
简介
《Segment Anything in High Quality》高质量的分割任何内容
日期:2023.6.2
单位:苏黎世联邦理工学院,香港科技大学
论文地址:https://arxiv.org/abs/2306.01567
GitHub: https://github.com/SysCV/SAM-HQ
作者:
柯磊

-
个人主页:http://www.kelei.site/

-
与SAM相关的paper

- 《Segment Anything Meets Point Tracking》2023.7.3
提出模型:SAM-PT,一种将稀疏点追踪与 SAM 相结合用于视频分割的方法- 《Cascade-DETR: Delving into High-Quality Universal Object Detection》2023.7.20 (ICCV)
通过级联注意力提高DETR的通用检测精度。这篇论文的命名应该是参考《Cascade R-CNN: Delving into High Quality Object Detection》,2017/12/03,CVPR2018。
-
其他作者:
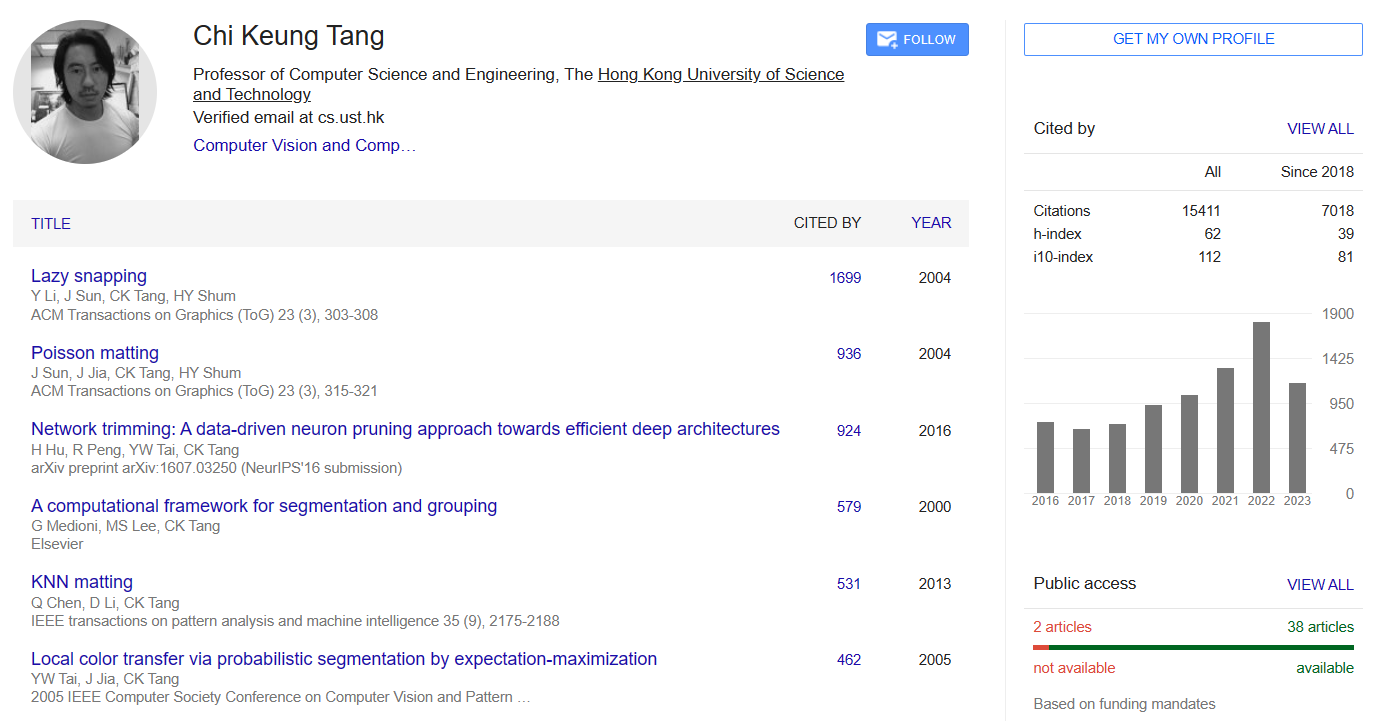
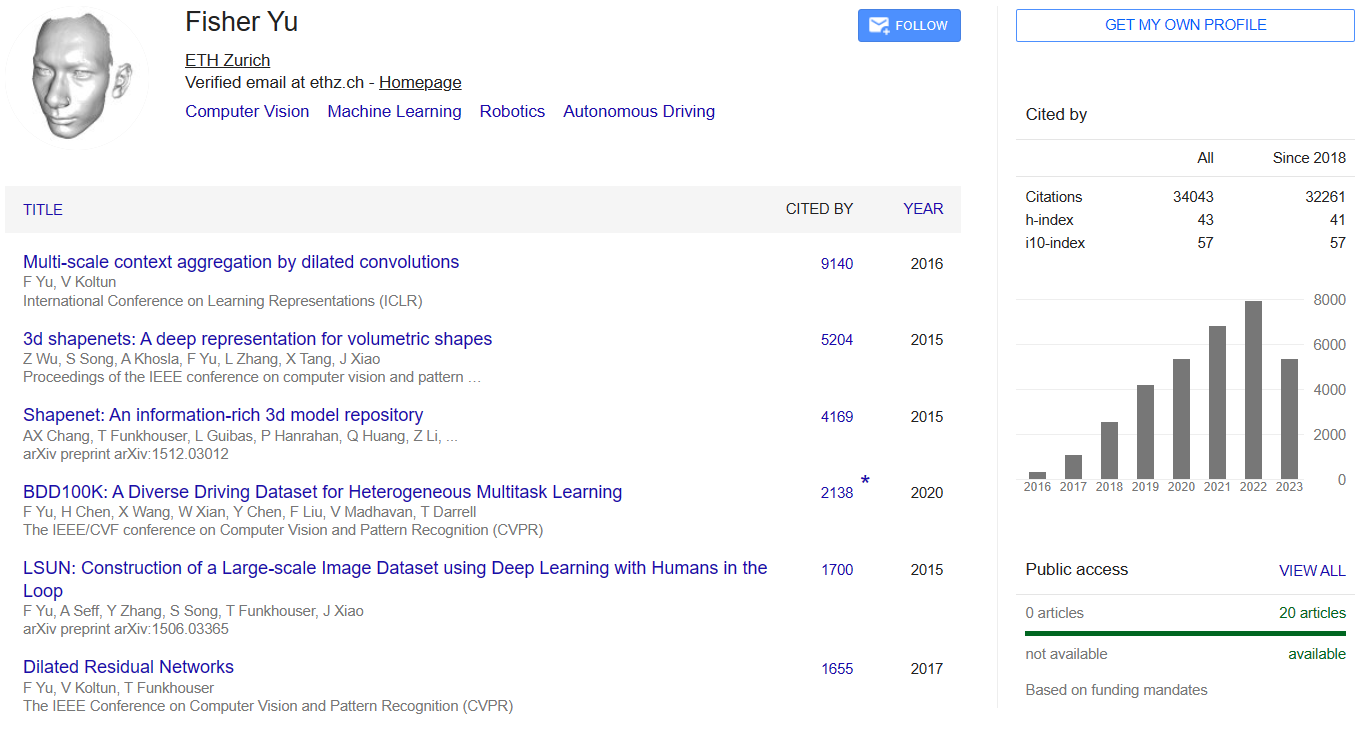
-
摘要
最近的分割一切模型(SAM)代表了一个巨大的飞跃,在扩大细分模型,允许强大的zero-shot能力和灵活的prompting。尽管使用了11亿个掩模进行训练,但SAM的掩模预测质量在许多情况下都存在不足,特别是在处理结构复杂的物体时。我们提出HQ-SAM,使SAM具备准确分割任何目标的能力,同时保持SAM原有的提示设计、效率和zero-shot通用性。我们的精心设计重用并保留了SAM的预训练模型权重,同时只引入了最小的额外参数和计算。我们设计了一个可学习的高质量输出token,它被注入到SAM的掩码解码器中,负责预测高质量的掩码。而不是只应用它的掩码解码器功能,我们首先融合了早期和最终的ViT功能,以改善掩码细节。为了训练我们引入的可学习参数,我们从几个来源组成了一个由44K个细粒度掩码组成的数据集。HQ-SAM只在引入的44,000个掩码的数据集上进行训练,在8个gpu上只需要4小时。我们展示了HQ-SAM在跨不同下游任务的9个不同分割数据集中的有效性,其中7个在zer-shot transfer测试中进行了评估。
目标
SAM的分割质量差,尤其对于物体细碎复杂的部分,难以做到精确的分割。因此希望能改进SAM,让其分割结果变得精细。本篇文章的目标就是,在保持SAM原有提示设计、效率以及zero-shot零样本泛化能力的基础上,产生更高质量的掩模

预测的SAM和我们的HQ-SAM的掩码,给出相同的红色框或物体上的几个点作为输入提示。HQ-SAM产生更详细的结果,边界非常精确。在最右边的一栏中,SAM误解了风筝线的薄结构,并产生了很大一部分输入框提示的破洞错误
从展示的结果来看,HQ-SAM确实在较细的物体或边缘上分割较好
创新点
在保留原始SAM的权重不变的情况下,添加少量的参数并训练就可以明显提高分割结果的精细度。
方法

HQ-SAM在SAM中引入了HQ-Output Token(高质量输出标记)和Global-local Feature Fusion(全局-局部特征融合),实现了高质量的掩码预测。为了保持SAM的零射击能力,轻量级HQ-Output Token重用SAM的掩码解码器,并生成新的MLP层,然后与HQ特征的进行点乘。在训练过程中,当我们对预训练的SAM参数进行固定,只有少数可学习的参数是可训练的。为了清晰起见,这里省略了提示编码器
- 回顾SAM
SAM由三个模块组成:(a)图像编码器:基于ViT的backbone,用于图像特征提取,实现图像在空间大小上的embeding,输出大小为256×64×64。(b)提示编码器:用于对输入的提示信息,如点/框/掩码的位置信息进行编码,输出是prompt embebding。©掩码解码器:输入是前面两个译码器输出的embeding,输出是预测的掩码,是基于两层transformer的解码器。
(发布的SAM模型是在大规模SA-1B数据集上训练的,该数据集包含超过10亿个自动生成的掩码(比任何现有的分割数据集多400倍)和1100万张图像。因此,SAM在不需要额外训练的情况下对新数据显示出有价值的强zero-shot transfer能力)


HQ-SAM在SAM中引入了HQ-Output Token(高质量输出标记)和Global-local Feature Fusion(全局-局部特征融合),实现了高质量的掩码预测。HQ-Output Token可以更好地指导高质量的掩模生成,而全局-局部特征融合则可以将来自不同阶段的特征提取和融合,丰富掩模特征的全局语义上下文和局部边界细节。除此之外,生成了新的MLP(多层感知器)层来执行与融合后的HQ-Features(高质量特征)的逐点乘积。
分别具体说明:
- HQ-Output token
为了提高HQ-SAM中SAM的掩码质量,不再直接将SAM的粗掩码作为输入,而是引入HQ-Output token和新的掩码预测层
HQ-Output Token是一个可学习的1x256的向量,和SAM的Prompt Token以及Output Token进行concat后输入到SAM的mask decoder。
与原始Output Token类似,在每个关注层中,HQ-Output Token首先与其他Token进行自注意力,然后进行Token到图像和反向图像到Token的注意力,以进行其特征更新。注意,HQ-Output token使用每个解码器层中其他Token共享的逐点MLP。经过两层解码器后,更新后的HQ-Output token可以访问全局图像上下文、提示token的关键几何/类型信息以及其他输出令牌的隐藏掩码信息。最后,我们添加了一个新的三层MLP,从更新的HQ-Output token生成动态卷积核,然后与融合的HQ-Features进行点积,获得高质量的掩码生成。
- Global-local Fusion for HQ Features
Global-local Fusion相当于对image encoder的浅层特征和深层特征做了融合(这里是提高精细度的最重要的部分,因为浅层特征包含分割边缘的细节特征,而原始的SAM只利用了深层特征,那么最终的分割结果就不会精细)。融合后的特征会和mask decoder中的mask feature进行相加,形成一个256x256的HQ-Features特征。
SAM的ViT编码器的早期层(early layer)为局部特征,大小为64×64,在ViT编码器的第一个全局关注块之后提取特征,例如对于基于ViT- large版本的SAM,是第6个块输出(共24块);最后一层(final layer)为全局特征,具有更多的全局图像上下文信息
SAM的掩码解码器(大小为256×256)中的mask feature包含强掩码形状信息,该特征也为Output token所共享
通过转置卷积将早期层和最终层编码器特征上采样到空间大小256×256。然后,经过简单的卷积处理,将这三种类型的特征相加
Updated HQ-Output Token其实代表的是学习后的HQ-Output Token,也就是一开始输入的那个Token。经过多层的MLP后和HQ-Features进行点乘,得到最终的精细分割结果。
这里需要注意的是,作者在SAM的基础上添加了一个Output Token,也就是说原来的输出也会存在,所以输出的分割结果中既有精细的分割结果,也有粗糙的分割结果。
训练补充
在训练期间,固定了整个预训练的SAM参数,可学习的参数仅包括HQ-Output Token,其相关的三层MLP和用于HQ-Features融合的三个简单卷积,并且只允许HQ-Output token及其相关的三层mlp被训练来纠正SAM的Output token的掩码错误
组成了一个新的数据集,称为HQSeg-44K,它包含44K极细粒度的图像掩码注释(是由现有的6个图像数据集与高精度的掩码注释合并而成的),HQ-SAM仅在HQSeg-44K上进行训练。
HQ-SAM可以在8个RTX 3090 gpu上仅需4小时即可完成训练

基于ViT-L的SAM与HQ-SAM的训练与推理比较。HQ-SAM给SAM带来的额外计算负担可以忽略不计,模型参数增加不到0.5%,速度达到原来的96%。SAM-L在128个A100 gpu上进行了18万次迭代训练。
基于SAM-L,我们只需要在8个RTX3090 gpu上训练我们的HQ-SAM 4小时。
实验
对于训练,使用一个新的数据集,HQSeg-44K,它包含44K极细粒度的图像掩码注释(现有的6个图像数据集与高精度的掩码注释合并而成的)
为了全面评估HQ-SAM的分割性能,我们在广泛的数据集上进行了实验,包括四个极细粒度的分割数据集:DIS(验证集)、ThinObject-5K(测试集)、COIFT和HR-SOD。此外,我们还对各种基于图像/视频的分割任务在零镜头设置下的流行和具有挑战性的基准进行了实验,如COCO, UVO, LVIS, HQ-YTVIS和BIG
-
与SAM比较
Tab9:对SAM和HQ-SAM在各种主干(包括ViT-B、ViT-L和ViT-H)上的性能进行了全面比较。对比不仅包括四个HQ数据集和COCO验证集的数值结果,还包括模型大小/速度/内存。
HQ-SAM确实在较细的物体或边缘上分割较好

SAM和HQ-SAM在各种ViT主干网上。对于COCO数据集,我们使用在COCO数据集上训练的SOTA检测器FocalNet-DINO作为我们的框提示生成器。
-
消融实验
Tab2:关于高质量输出token效果的消融实验
Tab3:关于全局-局部融合的效果的消融实验
Tab4:将有效的token自适应策略与添加额外的后细化网络和模型微调进行了比较。比较的方案包括:添加上下文token,额外后期细化,直接微调SAM的掩码解码器以及仅微调其输出token用于掩码预测。
Fig3:比较了SAM和HQ-SAM从宽松到严格的BIoU阈值,zero-shot设置下在两个数据集上的召回率比较,BIoU阈值从宽松到严格。当我们从宽松的BIoU阈值0.5变化到非常严格的阈值0.9时,SAM和我们的HQ-SAM之间的性能差距显着增加,表明HQ-SAM在预测非常准确的分割掩码方面的优势

HQ-Output标记在四种极细粒度分割数据集上的消融研究。采用由其GT掩码转换而成的框作为框提示符输入。默认情况下,通过计算全GT掩码损失来训练HQ Output-Token的预测掩码。
(mBIoU:边界指标)

HQ-Features源的消融研究。Early-layer表示ViT编码器的第一个全局关注块之后的特征,final-layer表示最后一个ViT块的输出。四个HQ数据集分别是DIS (val)、ThinObject-5K (test)、COIFT和HR-SOD。

与模型微调或额外后微调的比较。对于COCO数据集,我们使用在COCO数据集上训练的SOTA检测器FocalNet-DINO作为我们的框提示生成器

zero-shot设置下COIFT与HRSOD召回率比较,BIoU阈值从宽松到严格。当我们从宽松的BIoU阈值0.5变化到非常严格的阈值0.9时,SAM和我们的HQ-SAM之间的性能差距显着增加,表明HQ-SAM在预测非常准确的分割掩码方面的优势
-
zero-shot能力比较
Tab5:SAM和HQ-SAM在基于UVO的zero-shot open-world实例分割结果比较
Tab6:使用不同类型的输入提示,在高质量BIG基准测试集上的zero-shot分割结果对比
Tab7:通过COCO和LVIS的训练检测器生成的box提示,分别在COCO和LVIS基准上对SAM和HQ-SAM的zero-shot实例分割结果的比较
Fig4:将HQ-SAM与SAM在zero-shot transfer零样本泛化设置下进行了定性比较
Fig5:在COIFT (zero-shot)和DIS val集合上,将HQ-SAM与具有不同输入点数量的SAM进行了比较,HQ-SAM在不同点数下的性能都优于SAM
Tab8:在精确标注的HQ-YTVIS基准上对视频实例分割结果进行了比较

基于UVO的zero-shot open-world实例分割结果比较。我们使用在COCO数据集上训练的FocalNet-DINO作为我们的框提示生成器。* strict表示阈值较紧的边界区域。

使用不同类型的输入提示,在高质量BIG基准测试集上的zero-shot分割结果对比。我们使用PSPNet来生成粗掩码提示符。

COCO和LVISv1上zero-shot实例分割结果的比较。对于COCO数据集,我们使用在COCO上训练的FocalNet-DINO检测器。对于LVIS,我们采用在LVIS数据集上训练的ViTDet-H作为框提示符生成器。对于SAM,我们使用viT主干和框提示符。我们在保持原始SAM的zero-shot分割能力的同时,提高了边界区域的掩模质量。

在相同的红框或点提示下,在zero-shot设定下,SAM(上一行)与HQ-SAM(下一行)的视觉结果比较。HQ-SAM产生更详细的保存结果,也解决了掩模错误与破洞。

交互式分割结果在COIFT (zero-shot)和DIS val集合上使用不同数量的输入点进行比较。HQ-SAM在不同点数下的性能都优于SAM,且相对改进更明显,提示模糊性更少。

非常精确标记的HQ-YTVIS基准测试集上的zero-shot视频实例分割比较。我们在YTVIS上使用预训练的基于Swin-L的Mask2Fromer作为框提示输入,同时重用其对象关联预测
总结
- 原文conclusion
我们提出了HQ-SAM,这是第一个高质量的zero-shot分割模型,通过在原始SAM中引入可忽略不计的开销。我们在HQ-SAM中提出了一个轻量级的高质量输出Token来取代原始SAM的输出令牌,以实现高质量的掩码预测。在仅训练了44K个高精度掩模后,HQ-SAM显著提高了SAM的掩模预测质量,SAM训练了11亿个掩模。zero-shot transfer评估在图像和视频任务的7个分割基准上进行,跨越不同的对象和场景。我们的研究为如何以数据高效和计算负担得起的方式利用和扩展类似sam的基础分割模型提供了及时的见解。
- 一些看法:
可以用来生成更精确的数据,但是因为保留了原始的SAM,在落地部署仍然存在模型较大的问题。
Appendix
6.1节,介绍了HQ-SAM的额外实验分析,包括在图像和视频基准上与SAM进行更多的zero-shot transfer比较,如YTVIS和DAVIS。
6.2节,我们描述了方法实现的更多细节,包括训练和推理。
6.3节,我们提供了用于训练HQ-SAM的构建HQSeg-44K数据集的进一步细节。
6.4节,我们展示了我们的HQ-SAM和SAM在COCO、DIS-test、hrsod、NDD20、DAVIS和YTVIS上的广泛视觉结果比较。(Fig6-Fig11)
Tab9:对SAM和HQ-SAM在各种主干(包括ViT-B、ViT-L和ViT-H)上的性能进行了全面比较。对比不仅包括四个HQ数据集和COCO验证集的数值结果,还包括模型大小/速度/内存。
Tab10:将高效token适应策略与最近的Adapter Tuning进行了比较
Tab11:在HQ-YTVIS 2019验证集上对zero-shot视频实例分割结果进行对比分析
Tab12:HQ-SAM和SAM在zero-shot transfer模式下的DAVIS验证集上的视频目标分割结果的比较
Tab13:通过向输入GT框提示添加各种尺度的噪声来比较HQ-SAM和SAM
Tab14:合成的新训练数据集HQSeg-44K的更多细节
Tab15:通过将HQ-SAM训练与SA-1B中的44K随机采样图像和掩码进行比较,展示了使用HQSeg-44K的优势
Fig6-Fig11:HQ-SAM和SAM广泛视觉结果比较展示

SAM和HQ-SAM在各种ViT主干网上。对于COCO数据集,我们使用在COCO数据集上训练的SOTA检测器FocalNet-DINO作为我们的框提示生成器。

使用基于ViT-L的SAM编码器与适配器调优的比较。对于COCO数据集,我们使用在COCO数据集上训练的SOTA检测器FocalNet-DINO作为我们的框提示生成器

基于ViT-L的SAM在YouTubeVIS 2019验证集和HQ-YTVIS测试集上的结果。我们采用在YouTubeVIS 2019数据集上训练的SOTA检测器Mask2Former作为我们的视频框提示生成器,同时重用其对象关联预测

基于ViT-L的SAM在DAVIS 2017验证集上的结果。我们采用SOTA模型XMem作为视频框提示生成器,同时重用其对象关联预测。

在GT框提示输入中加入不同噪声水平对四种HQ数据集的分割精度进行比较。

HQ-Seg-44k的数据组成

训练数据集的比较。对于使用基于vvi - l的SAM的COCO数据集,我们使用在COCO数据集上训练的SOTA检测器FocalNet-DINO作为我们的框提示生成器