更快、更灵活的 Transformer图像去雾网络
本文分享 ICCV 2023 论文MB-TaylorFormer: Multi-branch Efficient Transformer Expanded by Taylor Formula for Image Dehazing,介绍更快、更灵活的 Transformer 图像去雾网络。
-
论文链接:https://arxiv.org/abs/2308.14036
-
代码链接:https://github.com/FVL2020/ICCV-2023-MB-TaylorFormer
Abstract
本文介绍了一种新的多支路线性Transformer网络,称为MB-TaylorFormer,能够有效且高效的进行图像去雾任务。
MB-TaylorFormer有以下几个贡献:
-
基于泰勒展开的线性Transformer网络,对像素间的长距离关系进行建模。通过引入了MSAR模块,以纠正对softmax-attention进行泰勒展开的误差;
-
通过多支路和多尺度结构提取具有多尺度感受野、多层次语义信息和更灵活的感受野形状的Token;
-
更优的性能、更少的计算量和更轻量的网络。
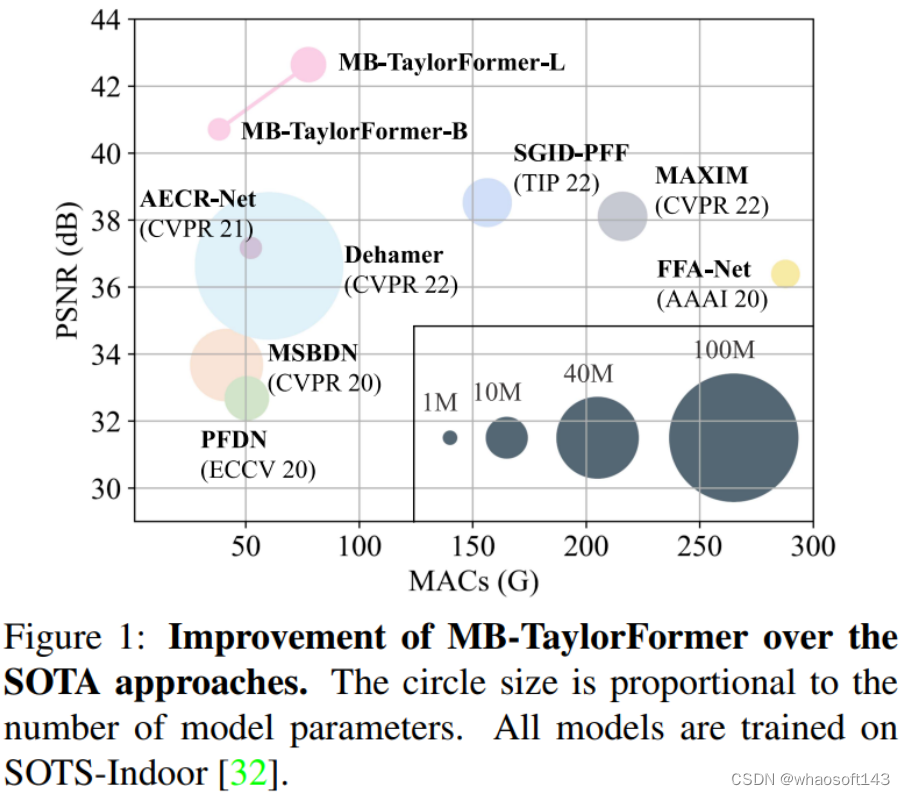
我们在多个去雾数据集(ITS、OTS、O-HAZE、Dense-Haze)上进行了实验。实验结果表明:MB-TaylorFormer以极低的参数量和计算复杂度优于其它SOTA方案。此外,去雨和去雪的实验结果表明MB-TaylorFormer同样有效。
Method
Network Architecture 上图给出了本文所提出的MB-TaylorFormer三个核心模块:多尺度Patch Embedding(图2.b)、Taylor展开的自注意力(图2.c)和MSAR模块(图2.d)。
上图给出了本文所提出的MB-TaylorFormer三个核心模块:多尺度Patch Embedding(图2.b)、Taylor展开的自注意力(图2.c)和MSAR模块(图2.d)。
Multi-scale Patch Embedding
相比NLP领域,视觉Token在尺度上非常灵活。现有的工作在补丁嵌入中采用了固定卷积核大小的卷积,这可能导致视觉Token的单一尺度。为了解决这个问题,我们设计了一个新的多尺度Patch Embedding,具有三个特性:
-
多尺度的感受野
-
多级语义信息
-
灵活的感受野形状。
具体来说,通过设计多个并行的具有不同尺度卷积核的可变形卷积(DCN),我们使Patch Embedding能够生成粗糙和精细的视觉标记,以及具备灵活的表达能力,如下图所示。受到堆叠多层3*3卷积可获得更大感受野的启发,我们堆叠了几个小卷积核的DCN以获得更丰富的采样点。这不仅增加了网络的深度以提供多级语义信息,还有助于减少参数和计算负担。此外,我们还对DCN加入两个小的改动:
-
通过对offset截断使得Token更关注局部。
-
与深度可分离卷积的策略类似,我们提出了深度可分离和可变形卷积(DSDCN),它将 DCN 的各部分分解成Depthwis卷积与Pointwise卷积。

Taylor Expanded Multi-head Self-Attention
对于原始的Transformer的Self-attention表达式,如下所示:
 T-MSA包含以下三个优势:
T-MSA包含以下三个优势:
-
不受限于分窗导致的感受野下降
-
进行全局像素的self-attention,而非通道之间的self-attention
-
相比一般的的核函数方法在数值上更接近Softmax-attention
Multi-scale Attention Refinement
由于忽略泰勒展开余项不可避免的存在误差,而估计 Experiments
Experiments
Main Results
 上表给出了MB-TaylorFormer和其它SOTA 模型的对比,从中可以发现:
上表给出了MB-TaylorFormer和其它SOTA 模型的对比,从中可以发现:
-
在合成数据集(SOTS-Indoor、SOTS-Outdoor)上,MB-TaylroFormer-B分别取得了40.71dB和37.42dB指标,MB-TaylroFormer-L分别取得了42.64dB和38.09dB指标,优于之前的SGID-PFF的38.52dB和30.20dB
-
在真实数据集(O-HAZE和Dense-Haze)上,MB-TaylroFormer-L和MB-TaylroFormer-B分别以0.20dB和0.04dB优于之前的最佳方案Dehamer
-
相比其他方案,MB-TaylorFormer-B具有更少的计算量和参数量,更高的指标。
 上图给出了合成数据集与真实数据上的视觉效果对比,可以看到:MB-TaylorFormer不仅在阴影处更好的恢复了细节,同时也有效的避免了伪影和色偏。
上图给出了合成数据集与真实数据上的视觉效果对比,可以看到:MB-TaylorFormer不仅在阴影处更好的恢复了细节,同时也有效的避免了伪影和色偏。
Ablation Studies
 Study of multi-scale patch embedding and multi-branch structure
Study of multi-scale patch embedding and multi-branch structure
表2研究了不同的Patch Embedding和不同的支路数的影响,以单支路为baseline,我们可以发现: whaosoft aiot http://143ai.com
-
在相似的参数量和浮点数计算量下,多支路优于单支路
-
多尺度感受野(Dilated Conv-P)相比单尺度感受野(Conv-P)带来了+0.35dB的提升
-
多层次语义信息(Conv-S)相比不具有多层次语义信息(Dilated Conv-P)带来了+0.27dB的提升
-
更灵活的感受野形状(DSDCN-S)相比固定的感受野形状(Conv-S)带来了+1.67dB的提升
Effectiveness of multi-scale attention refinement module
表3表明MSAR模块的设计能够以一种极轻量化的设计有效提升TaylorFormer的性能。
Comparison with other linear self-attention modules
表4通过T-MSA和多种不同的线性Transformer的对比,证明了T-MSA在去雾任务上的有效性。
Analysis of approximation errors
为了验证近似误差的影响,我们在在Swin的窗口内对softmax-attention进行泰勒展开,我们发现,对softmax-attention进行更高阶的展开能取得更好的性能,这可能时因为更优的数值近似和attention map具有更高的秩。
注:由于Swin的窗口取8,不存在N>>d的性质,因此,表5实验的MACs计算量不由矩阵乘法结合律得出。
实验室介绍
中山大学智能工程学院的前沿视觉实验室(FVL主页:https://fvl2020.github.io/fvl.github.com/ )由学院金枝副教授建设并维护,实验室目前聚焦在图像/视频质量增强、视频编解码、3D 重建和无接触人体生命体征监测等领域的研究。旨在优化从视频图像的采集、传输到增强以及服务后端应用的完整周期。目标是开发通用的概念和轻量化的方法。