1、简介
https://alphacephei.com/vosk/index.zh.html
Vosk 是一个语音识别工具包。

1.1 vosk简介
- 支持二十+种语言 - 中文,英语,印度英语,德语,法语,西班牙语,葡萄牙语,俄语,土耳其语,越南语,意大利语,荷兰人,加泰罗尼亚语,阿拉伯, 希腊语, 波斯语, 菲律宾语,乌克兰语, 哈萨克语, 瑞典语, 日语, 世界语, 印地语, 捷克语, 波兰语, 乌兹别克语, 韩国语
- 移动设备上脱机工作-Raspberry Pi,Android,iOS
- 使用简单的 pip3 install vosk 安装
- 每种语言的手提式模型只有是50Mb, 但还有更大的服务器模型可用
- 提供流媒体API,以提供最佳用户体验(与流行的语音识别python包不同)
- 还有用于不同编程语言的包装器-java / csharp / javascript等
- 可以快速重新配置词汇以实现最佳准确性
- 支持说话人识别
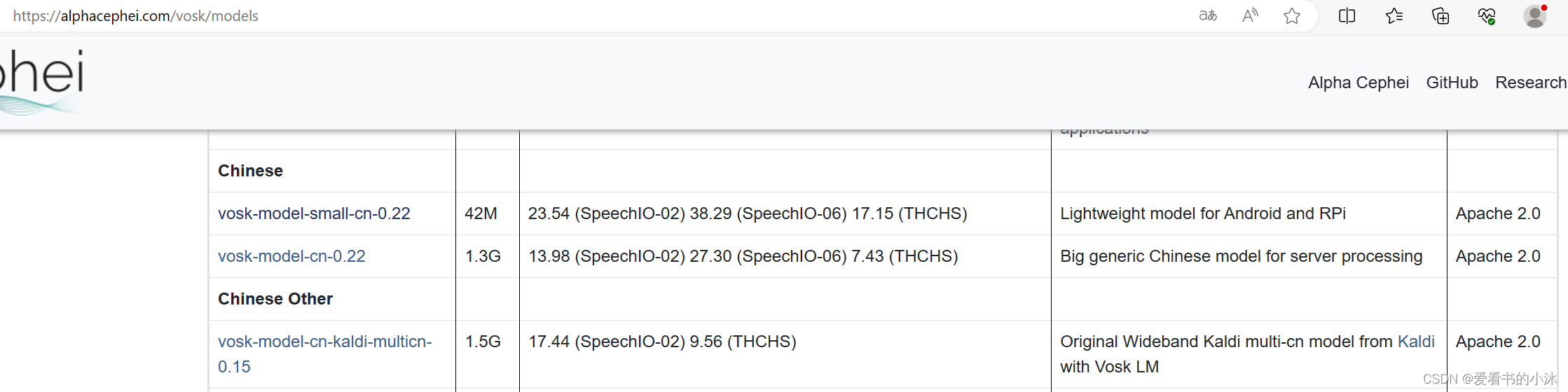
1.2 vosk模型
https://alphacephei.com/vosk/models
有两种类型的模型 - 大模型和小模型,非常适合 移动应用程序上的一些有限任务。它们可以在智能手机上运行, 树莓派的。还建议将它们用于桌面应用程序。小 模型的大小通常约为 50Mb,需要大约 300Mb 的内存 在运行时。大模型用于 服务器。大型型号需要高达 16Gb 的内存,因为它们应用了先进的 人工智能算法。
# 下载模型文件:
wget -c https://alphacephei.com/vosk/models/vosk-model-small-cn-0.22.zip
wget -c https://alphacephei.com/vosk/models/vosk-model-cn-0.15.zip
wget -c https://alphacephei.com/vosk/models/vosk-model-cn-kaldi-multicn-0.15.zip
1.3 vosk服务
一个基于Vosk-API的非常简单的服务器。
不同的协议有四种实现 - websocket、grpc、mqtt、webrtc。
启动服务器:
#获取docker镜像:
docker pull alphacep/kaldi-cn:latest
#启动服务:
docker run -d -p 2700:2700 alphacep/kaldi-cn:latest
若要测试服务器,请运行示例脚本:
git clone https://github.com/alphacep/vosk-server
cd vosk-server/websocket
./test.py test.wav
使用麦克风进行测试,您需要安装 sounddevice pip 包:
pip3 install sounddevice
要使用麦克风进行测试,请运行:

./test_microphone.py -u ws://localhost:2700
使用docker方式启动服务,比较简单,但下载docker包比较耗时,如果已经下载好vosk-server代码及对应的模型文件,可以直接通过python代码启动vosk-server提供asr服务。
#1、下载vosk-server代码
git clone https://github.com/alphacep/vosk-server
#2、下载模型文件
wget -c https://alphacephei.com/vosk/models/vosk-model-cn-0.15.zip
#3、启动vosk服务
python asr_server.py vosk-model-cn-0.15
2、安装
确保您拥有最新的 pip 和 python3 版本:
Python版本:3.5-3.9
pip 版本:20.3 及更高版本。
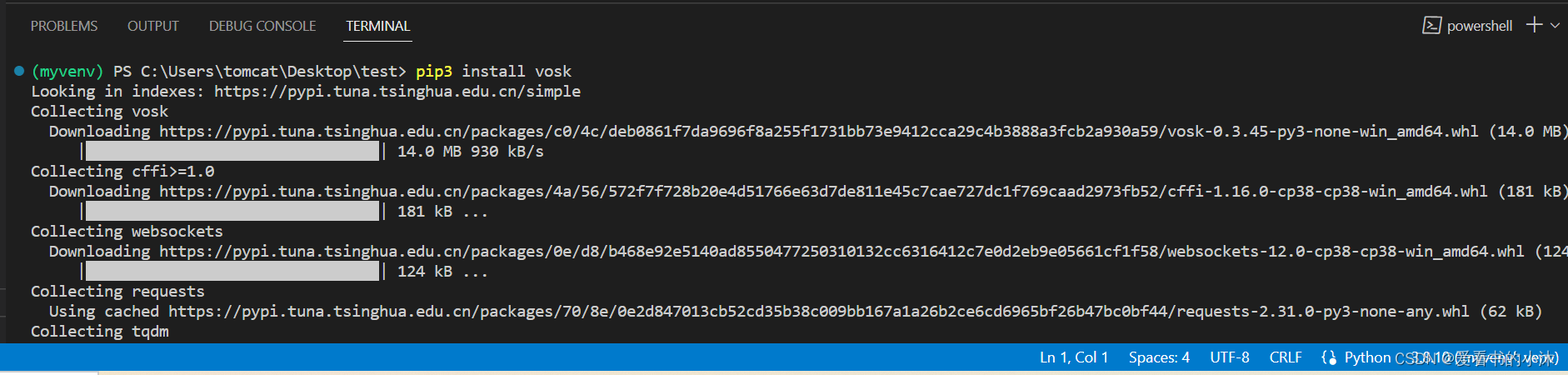
pip3 install vosk
# pip3 install vosk -i https://pypi.doubanio.com/simple
# pip3 install https://github.com/alphacep/vosk-api/releases/download/v0.3.42/vosk-0.3.42-py3-none-linux_riscv64.whl
python3 --version
pip3 --version
pip3 -v install vosk
# 验证ffmpeg是否已安装,调用命令行(windows+R输入cmd)/ Ubuntu终端
$ ffmpeg –version

3、测试
3.1 命令行测试
vosk-transcriber -i test.mp4 -o test.txt
vosk-transcriber -i test.mp4 -t srt -o test.srt
vosk-transcriber -l fr -i test.m4a -t srt -o test.srt
vosk-transcriber --list-languages
# windows
$ cd xxx/xxx
# 查看help命令
$ vosk-transcriber -h
# 列举当前的语言
$ vosk-transcriber --list-languages
# 方式一 :中文语音转汉字
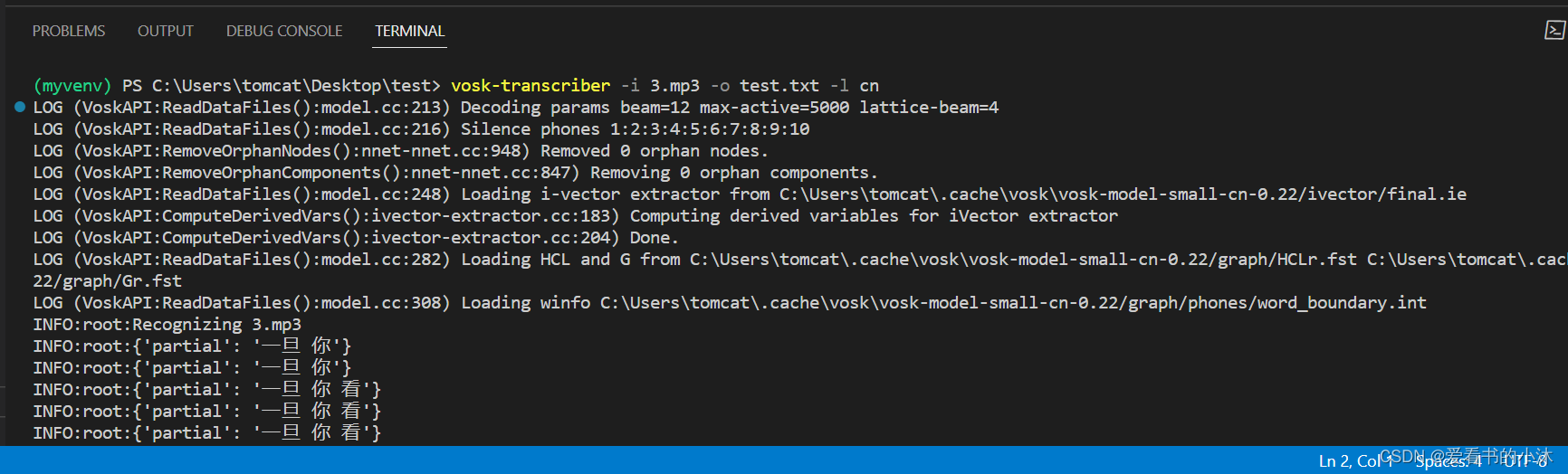
$ vosk-transcriber -i xxx.mp3 -o xxx.txt -l cn
# 方式二 :中文语音转汉字, 也可以去网站下载模型后直接指定模型路径
$ vosk-transcriber -i xxx.mp3 -o xxx.txt -m 解压后的文件夹路径

3.2 代码测试
若要运行 python 示例,请克隆 vosk-api 并运行以下命令:
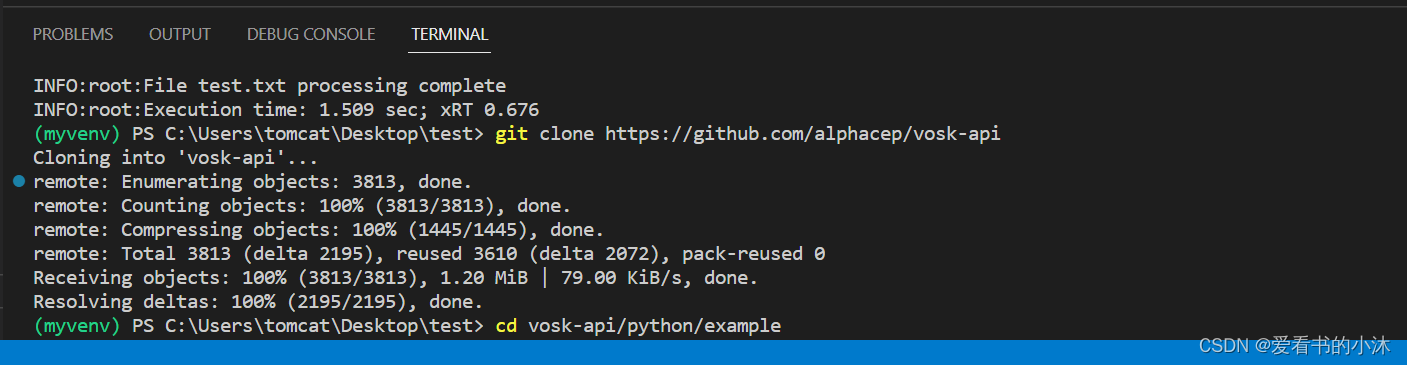
git clone https://github.com/alphacep/vosk-api
cd vosk-api/python/example
python3 ./test_simple.py test.wav
使用您自己的音频文件时,请确保其格式正确 - PCM 16kHz 16bit 单声道。否则,如果您安装了 ffmpeg,则可以使用 ,它为您进行转换。
结语
如果您觉得该方法或代码有一点点用处,可以给作者点个赞,或打赏杯咖啡;╮( ̄▽ ̄)╭
如果您感觉方法或代码不咋地//(ㄒoㄒ)//,就在评论处留言,作者继续改进;o_O???
如果您需要相关功能的代码定制化开发,可以留言私信作者;(✿◡‿◡)
感谢各位大佬童鞋们的支持!( ´ ▽´ )ノ ( ´ ▽´)っ!!!