
虽然RAG提供了一种方式来给大型语言模型提供额外的信息,但还有另一种叫做微调(fine-tuning)的技术,也是给它更多信息的一种方式。特别是,如果你有的上下文比大型语言模型的输入长度或上下文窗口长度更大,那么微调提供了另一种方式让大型语言模型吸收这些信息。微调也被证明对于使大型语言模型以特定的风格输出文本非常有用。但这种实际实现比RAG难一些。
我们来看看。假设你有一个像之前描述的那样,从互联网上找到的句子,比如"我最喜欢的食物是奶油奶酪百吉饼",这样的句子来训练的大型语言模型。那么它可能已经从数千亿个单词中学习,甚至可能超过一万亿个单词,来预测下一个单词。这样的大型语言模型将学会生成听起来像互联网上的文本。这个过程通常被称为预训练。
现在,假设我想修改大型语言模型,使其对所有事情都持绝对积极和乐观的态度。有一种叫做微调的技术,我们可以用它让大型语言模型进行更多学习,以改变其输出,例如在这个例子中,变得更加积极和乐观。要微调大型语言模型,我们需要提供一系列具有积极乐观态度的句子或文本,例如“这个巧克力蛋糕真棒”或“这本小说真令人兴奋”。给定这样的文本,你可以创建额外的数据集,使用"这个巧克力蛋糕真棒",你将给出"what",接下来的单词,它会尝试预测"a",“what a”,接下来的单词是"wonderful",“what a wonderful chocolate”,依此类推。
事实证明,如果你拿一个已经在数千亿个单词上预训练的大型语言模型,并在额外的,比如说1万个单词或更多的相对较小的数据集上进行微调,可能是10万个单词,如果你有更多的数据,甚至100万个单词,如果你有更多的数据,微调这个相对较小的数据集可以改变大型语言模型的输出,使之具有积极、乐观的态度。现在,或许让大型语言模型持有绝对积极的态度并不是一个有用的应用,但微调在许多真实应用中被使用。

微调在一类应用中非常有用,那就是当任务不容易用prompt提示定义时。例如,如果你想用大型语言模型来总结客户服务电话,一个通用的大型语言模型可能会看一个电话记录并将其总结为“客户告诉代理关于显示器的问题”。

但如果你经营一个客户呼叫中心,你可能希望它生成关于对话内容的具体信息。比如MK401-27KX由客户5402报告损坏等等。如果你创建了一个可能只有几百个人工专家编写的总结的数据集,并让一个已经从互联网上数千亿个单词中学到了很多通用知识的大型语言模型进行额外的微调。但如果你额外地对它进行微调,使用像“这个巧克力蛋糕真棒”这样的句子,或者有特定风格的文本,那么就会改变大型语言模型的写作能力,使其符合你想要的风格。这种特定风格的总结实际上不容易在文本提示中定义。也许你可以做到,但微调将是一种非常精确的方式来告诉大型语言模型你想要什么样的总结。
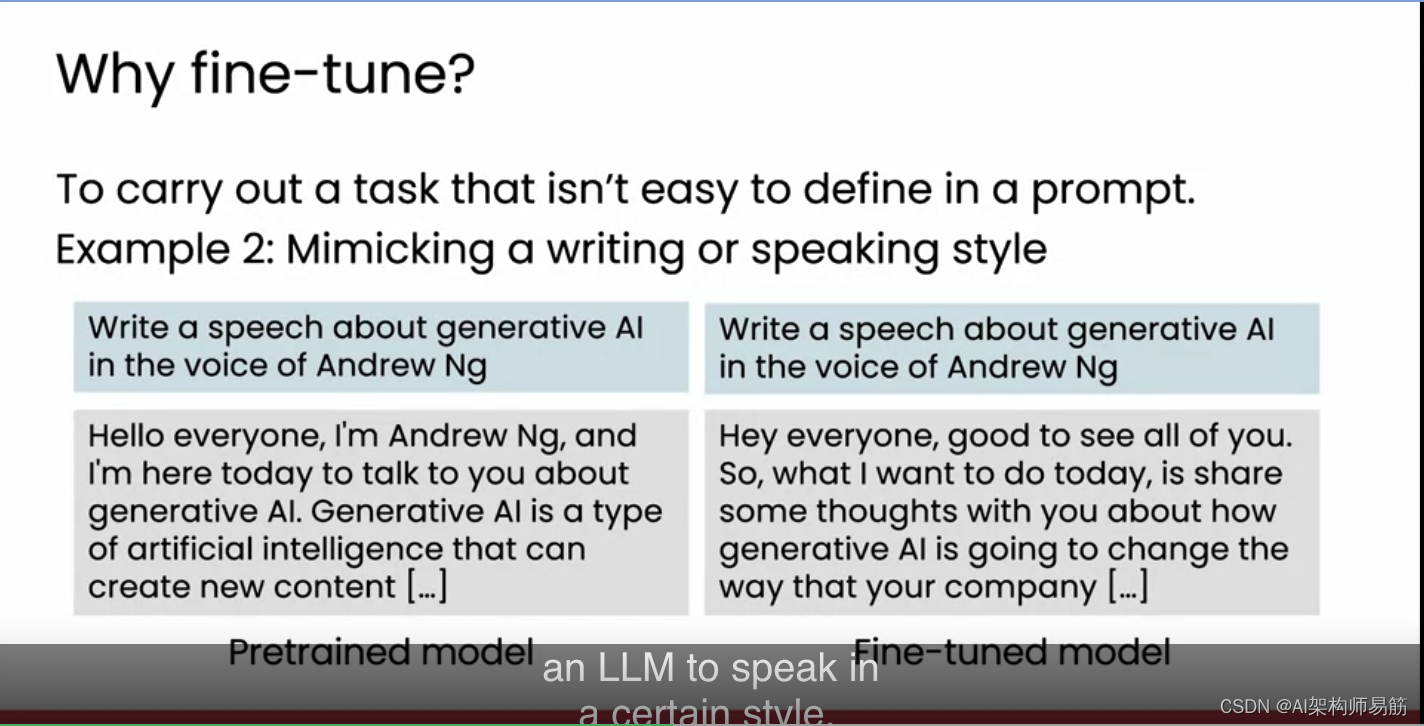
当任务不容易在提示中定义时,另一个例子是模仿特定的写作或说话风格。所以,和我一起工作的Tommy Nelson,实际上只是为了好玩,试图让一个大型语言模型听起来像我,但事实证明,大多数人的说话方式并不容易在提示中描述。你如何给别人清晰的指示来模仿我?所以,如果你提示一个通用的大型语言模型并要求它听起来像我,你会得到这样的文本,我认为它并不太像我。但如果你拿走我实际谈话的很多转录,并让一个大型语言模型被微调来真正地听起来像我,通过学习我实际的话语,那么让它写一些听起来像我的东西会得到这样的文本,这听起来更像是我会说的。但因为模仿特定人的写作或说话风格很难通过提示来完成,因为很难通过写作文本指令来描述特定人的风格,微调变成了一种更有效的方式来让大型语言模型以特定风格说话。如果你正在构建一个人工角色,比如卡通人物,微调也可以是让大型语言模型以特定风格说话的一种方式。

除了容易定义的提示之外,微调的第二大类应用是帮助大型语言模型获得某一领域的知识。例如,如果你想让一个大型语言模型能够阅读和处理医疗记录,这就是医生写给病人的医疗记录可能看起来的样子。这真的不是正常的英语。Pt是患者,c/o是抱怨,SOB是呼吸急促,DOE是活动时呼吸困难,PE是体格检查的结果等等。治疗是随访主治医师,STAT胸部X光,根据需要在氧气上进行治疗。但这真的不是正常的英语,如果你拿一个在正常英语上训练的大型语言模型,它不会很擅长处理这样的文本。如果你对一个大型语言模型进行医疗记录的微调,那么它就会更好地吸收有关医疗记录听起来的知识。然后你可以在其上构建其他应用程序,以更好地理解医疗记录或法律文件。

这里是律师为律师写的法律文件,非律师很难阅读。许可方根据第2(a)(iii)条给予被许可方非专有权利等等,15天内。我不知道你怎么想。我在我的日常生活中不使用hereof这个词。但这就是法律文件听起来的样子。如果你想让你的大型语言模型获得有关如何阅读和理解法律文件的知识,那么将大型语言模型(LLM)微调至法律文件将有助于其获得这方面的知识。

同样,对财务文件也是如此。将大型语言模型微调到一大套财务文件上,将有助于它更好地掌握财务知识,并提高涉及处理这类文件的应用的性能。

最后,微调大型语言模型的另一个原因是让更小的模型执行可能之前需要更大模型的任务。我们将在本周晚些时候讨论选择更大模型与更小模型的优缺点。但对于一些需要大量知识或复杂推理的大型语言模型应用,你可能会使用一个相对较大的模型,比如拥有超过1000亿参数的模型。但如果使用这样的模型,可能会有相对较高的延迟。这意味着,在你发出提示后,你可能需要等待一段时间才能得到回应。
如果你要在自己的电脑上部署这种模型,可能会相当昂贵。即使我们在之前的视频中说过这些模型并不那么昂贵,也许你希望它更便宜。这是因为一个1000亿参数的模型可能需要特殊的计算机,如GPU服务器或其他非常快的计算机来运行。你可能很难在普通的笔记本电脑或PC上运行这样大的模型,更不用说在智能手机上了。
但如果你能让你的应用程序在一个更小的模型上运行,比如说10亿参数的模型,那么这个模型大小的范围就会更容易在笔记本电脑、PC或手机上运行。例如,如果你想要的是将餐厅评论分类为正面或负面情感,这是一个足够简单的任务,你可能不需要一个100或2000亿参数的模型来运行。但也许一个10亿参数的模型就足够好了,甚至可能更小。
但这些较小的模型并不像真正大的模型那么聪明或优秀。这就是为什么如果你拿一个小模型,然后对它进行微调,就像这里展示的数据集那样,不仅仅是三个例子,而是也许几百个或者如果你有那么多数据的话,甚至1000个例子,那么你就可以让一个小模型,比如说10亿参数的模型,在这样的任务上表现得非常好。
总而言之,微调为你提供了除了RAG之外的另一种技术来帮助提高大型语言模型的能力。你可能会用它来处理难以在提示中明确指定的任务。比如,如果你想要
- 输出某种风格的文本,
- 希望大型语言模型获得某种知识,如关于医疗记录的知识,
- 想要获得一个更小、更便宜的大型语言模型来执行可能原本需要更大型大型语言模型的任务。
事实证明,RAG和微调都相对便宜易实施。RAG只是你提示的修改,微调,你可能可以以几十美元甚至几百美元开始,这取决于你想要微调的数据量。还有一种技术,自己训练自己的模型,目前来说非常昂贵,几乎没有人尝试这样做,通常是相对较大的公司,为了完整性,我们来看下一个视频,了解预训练的内容。
参考
https://www.coursera.org/learn/generative-ai-for-everyone/lecture/EIX6K/fine-tuning