本文讲解DAX函数SUMMARIZECOLUMNS基本的原理与用法
前述
国内外关于DAX函数的讲解已很多,但个别函数还是有必要拿出来再讲讲。本文结合MarcoRusso关于SUMMARIZECOLUMNS函数的理论以及自身对其的研究,专门讲解该函数,并分为多个篇章。本篇将讲解其基本原理与用法。
语法
首先是函数的语法:
SUMMARIZECOLUMNS(
<groupBy_columnName>
[, < groupBy_columnName >]…
, [<filterTable>]…[, <name>, <expression>]…
)
其参数定义如下表所示:
| 参数 | 必要 | 可重复 | 描述 |
|---|---|---|---|
| groupBy_ColumnName | ✓ | ✓ | 用于分组的列 |
| filterTable | × | ✓ | 提供筛选上下文的表或表表达式 |
| name | × | ✓ | 添加的新列名称 |
| expression | × | ✓ | 新列的表达式 |
基本原理与用法
先讲一个此函数的典型特征:SUMMARIZECOLUMNS只有筛选上下文,没有行上下文。比如对于如下数据模型:

使用DAX新建表如下:
SUMMARIZECOL_NONMEASURE =
SUMMARIZECOLUMNS (
'DimProductCategory'[ProductCategoryName],
'DimDate'[FiscalMonth]
)
它将根据这两列,单纯地CROSSJOIN成一个笛卡儿积表,也就是两个字段值所有可能的组合,如下:

这就是因为SUMMARIZECOLUMNS本身并未指定主表,两个来自不同表的字段不能产生任何关联,而函数引擎也无法为其生成对应的行上下文。
一旦在函数中引入可选参数filterTable,并指定主表,公式就可以返回数据集中真实存在的非空组合,而非笛卡儿积, 这就是因为SUMMARIZECOLUMNS利用了’FactSales’的行上下文对结果集进行了筛选。
SUMMARIZECOL_NONMEASURE =
SUMMARIZECOLUMNS (
'DimProductCategory'[ProductCategoryName],
'DimDate'[FiscalMonth],
'FactSales'
)
如果引入度量值,SUMMARIZECOLUMNS也可以借用度量值所在表的行上下文对其产生的结果集进行筛选。此外,如果所有的度量值对某一行的计算结果为空,该行将会被排除。
此处,我们引入度量值。DAX新建表如下:
SUMMARIZECOL =
SUMMARIZECOLUMNS (
'DimProductCategory'[ProductCategoryName],
'DimDate'[FiscalMonth],
"SALES", SUM ( 'FactSales'[SalesQuantity] )
)
可得到:
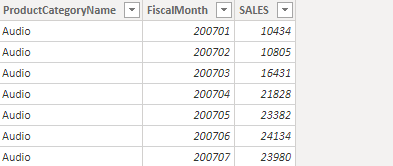
这里公式返回结果的原理为:SUMMARIZECOLUMNS借用了主表的行上下文,对SALES值进行求和计算,并使用[ProductCategoryName]以及[FiscalMonth]对结果进行GroupBy,并过滤SALES为空的行。
如果我们使用SUNMARIZE函数来模拟以上SUMMARIZECOLUMNS的计算,则公式为:
SUMMARIZECOL_SIMULATE =
FILTER (
SUMMARIZE (
CROSSJOIN (
VALUES ( 'DimProductCategory'[ProductCategoryName] ),
VALUES ( 'DimDate'[FiscalMonth] )
),
'DimProductCategory'[ProductCategoryName],
'DimDate'[FiscalMonth],
"SALES", CALCULATE ( SUM ( 'FactSales'[SalesQuantity] ) )
),
NOT ISBLANK ( [SALES] )
)
该公式将返回与上图相同的结果。注意,此公式仅仅是为了便于读者理解其原理,实际使用时,还是推荐你直接使用SUMMARIZECOLUMNS,因为前者执行了三个SE查询,效率低于后者。

有关SUMMARIZECOLUMNS相对于SUMMARIZE的性能优势解析,可参见下篇博客。