groupvit的监督信号来自于文本,它不依赖于segmentation mask手工标注,而是可以像clip一样利用图像文本对进行无监督训练,从而让模型进行简单的分割任务。在视觉侧之前做无监督分割时使用的方法就是grouping,如果有一些聚类的中心点,然后从这个点开始发散,把附近相似的点逐渐扩充成一个group,其实就相当于一个segmentation mask,是一种自下而上的方式,作者其实相当于重新审视了一下grouping方法,提出了grouping block,让模型在初始学习时能慢慢一点一点的把这个相邻像素点group起来,变成一个segmentation mask,就像下面右侧所示,一开始group token分割的还不太好,经过模型的学习后,等到深层时这些group token分割的就相当不错了。groupvit就是在vit的框架中加入了这个grouping block同时加入了可学习的group tokens。

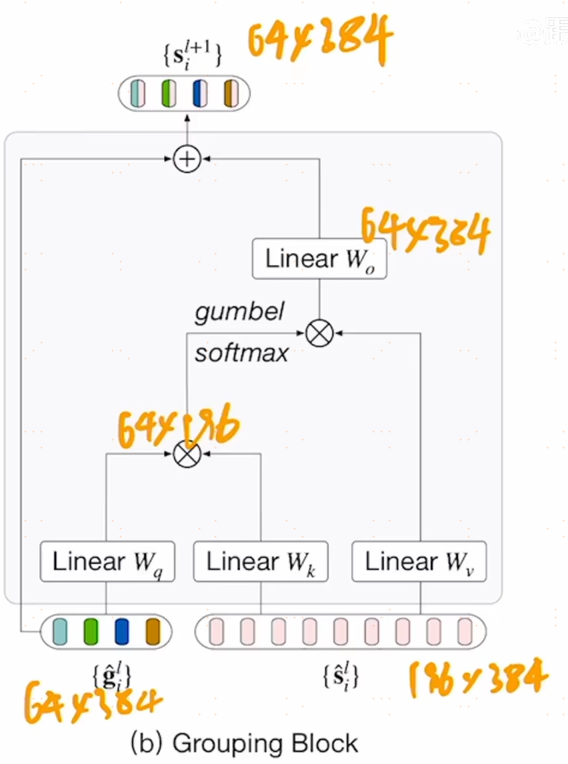
对于图像编码器来说,就是一个vit,从头到尾一共12层,也就是说有12个transformer layers,图像编码器的输入有两部分,一部分是图像的patch embedding,另一部分是可学习的group tokens,在上图中的右侧,图片patch经过linear projection得到patch embedding,维度是196x384,vit small的维度是384,196是14x14,另外一个输入是64x384的group tokens,384是为了保持维度不变,64是希望在刚开始时有尽可能多的聚类中心,因为后续还可以合并,因此设了64,其实这和cls token是一致的,之前vit中用cls token去代表整个图片,现在这里用64个group tokens,每个类别每一小块都有一个特征去表示它,在刚开始时有64个起始点,或者说有64个聚类中心,把那些看起来相似的或者语义接近的像素点都归结到这64个cluster中,在训练中,group token和cls token都是一致的,通过transformer中的self-attention不断的学习到底是那些图像的patch属于哪些token,经过了6层的transformer之后,再接一个grouping block,现在6个transformer layer已经教会了group token,clustering center也学的差不多了,使用grouping block来cluster,合并成更大的group,学到一些更有语义的信息,利用grouping block把之前的图像patch embedding直接assign到这64个group token上,相当于做了一次聚类的分配,一旦分配完成,就有了64个聚类中心,得到了segment token,也就是颜色相间的token,维度是64x384,当然grouping block的另一个好处就是变相的把序列长度降低了,和swin transformer一样,是一个层级式的结构。grouping block其实就是用了类似于self-attention的方式先算了一个相似度矩阵,然后利用相似矩阵帮助原来的image token做一些聚类中心的分配,从而把输入从196x384降到64x384,聚类中心的分配是不可导的,因此用了sumbel softmax变成可导。至此就完成了第一阶段的grouping,把序列从196+64变成了64x384,一般的数据集,一张图片中的种类也不会太多,因此可以把64个聚类中心变成更小的8个,让一些相似类别块在合并,因此又新加了8个group token,就是8x384,看上图是两次新加的group token,作者在第9层transformer layer之后又加了一次grouping block,经过3层transformer layer的学习,新加的8个segment token也学的不错了,这一此的grouping block,就是将64+8的group token分配到8个token上,图像被分成了8块,每块对应一个特征.