vi为某一特征属性下的第 i 个分支属性)


2. 连续变量问题:
在 ID3 中,我们不能解决连续变量问题,对于一些连续型的变量时,ID3 的做法就是对每一个不同值的变量进行分开计算,这样就出现了一个问题,ID3 构建的决策树中产生了过多的分支。这个时候,你可能会想说,如果把这些值修改成某一个域值,让小于等于这个域值的数据放在决策树的左边,大于这个域值的数据放在决策树的右边。C4.5 中就是这么干的,只是 C4.5 在寻找这个域值时,更加合理。
(上述论述均来源于参考链接【5】,另外也可阅读《为什么要改进成C4.5算法》(该文中还包含代码),但本文未引入)
- C4.5计算逻辑(局部):
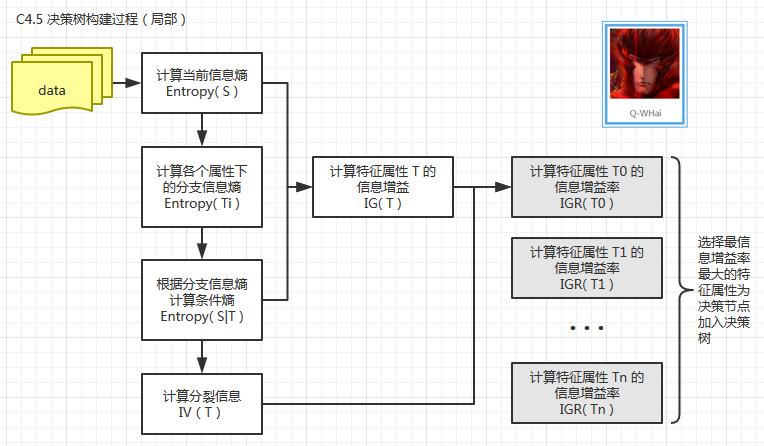
算法的完整逻辑逻辑请参考ID3的逻辑图(上面的局部就是”特征选择“的放大)
(以上来源于参考链接【5】)
- C4.5参考代码
# -*- coding: utf-8 -*-
__author__ = 'Wsine'
from math import log
import operator
import treePlotter
def calcShannonEnt(dataSet):
"""
输入:数据集
输出:数据集的香农熵
描述:计算给定数据集的香农熵;熵越大,数据集的混乱程度越大
"""
numEntries = len(dataSet)
labelCounts = {}
for featVec in dataSet:
currentLabel = featVec[-1]
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1
shannonEnt = 0.0
for key in labelCounts:
prob = float(labelCounts[key])/numEntries
shannonEnt -= prob * log(prob, 2)
return shannonEnt
def splitDataSet(dataSet, axis, value):
"""
输入:数据集,选择维度,选择值
输出:划分数据集
描述:按照给定特征划分数据集;去除选择维度中等于选择值的项
"""
retDataSet = []
for featVec in dataSet:
if featVec[axis] == value:
reduceFeatVec = featVec[:axis]
reduceFeatVec.extend(featVec[axis+1:])
retDataSet.append(reduceFeatVec)
return retDataSet
def chooseBestFeatureToSplit(dataSet):
"""
输入:数据集
输出:最好的划分维度
描述:选择最好的数据集划分维度
"""
numFeatures = len(dataSet[0]) - 1
baseEntropy = calcShannonEnt(dataSet)
bestInfoGainRatio = 0.0
bestFeature = -1
for i in range(numFeatures):
featList = [example[i] for example in dataSet]
uniqueVals = set(featList)
newEntropy = 0.0
splitInfo = 0.0
for value in uniqueVals:
subDataSet = splitDataSet(dataSet, i, value)
prob = len(subDataSet)/float(len(dataSet))
newEntropy += prob * calcShannonEnt(subDataSet)
splitInfo += -prob * log(prob, 2)
infoGain = baseEntropy - newEntropy
if (splitInfo == 0): # fix the overflow bug
continue
infoGainRatio = infoGain / splitInfo
if (infoGainRatio > bestInfoGainRatio):
bestInfoGainRatio = infoGainRatio
bestFeature = i
return bestFeature
def majorityCnt(classList):
"""
输入:分类类别列表
输出:子节点的分类
描述:数据集已经处理了所有属性,但是类标签依然不是唯一的,
采用多数判决的方法决定该子节点的分类
"""
classCount = {}
for vote in classList:
if vote not in classCount.keys():
classCount[vote] = 0
classCount[vote] += 1
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reversed=True)
return sortedClassCount[0][0]
def createTree(dataSet, labels):
"""
输入:数据集,特征标签
输出:决策树
描述:递归构建决策树,利用上述的函数
"""
classList = [example[-1] for example in dataSet]
if classList.count(classList[0]) == len(classList):
# 类别完全相同,停止划分
return classList[0]
if len(dataSet[0]) == 1:
# 遍历完所有特征时返回出现次数最多的
return majorityCnt(classList)
bestFeat = chooseBestFeatureToSplit(dataSet)
bestFeatLabel = labels[bestFeat]
myTree = {bestFeatLabel:{}}
del(labels[bestFeat])
# 得到列表包括节点所有的属性值
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues)
for value in uniqueVals:
subLabels = labels[:]
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value), subLabels)
return myTree
def classify(inputTree, featLabels, testVec):
"""
输入:决策树,分类标签,测试数据
输出:决策结果
描述:跑决策树
"""
firstStr = list(inputTree.keys())[0]
secondDict = inputTree[firstStr]
featIndex = featLabels.index(firstStr)
for key in secondDict.keys():
if testVec[featIndex] == key:
if type(secondDict[key]).__name__ == 'dict':
classLabel = classify(secondDict[key], featLabels, testVec)
else:
classLabel = secondDict[key]
return classLabel
def classifyAll(inputTree, featLabels, testDataSet):
"""
输入:决策树,分类标签,测试数据集
输出:决策结果
描述:跑决策树
"""
classLabelAll = []
for testVec in testDataSet:
classLabelAll.append(classify(inputTree, featLabels, testVec))
return classLabelAll
def storeTree(inputTree, filename):
"""
输入:决策树,保存文件路径
输出:
描述:保存决策树到文件
"""
import pickle
fw = open(filename, 'wb')
pickle.dump(inputTree, fw)
fw.close()
def grabTree(filename):
"""
输入:文件路径名
输出:决策树
描述:从文件读取决策树
"""
import pickle
fr = open(filename, 'rb')
return pickle.load(fr)
def createDataSet():
"""
outlook-> 0: sunny | 1: overcast | 2: rain
temperature-> 0: hot | 1: mild | 2: cool
humidity-> 0: high | 1: normal
windy-> 0: false | 1: true
"""
dataSet = [[0, 0, 0, 0, 'N'],
[0, 0, 0, 1, 'N'],
[1, 0, 0, 0, 'Y'],
[2, 1, 0, 0, 'Y'],
[2, 2, 1, 0, 'Y'],
[2, 2, 1, 1, 'N'],
[1, 2, 1, 1, 'Y']]
labels = ['outlook', 'temperature', 'humidity', 'windy']
return dataSet, labels
def createTestSet():
"""
outlook-> 0: sunny | 1: overcast | 2: rain
temperature-> 0: hot | 1: mild | 2: cool
humidity-> 0: high | 1: normal
windy-> 0: false | 1: true
"""
testSet = [[0, 1, 0, 0],
[0, 2, 1, 0],
[2, 1, 1, 0],
[0, 1, 1, 1],
[1, 1, 0, 1],
[1, 0, 1, 0],
[2, 1, 0, 1]]
return testSet
def main():
dataSet, labels = createDataSet()
labels_tmp = labels[:] # 拷贝,createTree会改变labels
desicionTree = createTree(dataSet, labels_tmp)
#storeTree(desicionTree, 'classifierStorage.txt')
#desicionTree = grabTree('classifierStorage.txt')
print('desicionTree:\n', desicionTree)
treePlotter.createPlot(desicionTree)
testSet = createTestSet()
print('classifyResult:\n', classifyAll(desicionTree, labels, testSet))
if __name__ == '__main__':
main()import matplotlib.pyplot as plt
decisionNode = dict(boxstyle="sawtooth", fc="0.8")
leafNode = dict(boxstyle="round4", fc="0.8")
arrow_args = dict(arrowstyle="<-")
def plotNode(nodeTxt, centerPt, parentPt, nodeType):
createPlot.ax1.annotate(nodeTxt, xy=parentPt, xycoords='axes fraction', \
xytext=centerPt, textcoords='axes fraction', \
va="center", ha="center", bbox=nodeType, arrowprops=arrow_args)
def getNumLeafs(myTree):
numLeafs = 0
firstStr = list(myTree.keys())[0]
secondDict = myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[key]).__name__ == 'dict':
numLeafs += getNumLeafs(secondDict[key])
else:
numLeafs += 1
return numLeafs
def getTreeDepth(myTree):
maxDepth = 0
firstStr = list(myTree.keys())[0]
secondDict = myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[key]).__name__ == 'dict':
thisDepth = getTreeDepth(secondDict[key]) + 1
else:
thisDepth = 1
if thisDepth > maxDepth:
maxDepth = thisDepth
return maxDepth
def plotMidText(cntrPt, parentPt, txtString):
xMid = (parentPt[0] - cntrPt[0]) / 2.0 + cntrPt[0]
yMid = (parentPt[1] - cntrPt[1]) / 2.0 + cntrPt[1]
createPlot.ax1.text(xMid, yMid, txtString)
def plotTree(myTree, parentPt, nodeTxt):
numLeafs = getNumLeafs(myTree)
depth = getTreeDepth(myTree)
firstStr = list(myTree.keys())[0]
cntrPt = (plotTree.xOff + (1.0 + float(numLeafs)) / 2.0 / plotTree.totalw, plotTree.yOff)
plotMidText(cntrPt, parentPt, nodeTxt)
plotNode(firstStr, cntrPt, parentPt, decisionNode)
secondDict = myTree[firstStr]
plotTree.yOff = plotTree.yOff - 1.0 / plotTree.totalD
for key in secondDict.keys():
if type(secondDict[key]).__name__ == 'dict':
plotTree(secondDict[key], cntrPt, str(key))
else:
plotTree.xOff = plotTree.xOff + 1.0 / plotTree.totalw
plotNode(secondDict[key], (plotTree.xOff, plotTree.yOff), cntrPt, leafNode)
plotMidText((plotTree.xOff, plotTree.yOff), cntrPt, str(key))
plotTree.yOff = plotTree.yOff + 1.0 / plotTree.totalD
def createPlot(inTree):
fig = plt.figure(1, facecolor='white')
fig.clf()
axprops = dict(xticks=[], yticks=[])
createPlot.ax1 = plt.subplot(111, frameon=False, **axprops)
plotTree.totalw = float(getNumLeafs(inTree))
plotTree.totalD = float(getTreeDepth(inTree))
plotTree.xOff = -0.5 / plotTree.totalw
plotTree.yOff = 1.0
plotTree(inTree, (0.5, 1.0), '')
plt.show()(C)CART(Classification And Regression Tree,分类 回归树)算法
- CART概述:
CART假设决策树是二叉树,内部结点特征的取值为“是”和“否”,左分支是取值为“是”的分支,右分支是取值为“否”的分支。这样的决策树等价于递归地二分每个特征,将输入空间即特征空间划分为有限个单元,并在这些单元上确定预测的概率分布,也就是在输入给定的条件下输出的条件概率分布。(CART算法生成的决策树是结构简洁的二叉树)
CART算法由以下两步组成:
1. 决策树生成:基于训练数据集生成决策树,生成的决策树要尽量大;
2. 决策树剪枝:用验证数据集对已生成的树进行剪枝并选择最优子树,这时损失函数最小作为剪枝的标准。
- CART算法逻辑:
1. Gini系数介绍:
在CART算法中, Gini不纯度表示一个随机选中的样本在子集中被分错的可能性。Gini不纯度为这个样本被选中的概率乘以它被分错的概率。当一个节点中所有样本都是一个类时,Gini不纯度为零。
假设y的可能取值为{1, 2, ..., m},令fi是样本被赋予i的概率,则Gini指数可以通过如下计算:
在CART分类树中,如果训练数据集D根据特征A是否取某一可能值a被分割为D1和D2两部分,则在特征A的条件下,集合D的基尼指数定义为:
基尼指数Gini(D)表示集合D的不确定性,基尼指数Gini(D,A)表示经过A=a分割后集合D的不确定性。基尼指数越大,样本的不确定性也就越大。
(Gini系数介绍部分来源于参考链接【8】)
2. 一个具体的例子:
下面来看一个具体的例子。我们使用《数据挖掘十大算法之决策树详解(1)》中图4-6所示的数据集来作为示例,为了便于后面的叙述,我们将其再列出如下:
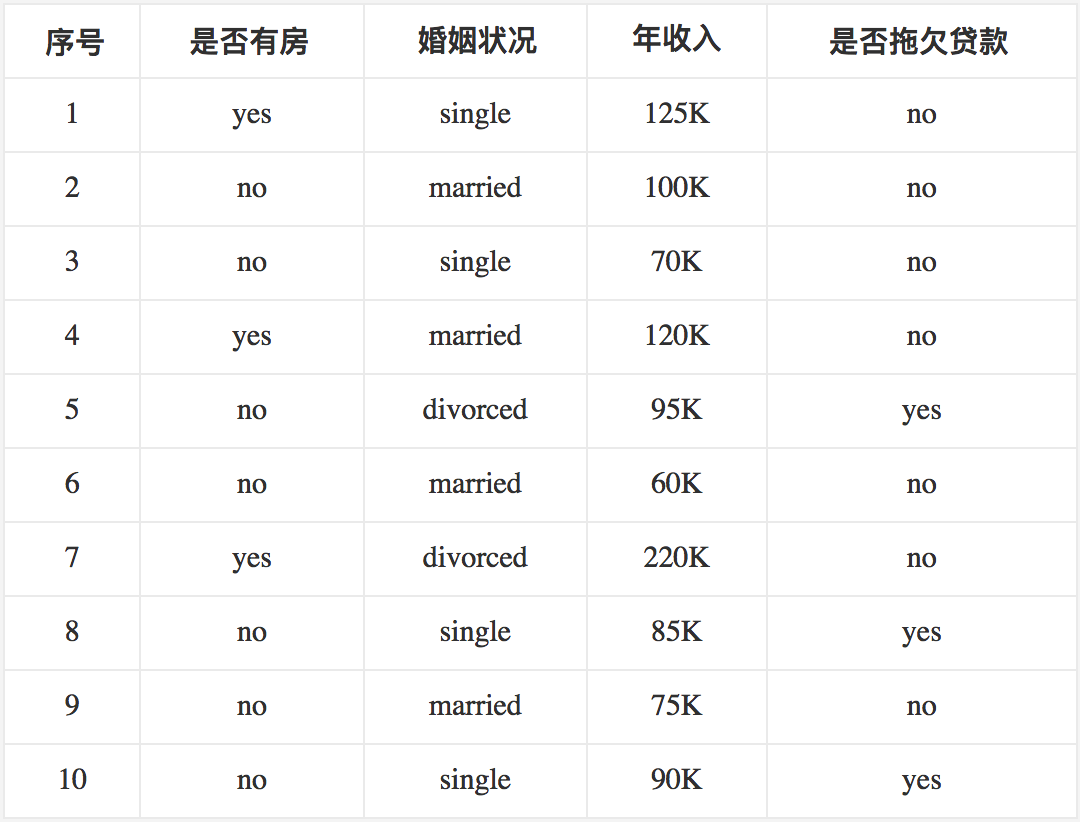
(以上来源于参考链接【7】)首先对数据集非类标号属性{是否有房,婚姻状况,年收入}分别计算它们的Gini系数增益,取Gini系数增益值最大的属性作为决策树的根节点属性。根节点的Gini系数 :
当根据是否有房来进行划分时,Gini系数增益计算过程为 :
若按婚姻状况属性来划分,属性婚姻状况有三个可能的取值{married,single,divorced},分别计算划分后的:
- {married} | {single,divorced}
- {single} | {married,divorced}
- {divorced} | {single,married}
当分组为{married} | {single,divorced}时,
当分组为{single} | {married,divorced}时,
当分组为{divorced} | {single,married}时,
对比计算结果,根据婚姻状况属性来划分根节点时取Gini系数增益最大的分组作为划分结果,也就是{married} | {single,divorced}。
对于年收入属性为数值型属性,首先需要对数据按升序排序,然后从小到大依次用相邻值的中间值作为分隔将样本划分为两组。例如当面对年收入为60和70这两个值时,我们算得其中间值为65。倘若以中间值65作为分割点。Sl作为年收入小于65的样本,Sr表示年收入大于等于65的样本,于是则得Gini系数增益为:
其他值的计算同理可得,我们不再逐一给出计算过程,仅列出结果如下(最终我们取其中使得增益最大化的那个二分准则来作为构建二叉树的准则):
注意,这与我们之前在《数据挖掘十大算法之决策树详解(1)》中得到的结果是一致的。最大化增益等价于最小化子女结点的不纯性度量(Gini系数)的加权平均值,之前的表里我们列出的是Gini系数的加权平均值,现在的表里给出的是Gini系数增益。现在我们希望最大化Gini系数的增益。根据计算知道,三个属性划分根节点的增益最大的有两个:年收入属性和婚姻状况,他们的增益都为0.12。此时,选取首先出现的属性作为第一次划分。
接下来,采用同样的方法,分别计算剩下属性,其中根节点的Gini系数为(此时是否拖欠贷款的各有3个records):
与前面的计算过程类似,对于是否有房属性,可得:
对于年收入属性则有:
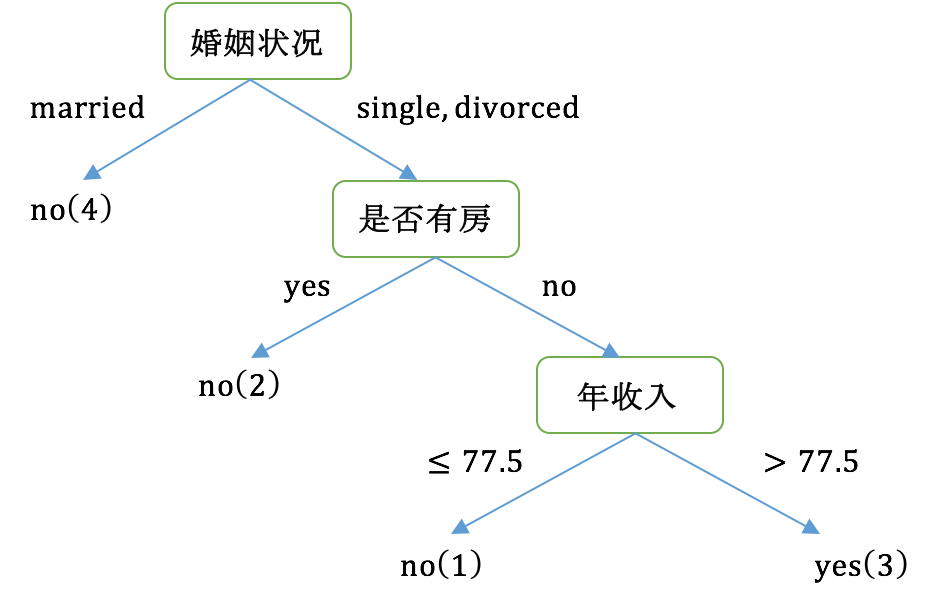
最后我们构建的CART如下图所示:











- CART参考代码:
import numpy as np
from collections import namedtuple
from abc import ABCMeta, abstractmethod, abstractstaticmethod
# 决策树结点
# Parameters
# ----------
# feature : 特征,需要进行比对的特征名
# val : 特征值,当特征为离散值时,如果对应的特征值等于val,将其放入左子树,否则放入右子树
# left : 左子树
# right : 右子树
# label : 所属的类
TreeNode = namedtuple("TreeNode", 'feature val left right label')
class DecisionTree(object, metaclass=ABCMeta):
def __init__(self, max_depth=None):
self.max_depth = max_depth
def build(self, X_, features, depth=None):
if self.unique_cond(X_):
return TreeNode(None, None, None, None, self.get_target(X_))
if features.shape[0] == 0 or depth and depth >= self.max_depth:
return TreeNode(None, None, None, None, self.stop_early_target(X_))
feature, val = self.get_best_index(X_, features)
new_features = features[features != feature]
del features
left, right = self.devide(X_, feature, val)
if left.any():
left_branch = self.build(left, new_features, depth + 1 if depth else None)
else:
left_branch = TreeNode(None, None, None, None, val)
if right.any():
right_branch = self.build(right, new_features, depth + 1 if depth else None)
else:
right_branch = TreeNode(None, None, None, None, val)
return TreeNode(feature, val, left_branch, right_branch, None)
def fit(self, X, y):
features = np.arange(X.shape[1])
X_ = np.c_[X, y]
self.root = self.build(X_, features)
return self
def predict_one(self, x):
p = self.root
while p.label is None:
# print('feature', x[p.feature])
# print(p.val)
p = p.left if self.judge(x[p.feature], p.val) else p.right
return p.label
def predict(self, X):
"""
:param X: shape = [n_samples, n_features]
:return: shape = [n_samples]
"""
return np.array([self.predict_one(x) for x in X])
@abstractstaticmethod
def devide(X_, feature, val):
pass
@abstractmethod
def unique_cond(self, X_):
pass
@abstractmethod
def get_target(self, X_):
pass
@abstractmethod
def stop_early_target(self, X_):
pass
@abstractmethod
def judge(self, node_val, val):
pass
@abstractmethod
def get_best_index(self, X_, features):
pass
class DecisionTreeClassifier(DecisionTree):
def get_best_index(self, X_, features):
ginis = [DecisionTreeClassifier.get_fea_best_val(
np.c_[X_[:, i], X_[:, -1]]) for i in features]
ginis = np.array(ginis)
i = np.argmax(ginis[:, 1])
return features[i], ginis[i, 0]
def unique_cond(self, X_):
return True if np.unique(X_[:, -1]).shape[0] == 1 else False
def judge(self, node_val, val):
return True if node_val == val else False
def stop_early_target(self, X_):
classes, classes_count = np.unique(X_[:, -1], return_counts=True)
return classes[np.argmax(classes_count)]
def get_target(self, X_):
return X_[0, -1]
@staticmethod
def devide(X_, feature, val):
return X_[X_[:, feature] == val], X_[X_[:, feature] != val]
@staticmethod
def gini(D):
"""求基尼指数 Gini(D)
:param D: shape = [ni_samples]
:return: Gini(D)
"""
# 目前版本的 numpy.unique 不支持 axis 参数
_, cls_counts = np.unique(D, return_counts=True)
probability = cls_counts / cls_counts.sum()
return 1 - (probability ** 2).sum()
@staticmethod
def congini(D_, val):
"""求基尼指数 Gini(D, A)
:param D_: 被计算的列. shape=[ni_samples, 2]
:param val: 被计算的列对应的切分变量
:return: Gini(D, A)
"""
left, right = D_[D_[:, 0] == val], D_[D_[:, 0] != val]
return DecisionTreeClassifier.gini(left[:, -1]) * left.shape[0] / D_.shape[0] + \
DecisionTreeClassifier.gini(right[:, -1]) * right.shape[0] / D_.shape[0]
@staticmethod
def get_fea_best_val(D_):
"""寻找当前特征对应的最优切分变量
:param D_: 被计算的列. shape=[ni_samples, 2]
:return: 最优切分变量的值和基尼指数的最大值
"""
vals = np.unique(D_[:, :-1])
tmp = np.array([DecisionTreeClassifier.congini(D_, val) for val in vals])
return vals[np.argmax(tmp)], tmp.max()
class DecisionTreeRegressor(DecisionTree):
def get_best_index(self, X_, features):
losses = np.array([DecisionTreeRegressor.feature_min_loss(X_, feature) for feature in features])
i = np.argmin(losses[:, 1])
return features[i], losses[i, 0]
def unique_cond(self, X_):
return True if X_[:, -1].std() <= 0.1 else False
def judge(self, node_val, val):
return True if node_val <= val else False
def stop_early_target(self, X_):
self.get_target(X_)
def get_target(self, X_):
return X_[:, -1].mean()
@staticmethod
def devide(X_, feature, val):
return X_[X_[:, feature] <= val], X_[X_[:, feature] >= val]
@staticmethod
def feature_loss(X_, feature, val):
left, right = DecisionTreeRegressor.devide(X_, feature, val)
left_loss = np.sum((left[:, -1] - left[:, -1].mean()) ** 2)
right_loss = np.sum((right[:, -1] - right[:, -1].mean()) ** 2)
return left_loss + right_loss
@staticmethod
def feature_min_loss(X_, feature):
losses = np.array(list(map(lambda val: DecisionTreeRegressor.feature_loss(X_, feature, val), X_[:, feature])))
i = np.argmin(losses)
return X_[i, feature], losses[i](以上来源于参考链接【9】)
4. 总结三种算法:
最后用一张图来概括三种算法:

三、 致敬:
以上内容全部来自大神前辈们,在整理时就觉得十分倾佩仰慕,感谢大神的贡献,让我收益匪浅!!!!后面附上了大神们的原作,有需要的朋友请自行前往阅读!
【参考链接】
[1] 决策树与随机森林
[2] 决策树
[3] 决策树(Decision Tree):通俗易懂之介绍
[5] 决策树之 C4.5 算法
[7] 数据挖掘十大算法之CART详解
[8] CART算法中的基尼指数
[9] GitHub
******************2018-06-19 注释************************
参考代码还没有验证呢,先整理着~~~~~~~