一、RNN
RNN(Recurrent Neural Network),中文称作循环神经网络它一般以序列数据为输入通过网络内部的结构设计有效捕捉序列之间的关系特征,一般也是以序列形式进行输出。
传统神经网络(包括CNN),输入和输出都是互相独立的。但有些任务,后续的输出和之前的内容是相关的,例如:我是中国人,我的母语是____。这是一道填空题,需要依赖之前的输入。RNN跟传统神经网络最大的区别在于每次都会将前一次的输出结果,带到下一次的隐藏层中,一起训练。
RNN单层结构:
基本循环神经网络结构:一个输入层、一个隐藏层和一个输出层。

以时间步对RNN进行展开后的单层网络结构:
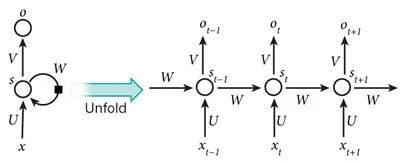
x是输入层的值。s表示隐藏层的值,U是输入层到隐藏层的权重矩阵,O是输出层的值。V是隐藏层到输出层的权重矩阵。循环神经网络的隐藏层的值s不仅仅取决于当前这次的输入x,还取决于上一次隐藏层的值s。权重矩阵W就是隐藏层上一次的值作为这一次的输入的权重。
因为RNN结构能够很好利用序列之间的关系,因此针对自然界具有连续性的输入序列如人类的语言,语音等进行很好的处理,广泛应用于NLP领域的邻项任务,如文本分类、情感分析、意图识别,机器翻译等。
举例:
第一步:用户输入了"What time is it?”我们首先需要对它进行基本的分词,因为RNN是按照顺序工作的,每次只接收一个单词进行处理。
第二步:首先将单词What”输送给RNN,它将产生一个输出O1

第三步:继续将单词“time输送给RNN但此时RNN不仅仅利用“time"来产生输出02,还会使用来自上一层隐层输出01作为输入信息.


最后,将最终的隐层输出05进行处理来解析用户意图

二、RNN分类
这里我们将从两个角度对RNN模型进行分类.第一个角度是输入和输出的结构,第二个角度是RNN的内部构造。
- 输入和输出的结构
N VS N - RNN
N Vs 1- RNN
1 Vs N - RNN
N Vs M - RNN
传统的神经网络,以及CNN,它们存在的一个问题是,只适用于预先设定的大小。通俗一点,就是采用固定的大小的输入并产生固定大小的输出。
而RNN呢?它专注于处理文本,其输入和输出的长度是可变的,比如,一对一,一对多,多对一,多对多,如下图:

- RNN的内部构造
传统RNN
LSTMBi-LSTM
GRU
Bi-GRU
三、传统RNN
传统RNN的内部结构图:

- 它的输入有两部分,分别是h(t-1)以及x(t),代表上一时间步的隐层输出以及此时间步的输入;
- 它们进入RNN结构体后,会”融合"到一起,这种融合我们根据结构解释可知,是将二者进行拼接,形成新的张量[x(t),h(t-1)];
- 之后这个新的张量将通过一个全连接层(线性层),该层使用tanh作为激活函数,最终得到该时间步的输出h(t),
- 它将作为下一个时间步的输入和x(t+1)一起进入结构体以此类推。

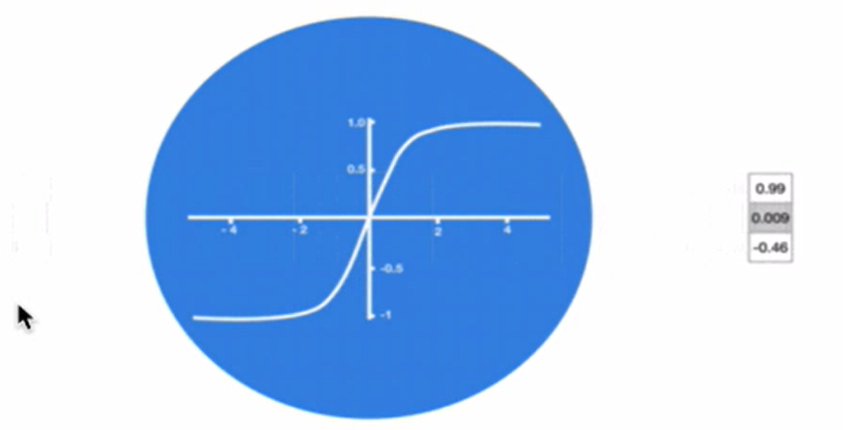
激活函数tanh的作用: 用于帮助调节流经网络的值,tanh函数将值压缩在-1和1之间
3.1 传统RNN优缺点
- 优点
由于内部结构简单,对计算资源要求低,相比之后我们要学习的RNN变体:LSTM和GRU模型参数总量少了很多在短序列任务上性能和效果都表现优异。
- 缺点
传统RNN在解决长序列之间的关联时,通过实践,证明经典RNN表现很差,原因是在进行反向传播的时候,过长的序列导致梯度的计算异常,发生梯度消失或爆炸。
根据反向传播算法和链式法则,梯度的计算可以简化为以下公式:
其中sigmoid的导数值域是固定的,在[0,0.25]之间,而一旦公式中的w也小于1,那么通过这样的公式连乘后,最终的梯度就会变得非常非常小,这种现象称作梯度消失.反之,如果我们人为的增大w的值使其大于1那么连乘够就可能造成梯度过大,称作梯度爆炸.
- 如果在训练过程中发生了梯度消失,权重无法被更新,最终导致训练失败;
- 梯度爆炸所带来的梯度过大,大幅度更新网络参数,在极端情况下,结果会溢出 (NaN值)