
自 2022 年底 ChatGPT 的横空出世,人工智能再度成为全世界的焦点,基于大语言模型(LLM)的 AI 更是人工智能领域的“当红炸子鸡”。此后的一年,我们见证了 AI 在文生文、文生图领域的飞速进展,但在文生视频领域发展相对较慢。而在 2024 年开年,OpenAI 再度投放重磅炸弹——文生视频大模型 Sora,内容创作的最后一块拼图被 AI 补齐了。
一年前,一段史密斯吃面条的视频在社交媒体病毒式传播,画面中这位影帝面目狰狞,五官变形,以一种扭曲的姿态在吃着意大利面。这糟糕的画面提醒着我们当时的 AI 生成视频的技术才刚刚起步。

仅仅一年后,一段由 Sora 生成的“时尚女性走在东京街道上”的 AI 视频再次引爆社交媒体。在随后的 3 月份,Sora 又与来自世界各地的艺术家联手,正式推出了一系列颠覆传统的超现实艺术短片。下面这部由著名导演 Walter 结合 Sora 创作出来的短片《Air Head》,其画面精美逼真,内容天马行空,极具想象力。可以说 Sora 出道即“碾压”了 Gen-2、Pika、Stable Video Diffusion 等主流 AI 视频模型。

AI 的进化速度远超预期,我们可以轻易预见到,现有的产业格局,包括短视频、游戏、影视、广告等将在不久的将来迎来重塑。 Sora 的到来似乎让我们离构建世界的模型更近了一步。
Sora 为何有如此强大的魔力?它运用了哪些神奇的技术?笔者查阅了官方技术报告和众多相关文献后,将在本文为大家解读 Sora 背后的技术原理以及它成功的关键。
1 Sora 要解决什么核心问题?
用一句话概括,Sora 面对的挑战是如何将多种类型的视觉数据转化为统一的表示方法,从而可以进行大一统的训练。
为什么要做大一统训练?在回答这个问题之前,我们先了解一下 Sora 之前的主流 AI 视频生成思路。
1.1 前 Sora 时代 AI 视频生成方式
- 基于单帧图像内容进行扩展
基于单帧图像的扩展即用当前帧的内容去预测下一帧,每一帧都是上一帧的延续,从而形成连续的视频流(视频的本质就是一帧帧连续展示的图像)。
这个过程中,一般是先用文本描述来生成图像,再根据图像来生成视频。但是这种思路存在一个问题:用文本生成图像本身具有随机性,这种随机性在用图像生成视频时被二次放大,最终的视频可控性和稳定性很低。
- 对整段视频直接进行训练
既然基于单帧推导的视频效果不好,那就将思路转变为对整个视频进行训练。
这里通常会选取一个几秒钟的视频片段,并告诉模型这个视频展现的内容,通过大量的训练之后,AI 就能学会生成与训练数据风格相似的视频片段。而这种思路的缺陷在于,AI 学习到的内容是片段式的,难以生成长视频,且视频的连续性较差。
可能有人会问,为什么不用更长的视频进行训练?主要原因是视频相比于文字、图片来说是非常大的,而显卡的显存有限,并不能支持更长的视频训练。在种种限制之下,AI 的知识量极其有限,当输入它“不认识”的内容时,生成的效果往往不尽人意。
因此,想要突破 AI 视频的瓶颈,就必须解决这些核心问题。
1.2 视频模型训练的挑战
视频数据有各种各样的形式,从横屏到竖屏,从 240p 到 4K,不同的宽高比,不同的分辨率,视频属性各不相同。数据的复杂多样性给 AI 训练带来了很大的困难,进而导致模型的效果不佳。这也是为什么要先对这些视频数据进行统一化表示。
而 Sora 的核心任务就是找到这样一种方法,将多种类型的视觉数据转化为统一的表示方法,使得所有视频数据可以在统一的框架下进行有效训练。
1.3 Sora: 通往 AGI 的里程碑
Our mission is to ensure that artificial general intelligence benefits all of humanity. —— OpenAI
OpenAI 的目标一直很明确——实现通用人工智能(AGI),那么 Sora 的诞生对于实现 OpenAI 的目标有何意义呢?
要实现 AGI,大模型必须理解世界。纵观 OpenAI 的发展,最开始的 GPT 模型,让 AI 理解了文本(一维,只有长度),随后推出的 DALL·E 模型,让 AI 理解了图像(二维,长和宽),再到如今的 Sora 模型,让 AI 理解了视频(三维,长、宽以及时间)。
通过对文本、图像、视频的全方位理解,从而让 AI 循序渐进地理解这个世界。Sora 相当于 OpenAI 通往 AGI 的前哨站, 它不仅仅是一个视频生成模型,正如它的技术报告[1]标题所说:“作为世界模拟器的视频生成模型”。
而拓数派的愿景与 OpenAI 的目标不谋而合。拓数派认为:用少量符号和计算模型来建模人类社会和个体智能,奠定了早期的 AI,但更多的红利则依赖于更多的数据量和更高的计算能力。当我们不能构建开天辟地的新模型时,可以寻找更多的数据集、运用更大的算力来提高模型的准确率,以数据计算能力来换取模型能力,驱动数据计算系统的创新。在拓数派发布的大模型数据计算系统中,AI 数学模型、数据和计算三者将前所未有的无缝衔接、互为增强,成为推动社会高质量发展的新生产力[2]。
2 Sora 原理解读
Sora 并不是第一个发布的文生视频模型,为何它能引起轰动?它背后究竟有什么秘密?如果用一句话来描述 Sora 的训练流程:通过视觉编码器(visual encoder)将原始视频压缩到潜空间(latent space)并将其拆解为时空图像块(spacetime patches),这些时空图像块结合文本条件约束,通过 transformer 做 diffusion 的训练和生成,生成的时空图像块最后通过相应的视觉解码器(visual decoder)映射回像素空间。
2.1 视频压缩网络
Sora 首先会将原始视频数据转化为低维度潜空间特征。 我们日常观看的视频数据太过庞大,必须先将其转化为 AI 可以处理的低维度向量。在这里,OpenAI 借鉴了一篇经典的论文:Latent Diffusion Models[3]。
这篇论文的核心要点,是把原图提炼成一个潜空间特征,可以既保留原始图片的关键特征信息,同时又可以极大压缩数据量和信息量。
OpenAI 很可能对该论文中针对图片的变分自编码器(VAE)进行了升级,使其支持视频数据的处理。 这样,Sora 就能够将大量的原始视频数据转化为低维度的潜空间特征,即提炼了视频里的核心要点信息,这些信息能够表示这个视频的关键内容。
2.2 时空图像块(Spacetime Patches)
要进行大规模的 AI 视频训练,首先就要定义训练数据的基本单元。在大语言模型(LLM)中,训练的基本单元是 Token[4]。OpenAI 从 ChatGPT 的成功中汲取了灵感:Token 机制优雅地统一了不同形式的文本——代码、数学符号以及各种自然语言,那 Sora 能否找到属于它的“Token”?
得益于前人的研究成果,Sora 最终找到了答案——Patch。
- Vision Transformer(ViT)
什么是 Patch 呢?Patch 可以通俗地理解为图像块。 当需要处理的图像分辨率太大,直接训练并不现实。因此,在 Vision Transformer[5]这篇论文中提出了一个方法:将原图拆分为一个个大小相同的图像块(Patch),然后将这些图像块进行序列化并加上它们的位置信息(Position Embedding),这样就可以把复杂的图像转换为 Transformer 架构中最熟悉的序列,利用自注意力机制捕捉各个图像块之间的关系,最终理解整个图像的内容。
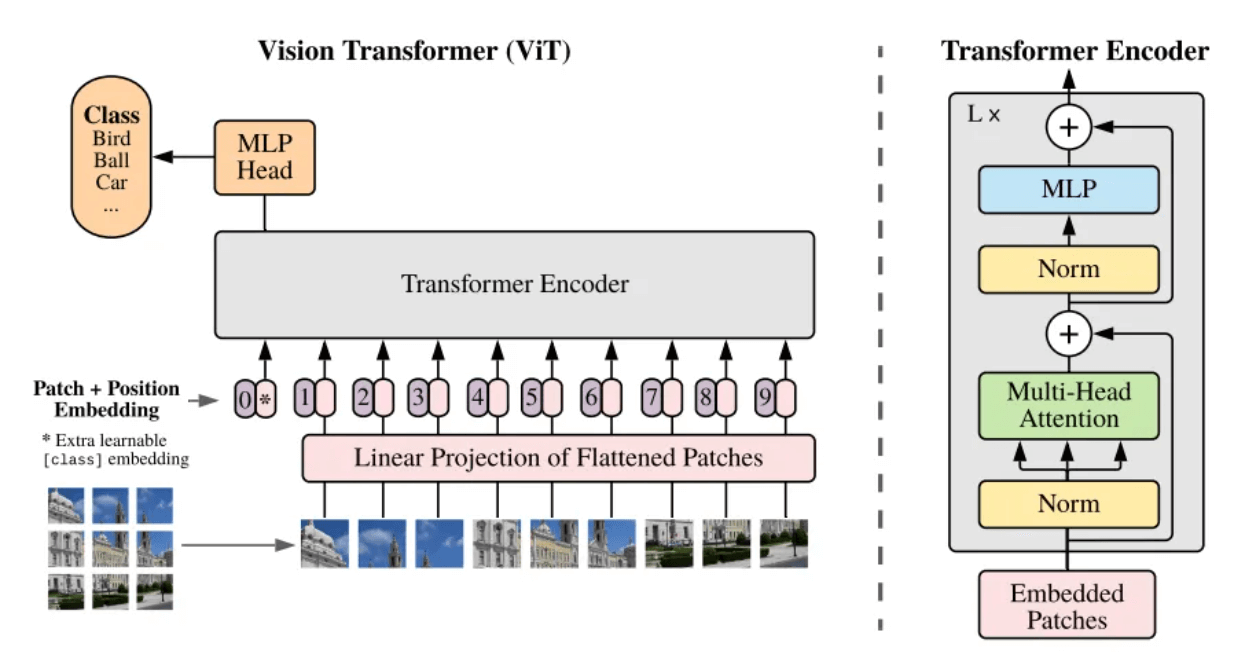
ViT 模型的框架结构[5]
而视频可以看作是沿着时间轴分布的图像序列,因此 Sora 加上了时间的维度,将静态的图像块升级成为时空图像块(Spacetime Patches)。 每一个时空图像块同时包含视频中的时间信息和空间信息,即一个时空图像块不仅代表了视频中的一小块空间区域,还代表了这个空间区域在一段时间内的变化情况。
通过引入 Patch 的概念,在单帧画面中不同位置的时空图像块可以计算空间关联性;连续帧中相同位置的时空图像块则可以计算时间关联性。各个图像块都不再是孤立的存在,而是与周围的元素紧密联系。通过这种方式,Sora 能够理解和生成具有丰富空间细节和时间动态的视频内容。

将序列帧分解为时空图像块
- Native Resolution(NaViT)
但是,ViT 模型有个非常大的缺点——原图必须是正方形且每个图像块是同一个固定尺寸。而日常的视频只有宽的或高的,并没有正方形的视频。
于是,OpenAI 又找到了另外的解决方法:NaViT 中的“Patch n' Pack”技术 [6] ,实现处理任意分辨率和宽高比的输入内容。
该技术将不同宽高比和分辨率的内容都拆成图像块,这些图像块可以根据不同的需求调整大小,来自不同图像的图像块可以灵活地被打包在同一序列里进行统一的训练。此外,该技术还可以根据图像的相似度丢弃雷同的图像块,大幅降低训练的成本,实现更快的训练。
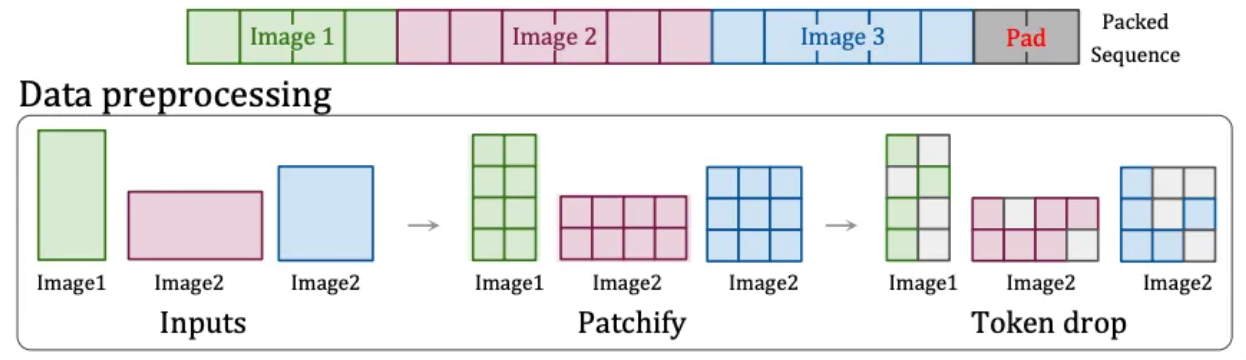
Patch n'Pack 技术[6]
这也是为什么 Sora 可以支持生成不同分辨率、宽高比的视频。并且,以原生长宽比进行训练可以改善输出视频的构图与取景,因为裁剪势必会损失信息,模型就容易理解错原图想展示的主体内容,从而导致生成只有部分主体的画面。
Spacetime Patches 扮演的角色,与大语言模型中 Token 的角色作用一样,它是构成视频的基本单元,当我们把一个视频压缩并分解成一系列的时空 Patch 时,实际上就是把连续的视觉信息转换成了一系列可以被模型处理的离散单元,它们是模型学习和生成的基础。
2.3 视频文本描述
通过上面的解释,我们已经了解 Sora 将原始视频转换为最终可训练的时空向量的过程。但在真正进行训练之前还需要解决一个问题:告诉模型这段视频讲述的内容。
要训练出文生视频模型,就必须建立起文本与视频的对应关系,在训练的时候就需要大量带有相应文本描述的视频,而人工标注的描述质量较低且不规范,影响训练结果。因此 OpenAI 借鉴了自家 DALL·E 3 中的 re-captioning 技术[7],并应用于视频领域。
具体来说,OpenAI 首先训练了一个高度描述性的字幕生成模型,用该模型按照规范为训练集中所有视频生成详细的描述信息,这部分文本描述信息在最终训练时与前文提到的时空图像块进行匹配和训练,Sora 就可以理解和对应上文本描述与视频图像块。
此外,OpenAI 还会利用 GPT 将用户简短的 prompt 转换为与训练时类似的更详细的描述语句,这使得 Sora 能够准确地按照用户的提示,生成高质量的视频。
2.4 视频训练与生成
在官方给出的技术报告 [1] 中明确提到:Sora is a diffusion transformer,即 Sora 是一个以 Transformer 为骨干网络的 Diffusion 模型。
- Diffusion Transformer(DiT)
Diffusion 的概念来源于物理中的扩散过程,比如一滴墨水滴入水中,它会随时间慢慢扩散,这个扩散就是从低熵到高熵的过程,你会看到墨水会从一滴,逐渐分散到水的各个部分。
受到该扩散过程的启发,扩散模型(Diffusion Model)诞生了。它是一个经典的“绘图”模型,Stable Diffusion 和 Midjourney 都是基于该模型产生的。它的基本原理是将原始图片逐渐加入噪声(Noise),让其逐渐变成完全的噪声状态,然后再反转这个过程,即降噪(Denoise)来恢复图片。通过让模型学习大量的逆转经验,最终使模型学会从噪声图中生成特定的图片内容。
根据报告透露的内容,Sora 采用的方法很可能是将原本 Diffusion 模型中的 U-Net 架构替换成了自己最熟悉的 Transformer 架构。 因为按照其他深度学习任务中的经验,相比于 U-Net,Transformer 架构的参数可拓展性强,随着参数量的增加,Transformer 架构的性能提升会更加明显。
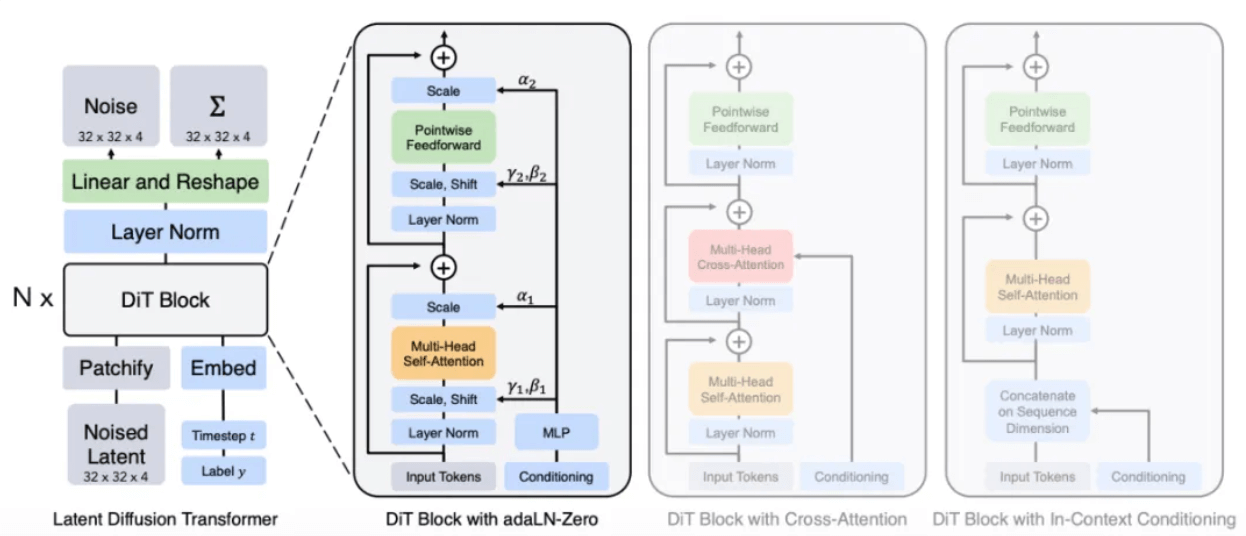
DiT 模型架构[8]
通过类似扩散模型的那套流程,在训练时给定噪声 Patches(以及文本提示等条件信息),反复地加噪、去噪,最终让模型学会预测出原始的 Patches。

将噪声 Patch 还原成原始图 Patch
- 视频生成过程
最后,我们总结一下 Sora 通过文本生成视频的整个流程。
当用户输入文本描述之后,Sora 首先会调用模型将其扩写成标准的视频描述语句,再根据该描述从噪点生成初始的时空图像块,然后 Sora 会基于已有的时空图像块以及文本条件来不断推测生成下一个时空图像块(类似 GPT 基于已有的 Token 来预测下一个 Token),最后再通过对应的解码器,将生成的潜在表示映射回像素空间,从而形成视频。
3 数据计算的潜力
纵观 Sora 的技术报告,我们可以发现事实上 Sora 在技术上并没有实现重大的突破,而是将之前的研究工作上进行了很好的整合,毕竟没有哪个技术会突然从某个角落冒出来。Sora 的成功更关键的原因是算力和数据的堆砌。
Sora 在训练过程中表现出明显的规模效应,下图展现了对于固定的输入和种子,随着计算量的增加,生成的样本质量显著提升。

基础算力,4 倍算力以及 32 倍算力下的效果对比
此外,通过学习了大量数据,Sora 还表现出一些意想不到的能力。
➢ 3D 一致性: Sora 能够生成带有动态摄像头运动的视频。随着摄像头的移动和旋转,人物和场景元素在三维空间中始终保持一致的运动规律。
➢ 长期一致性和物体持久性: 在长镜头中,人物、动物和物体即使在被遮挡或离开画面后,它们的外观也能保持一致。
➢ 世界交互性: Sora 能以简单的方式模拟影响世界状态的行为。比如在描述画画的视频中,每一笔都能在画布上留下痕迹。
➢ 模拟数字世界: Sora 还能够模拟游戏视频,例如《我的世界》。
这些特性并不需要对 3D、物体等进行明确的归纳偏置,它们纯粹是规模效应的现象。
4 拓数派大模型数据计算系统
Sora 的成功再一次证明“大力出奇迹”策略的有效性——模型规模的不断扩大,将直接推动性能的提升,这高度依赖于大量高质量数据集以及超大规模算力,数据和计算缺一不可。
拓数派在成立之初就将自己的使命定位为“数据计算,只为新发现”,我们的目标就是打造一个“无限模型游戏”。旗下大模型数据计算系统以云原生技术重构数据存储和计算,一份存储,多引擎数据计算,让 AI 模型更大更快,全面升级大数据系统至大模型时代。
在大模型数据计算系统中,世界万物和其运动可数字化为数据,数据可以用来训练初始模型,训练好的模型形成计算规则再加入到数据计算系统中,这个过程持续迭代无限探索 AI 智能。未来,拓数派将在数据领域继续探索,强化核心技术攻关能力,携手行业伙伴探索数据要素产业最佳实践,推动数智决策。
注:OpenAI 官方给出的技术报告中只展示了大致的建模方法,不涉及任何实现细节。本文如有纰漏错误之处,欢迎指正与交流。
参考文献:
- [1] Video Generation Models as World Simulators
- [2] 大模型数据计算系统——理论
- [3] High-Resolution Image Synthesis with Latent Diffusion Models
- [4] Attention Is All You Need
- [5] An Image Is Worth 16×16 Words: Transformers for Image Recognition at Scale
- [6] Patch n'Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution
- [7] Improving Image Generation with Better Captions
- [8] Scalable Diffusion Models with Transformers