大家好,今天我们要来学习阿里巴巴开源的流量控制和熔断降级框架 – Sentinel 。
1、雪崩问题及解决方案
首选我们来了解一下雪崩问题及其解决方案,我们学习这个微服务保护,其实就是为了去应对类似于雪崩问题这样的服务故障。
1.1 什么是雪崩问题?
那什么是雪崩问题呢?我们来看一下这个场景。
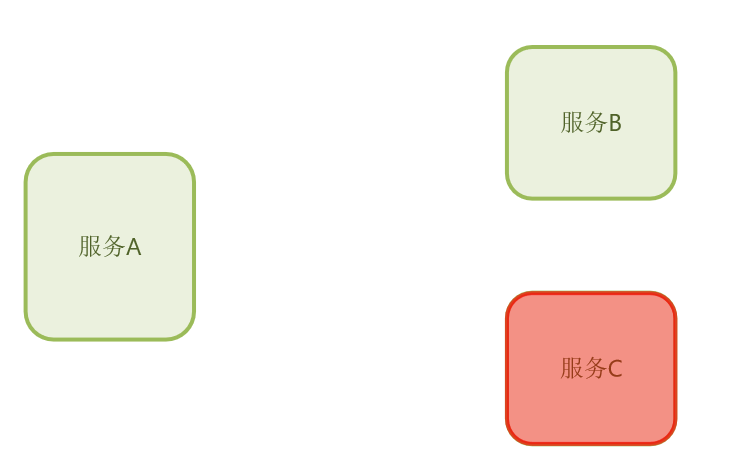
上面是我们微服务里面的部分服务,我们知道微服务里面的业务往会比较复杂,一个业务它可能会依赖多个其他的微服务。
比如,在我们的服务 A 中,有这样的一个业务,它依赖于服务B。

而服务A 里面可能又有可能其他的业务,比如说它依赖于服务D。
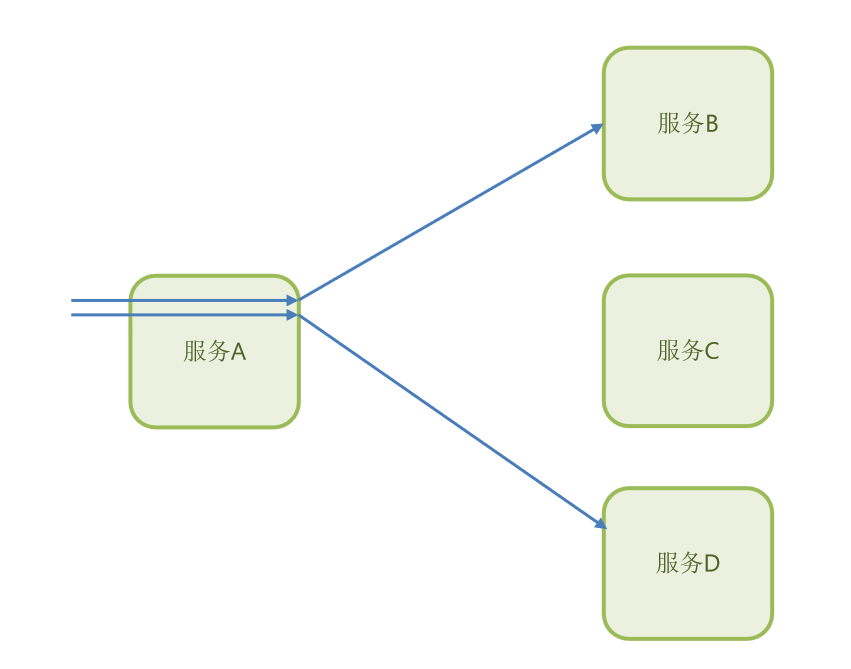
那现在假设说,服务D出现了故障!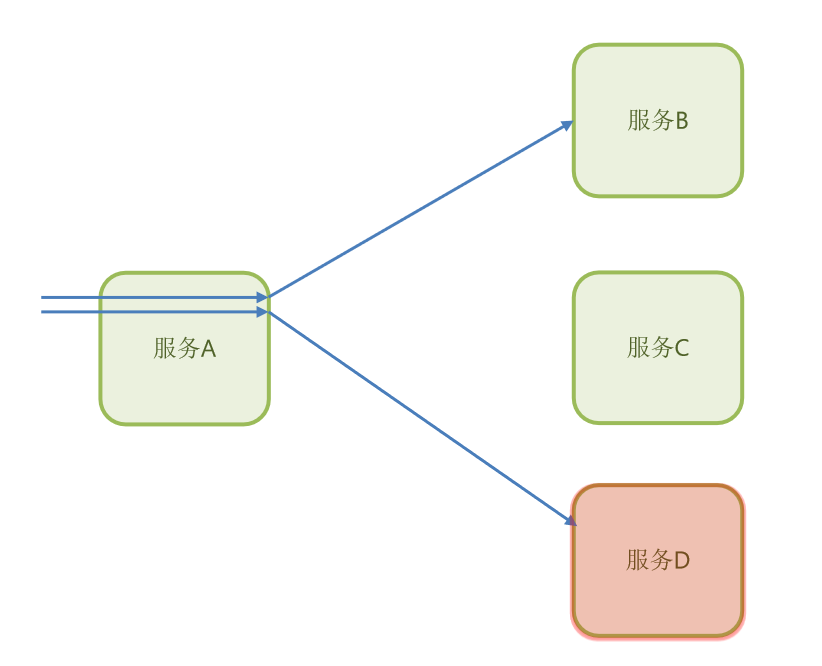
那么我们在服务A内部依赖于服务D的这个业务请求,还能正常访问吗?
显然是不可能的,因为它访问这个服务D就必然要等待服务D的结果,那因为服务D出现了故障,那必然不能返回结果,结果就是它会阻塞在这里。
那这就导致了服务A内部的这个业务是不是也会阻塞在这里?阻塞就会导致它不会释放服务器的连接。
当然了,这个时候,服务A内部依赖的于服务b或c的业务还不受影响,但是你想想看,有第一个依赖服务D这样的业务请求,那也会有第二个和第三个。
假以时日,服务A内部依赖于服务D的这样的业务请求越来越多,而它们都不会释放连接,那后面是不是一定会把服务A所有的连接给占用了?
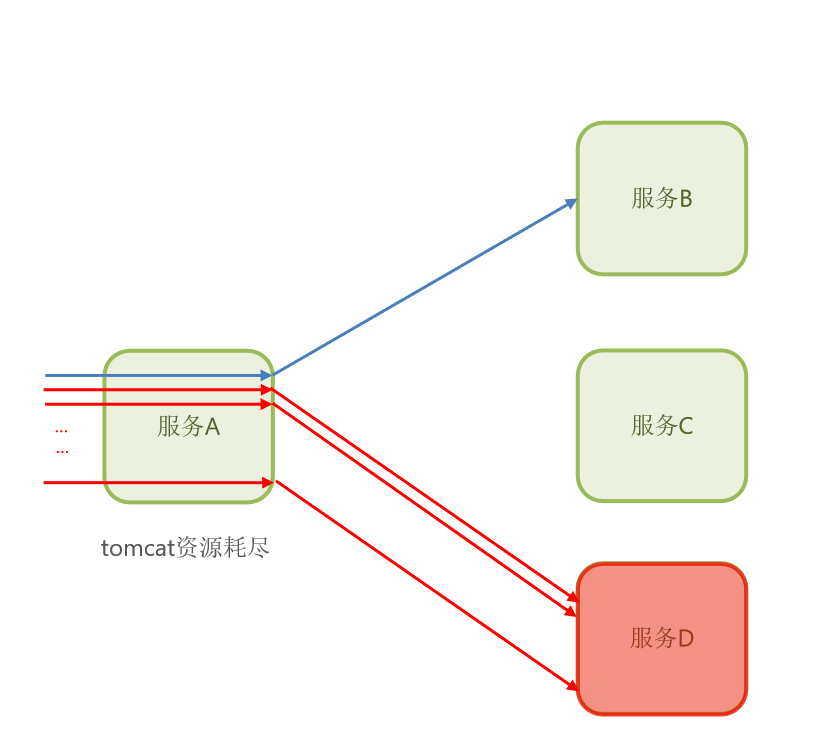
那最后的结果就是tomcat资源耗尽,因为tomcat 资源是有限的嘛,此时再有新的请求进来,哪怕我不是访问服务D的,我依赖服务D的,我是不是也进不来了?
那这下是不是可以认为服务A也出现故障?
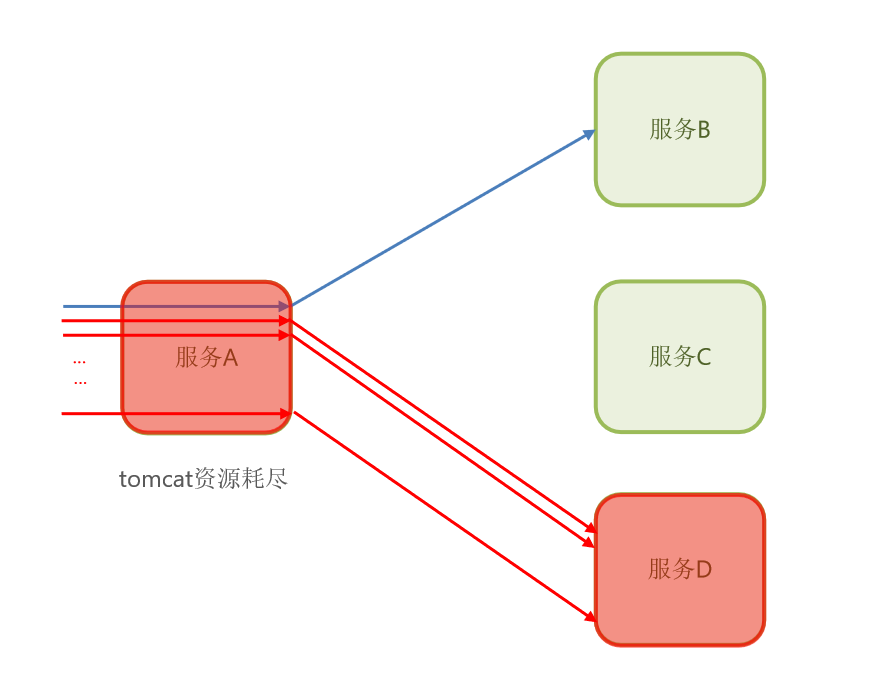
那这不就是因为一个服务导致了什么?
导致了依赖于它的服务也出现了故障。那我们就要知道,在微服务里,这种调用关系可不止这么简单,而且会非常复杂!
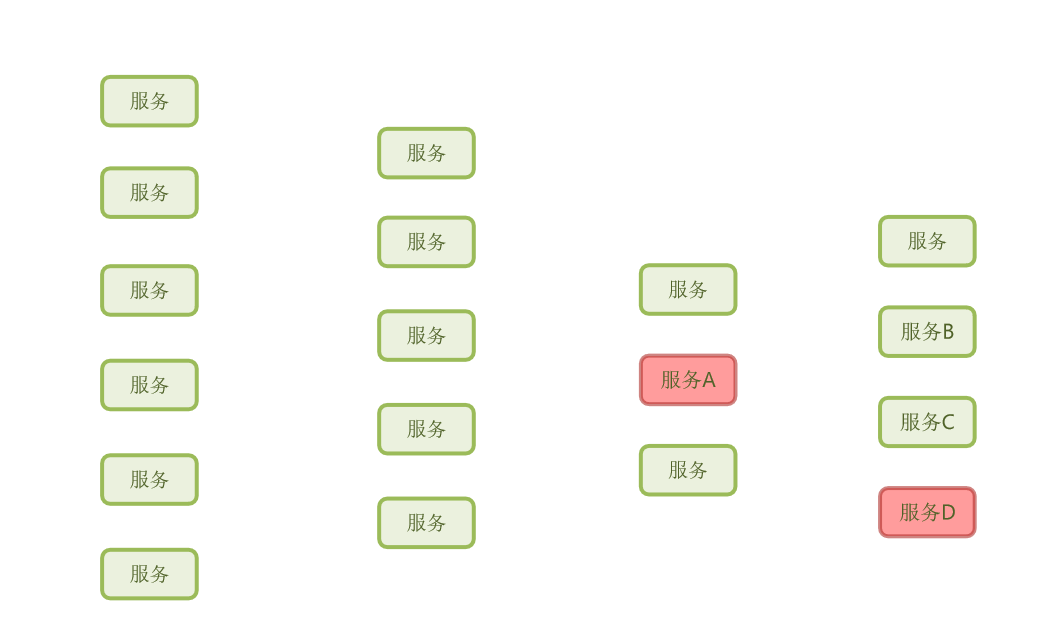
那如果因为服务A因为服务D被拖垮了,那肯定也会有其他的服务也依赖于服务D,最终是不是也会拖垮?
假如说再有其他服务它们依赖于服务A,那么这些依赖于服务A的这些业务是不是也会拖垮?
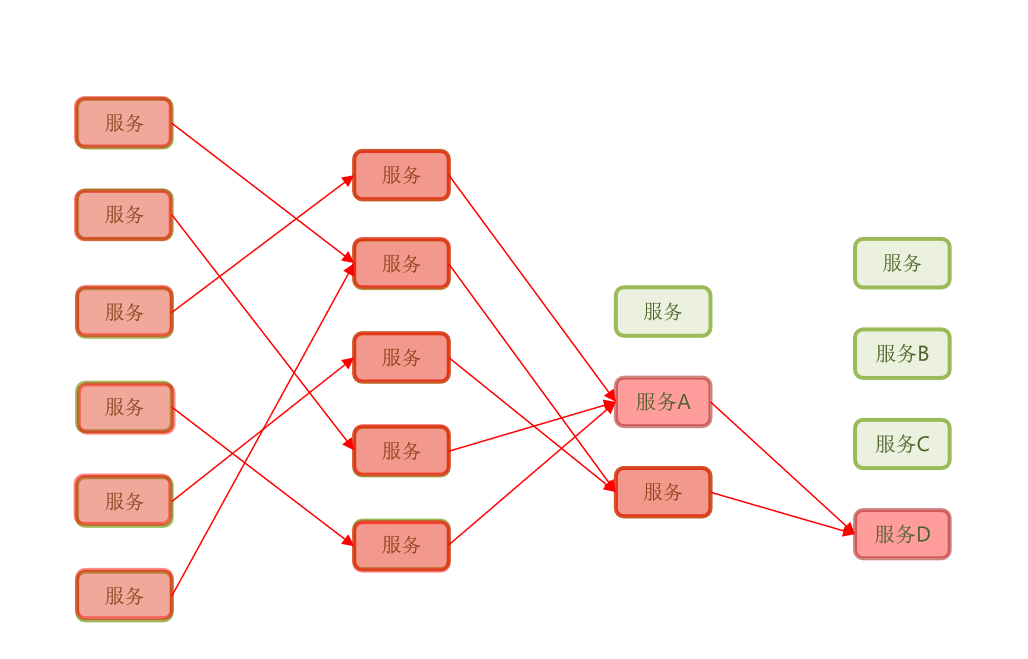
到最后出现故障的服务越来越多,那么整个微服务群都不可用了,这不就是雪崩了吗?
所以什么是雪崩问题?
微服务调用链路中的某个服务故障,引起整个链路中的所有微服务都不可用,这就是雪崩。
这个非常恐怖的呀,所以,在微服务里边,雪崩问题是一个必须要解决的问题!
那么用什么来解决呢?
1.2 雪崩问题解决方案
解决雪崩问题的常见方案有四种:
1.2.1 超时处理
设定超时时间,请求超过一定时间没有响应就返回错误信息,不会无休止等待。
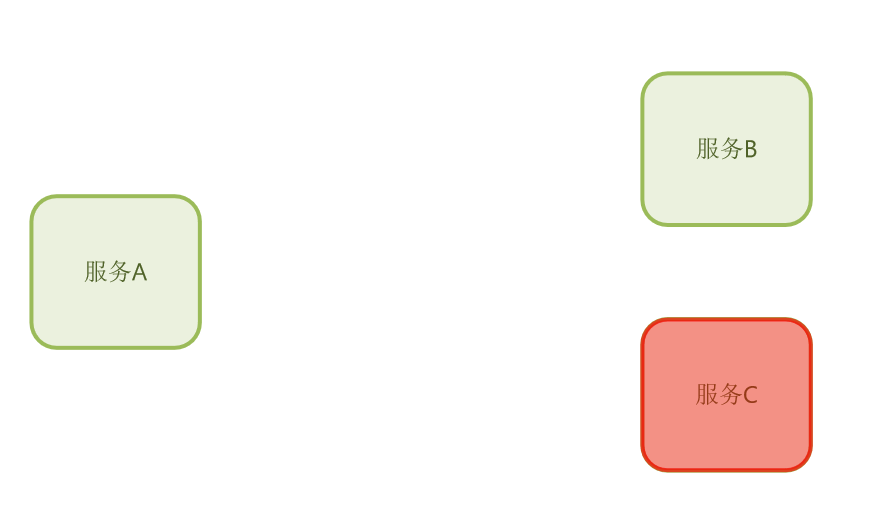
比方说,现在有服务B和服务C,还有服务A,服务A中有一些业务依赖于服务B,还有一些业务依赖于服务C。
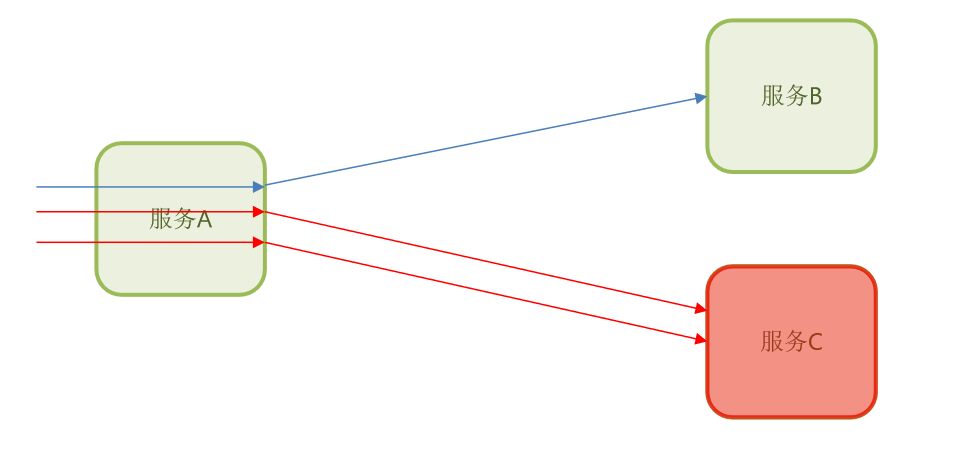
随着服务C出现故障,服务A内部依赖于服务C的所有业务都会阻塞,日积月累,服务A也就故障了。
那么超时处理会这么办呢?它会在调用业务时加上一个超时的时间。例如一秒。
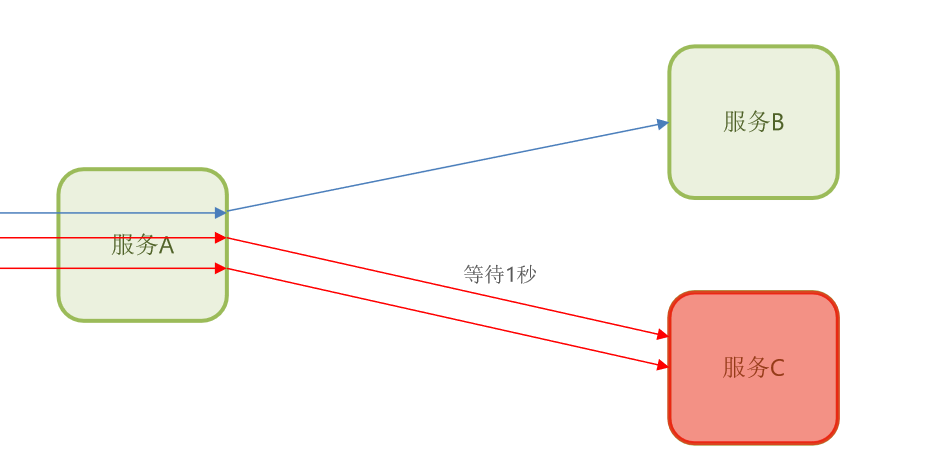
也就是说当服务A它的业务,依赖于服务C时,它最多等一秒。如果服务C故障以后,这个等待超过了一秒
,不好意思,它会立即结束这个请求,不再返回给用户一个提示信息。
就跟你说,不好意思,请求失败了。那这个请求是不是就释放了,就不会导致一直占用Tomcat资源,是不是一定程度上缓解这个雪崩问题?
但为什么是缓解雪崩问题?而不是100%解决了雪崩问题?
我们想想,它只是等待了一秒以后把资源释放,那也就是说,最长等待时间是不是一秒?我们可以理解成一秒钟释放一个,那如果你释放请求的速度是一秒释放一个。
但现在假设说新的请求速度是每秒钟两个,你释放的速度没有进入的速度快,是不是终有一天服务A的资源也有可能会被耗尽?所以你设置超时时间也只是起到了一个缓解作用,并没有从根本上解决这个问题。
1.2.2 舱壁模式
限定每个业务使用的线程数,避免耗尽整个Tomcat的资源,因此也叫线程隔离。
舱壁模式是来自于我们现实生活中,船舱的一个设计。
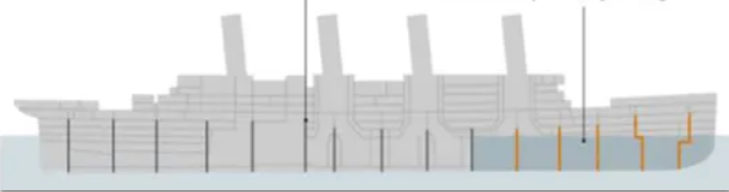
一些大型的轮船,它都会把船体利用这种隔板分割成独立的小的空间,隔板就相当于舱壁。
那么因为这些空间之间相互是隔离的,现在假设说,船体的某个部位撞上了冰山,漏水了,最多也是吧这个部分船舱给它填满水。
因为是隔离的,所以其他的船舱是不收影响的,那这样这个船是不是还可以承受啊,它可以承受一定的船舱进水嘛,其实也就提高了我们整整艘船的一个容灾能力。
那么这种模式延续到我们程序设计里面,它是怎么来做的呢?
还是刚刚的案例,服务A可以看成整艘船,然而我们该怎么避免整个Tomcat挂掉呢?
我们就把Tomcat里面的资源,也就是线程,划分成一个一个的独立的线程池。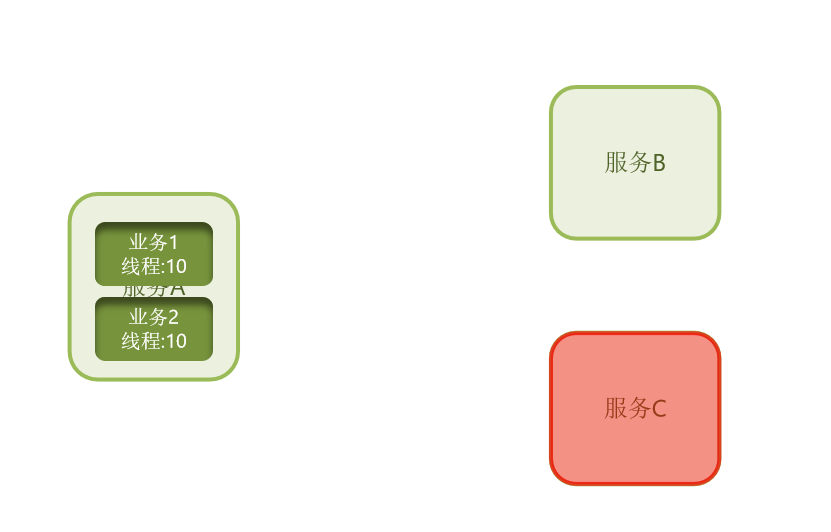
比方说给业务1分配10个线程池,业务2分配10个。
那么现在业务1进来之后,它依赖于服务B。
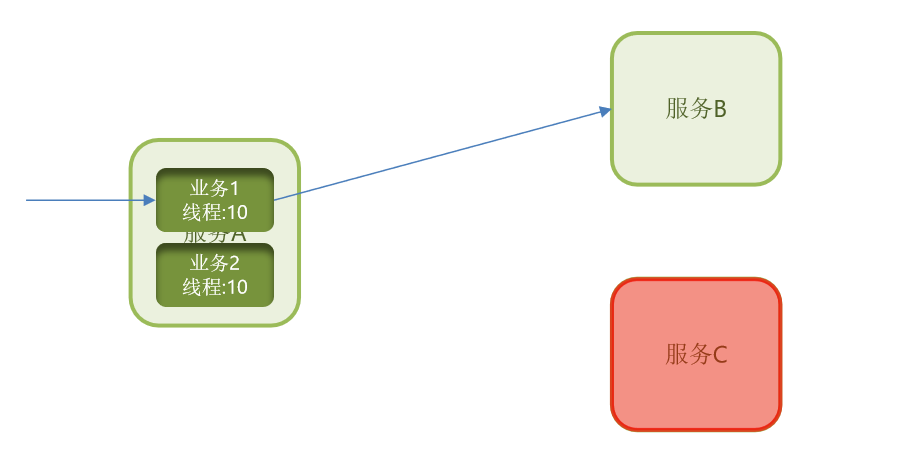
那它最多使用10个线程,访问业务2,它依赖于服务C。
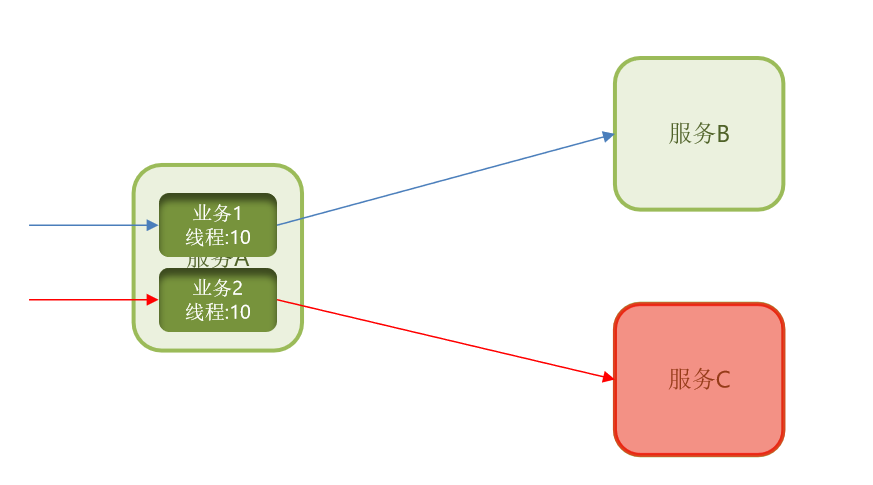
它也最多使用10个线程。
那现在服务C出现故障了,那这个业务就会阻塞,占用我们的线程,但是,它最多占用10个。
那这个时候它能够使用的Tomcat 资源是不是有限呢?是不是就把这个故障隔离到了10个线程内了?
对此这个模式也叫线程隔离模式,它其实啊就避免了整个Tomcat资源耗尽的这种情况。
当然这个模式它确实解决了超时处理方案所遗留的问题,只不过资源可能会有一些浪费。
比如说,服务C宕机挂了,接下来你还是会尝试区请求这个服务C,明知道它已经挂掉了,你还要尝试访问,还要暂用我10个线程,是不是一种浪费?
1.2.3 熔断降级
由断路器统计业务执行的异常比例,如果超出阈值会熔断该业务,拦截访问该业务的一切请求。
这种模式,它里面会有一个断路器,断路器它可以去统计业务执行的异常比例。
也就是说,你这个业务里面,出现故障的请求和正常的请求之间的一个比例是什么样子的?如果超出了阈值,则会熔断这个业务,什么是熔断,就是拦截访问该业务的一切请求。
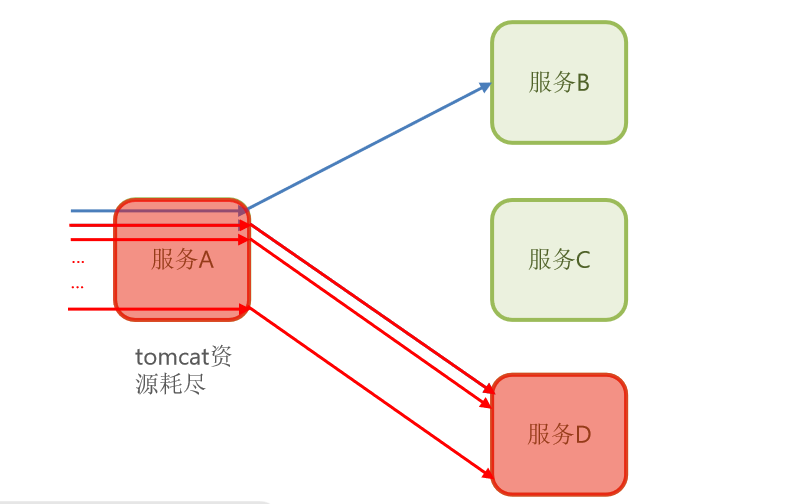
我们还是用图来表示一下,这也是我们之前说的,出现雪崩的一个情况,就是服务A里面所有的业务度卡在这里了,然后把资源耗尽。
那熔断怎么去解决这个问题呢?
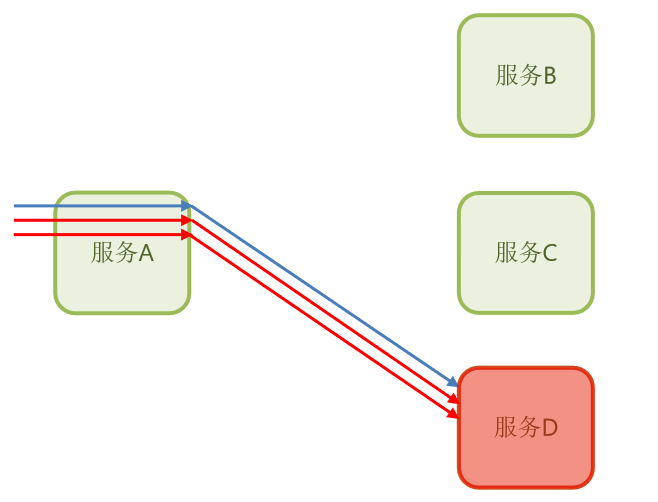
它会去统计服务A里面的业务,比方说再服务A里面有一个业务是来访问服务D的,然后第一次是正常的,
结果后面两次都出现了故障,那这个时候我们的断路器就会统计了你这个异常比例,这一看,三个请求,两个故障,是不是异常比列达到了60%?
那假设说我们的阈值是50%,那是不是超出了阈值,那么这个时候就会出现熔断。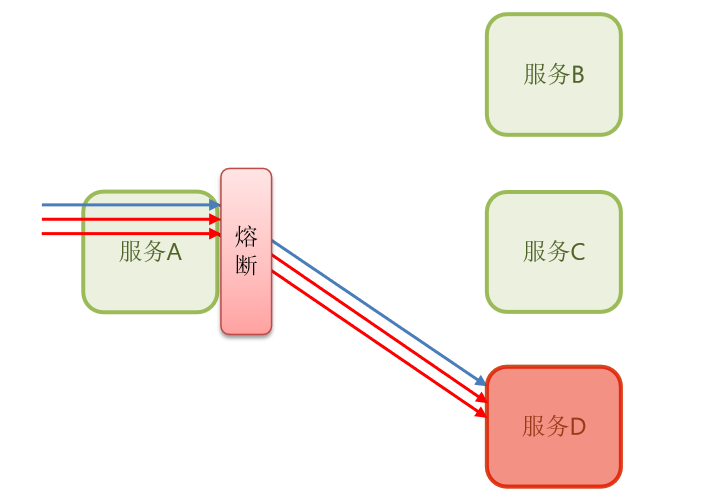
一旦出现熔断,那么再服务A内部还想访问服务D这个业务,也就是依赖于服务D的这个业务就无法再去访问服务D了。
只要是看到你是请求服务D的,就跟说:“滚!”,资源快速释放,那怎么可能会把它们耗尽呢?这不就解决了资源耗尽问题,而且既然知道立刻服务D是故障的,我压根不让你去访问它,是不是就不存在这种资源浪费的情况了?
1.2.4 流量控制
限制业务访问的QPS,避免服务因流量的突增而故障。
什么意思呢?比如说,这里有一个受保护的服务,它能承受的最大QPS是2,也就是每秒钟最多处理两个请求,但是现在有无数的请求涌过来,那你说他能承受得了吗?那肯定是不行的呀,这不被打成筛子了。
而一旦这个服务出现了故障,那依赖于这个服务的其他服务是不是也都跟着会出现故障,那岂不是也会出现雪崩状况,所以,我们一定要尽可能的避免服务因为流量过高而引起故障。
那我们该怎么办呢?这就用到了我们的 Sentinel 了。
现在呢,假如真的有无数个请求融入过来,而Sentinel,它可以按照这个服务所能够承受的一个频率去释放请求,这个时候我们的微服务不久能从容应对这些请求了吗?

那就避免了它出现故障,如果它不出现故障,那就不会把故障进行传递了,就不会出现雪崩问题了。
所以你看是不是把雪崩问题扼杀在了摇篮当中。因此流量控制,是预防雪崩控制。
2、服务保护技术对比
好的,各位,在上面,我们已经学习了雪崩问题以及常见的解决方案,而要实现这些解决方案,最好的方式肯定是使用现有的框架。
所以现在我们就要去对比一下实现服务保护的常见框架及其差别,这里呢,我们主要是对比一下Sentinel 和 Hystrix。
因为Hystrix是Spring Cloud 刚刚流行的这几年,推荐大家使用的。它是由Netflix 公司出品的,只不过随着Netflix公司宣布停止对Hystrix的升级和维护,现在就逐渐没落了。
人们也在尝试去寻找一个新的方案,而在这个时候,阿里巴巴就开源了一个项目,叫Sentinel, 并且已经成为SpringCloudAlibaba 当中的一个服务保护组件,现在已经被广泛的应用在国内的互联网公司。
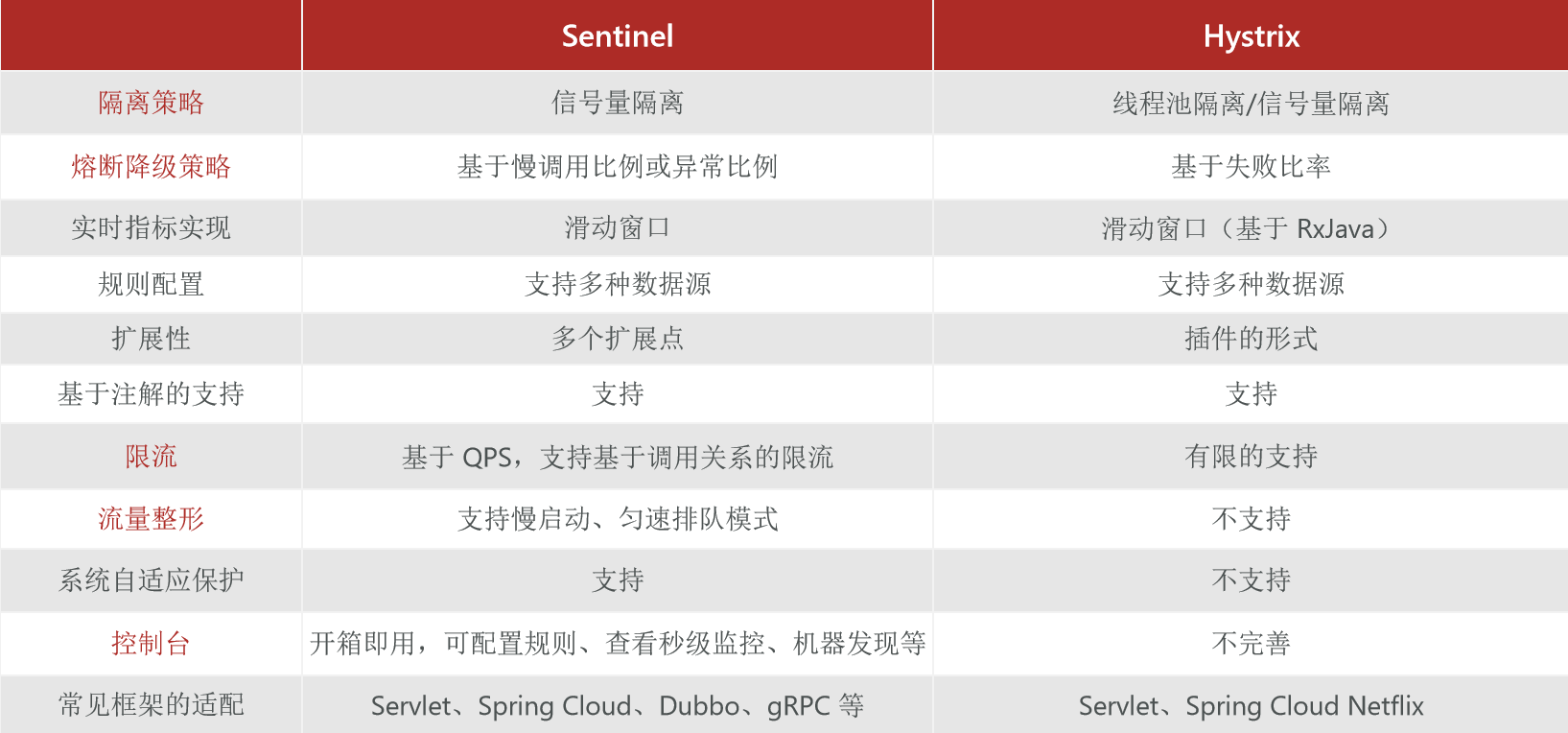
看上面的表格,我们主要关注红色的部分即可。
2.1 隔离策略
Sentinel 和 Hystrix 都支持 信号量来隔离,而Hystrix还支持线程池隔离,但默认情况下都是用线程池来隔离的。
这两种隔离有什么差别呢?
线程池大家可能会比较熟悉一点,因为我们说雪崩问题解决方案,舱壁模式举的就是线程池隔离的例子。
我们讲了,在一个业务请求进入TomCat以后,它会给每一个被隔离的业务创建一个独立的 线程池,每有一个被隔离的业务都会有一个独立的线程池,那自然也会有独立线程。
因此,它会比TomCat直接处理的这种方式会多出很多很多线程,那么可以认为线程池数量会成倍增长,那这种方式虽然隔离性比较好,但是随着线程数量增长,我们知道CPU它会带来一些额外的一个 上下文切换的消耗,所以整个服务的性能是会有一定的损失的。
而信号量隔离采用了的方案是什么呢?
当业务请求进入 TomCat 以后,我不会给你创建独立的线程池,而是去做一个统计,统计当前业务已经使用多少个线程了,然后我给你限制一下,说你只能使用10个,当你已经使用10个线程以后,再有新的业务需要去获取线程时,我就会阻止你了。
也就是说,它会限制每个业务能使用的线程数量,池子也就是那一个池子,TomCat默认的线程池,不去创建新线程,也不创建新的线程池。
这样就减少了线程的创建,在隔离的基础上并没有影响性能。但是,它这样的隔离性相比于线程池来讲会差一点,因为它毕竟是在同一个池子里面,只不过现在一个大锅饭,每个人拿个碗单独盛了。
这是两种隔离方式的差别。
2.2 熔断降级
熔断降级其实就是其实就是统计异常的比例,然后触发了异常比例的阈值,我就给你熔断,只不过在Sentinel里它可以除了统计异常请求的比例,它还可以统计慢调用的比例。
何为慢调用?
就是一个业务,它大多数情况下耗时都比较久,那它这个业务可能就会有问题,可能会拖慢我整个服务,有可能把我拖垮了,所以我可以把它熔断了。
但是在Hystrix 里默认都是基于这种异常的方式进行熔断降级的,所以Sentinel里面的这种熔断策略会更丰富一些。
2.3 限流
限流就是我们讲的流量控制,在Sentinel里,它支持基于QPS,还有调用关系的这种限流,甚至还可以针对热点的参数去做限流。这限流的方式多种多样。
而Hystrix里面,它没有专门的一个限流的控制,它其实就是基于这个线程池的,你的线程池设置成10,那你最多不就是10了嘛,是基于这种方式来限流的。所以这种限流的能力相对比较弱一点。
2.4 流量整形
流量整形就是让突发流量变成稳定的匀速的流量。那怎么做到的呢?
它可以支持慢启动,也就是预热模式,还有匀速排队等等。
所以这种方式让波动的请求变成匀速的请求,那我微服务处理起来就会更加的轻松。
在Hystrix里是不支持这样的功能的。
2.5 控制台
控制台就是我们所谓的UI界面,给你弄一个可视化的界面,方便你去查看操作。
在Sentinel 里,它有开箱即用的控制台,在里面你不仅仅可以去监控微服务,查看微服务运行状态,还可以去配置我们的降级规则,配完就立即动态生效了。
而在Hystrix 里,它的控制台只支持服务状态的功能,不具备动态修改规则这样的功能。
3、认识Sentinel 和 安装
接下来我们就去认识一下Sentinel 并且去安装一下它的控制台。
3.1.初识Sentinel
首先,我们都知道Sentinel是阿里巴巴开源的一款微服务流量控制组件。
官网地址:https://sentinelguard.io/zh-cn/index.html
然后下面就是介绍了Sentinel 的一些特征:
•丰富的应用场景:Sentinel 承接了阿里巴巴近 10 年的双十一大促流量的核心场景,例如秒杀(即突发流量控制在系统容量可以承受的范围)、消息削峰填谷、集群流量控制、实时熔断下游不可用应用等。
•完备的实时监控:Sentinel 同时提供实时的监控功能。您可以在控制台中看到接入应用的单台机器秒级数据,甚至 500 台以下规模的集群的汇总运行情况。
•广泛的开源生态:Sentinel 提供开箱即用的与其它开源框架/库的整合模块,例如与 Spring Cloud、Dubbo、gRPC 的整合。您只需要引入相应的依赖并进行简单的配置即可快速地接入 Sentinel。
•完善的 SPI 扩展点:Sentinel 提供简单易用、完善的 SPI 扩展接口。您可以通过实现扩展接口来快速地定制逻辑。例如定制规则管理、适配动态数据源等。
3.2 安装Sentinel
1、下载
sentinel官方提供了UI控制台,方便我们对系统做限流设置。大家可以在[Releases · alibaba/Sentinel (github.com)](https://github.com/alibaba/Sentinel/releases)下载。
2、运行
将jar包放到任意非中文目录,打开终端执行命令:

java -jar sentinel-dashboard-1.8.6.jar
如果要修改Sentinel的默认端口、账户、密码,可以通过下列配置:
| 配置项 | 默认值 | 说明 |
|---|---|---|
| server.port | 8080 | 服务端口 |
| sentinel.dashboard.auth.username | sentinel | 默认用户名 |
| sentinel.dashboard.auth.password | sentinel | 默认密码 |
例如,修改端口:
java -Dserver.port=8090 -jar sentinel-dashboard-1.8.6.jar
3.3 访问
访问http://localhost:8080页面,就可以看到sentinel的控制台了:账号密码都是 sentinel

4、微服务整合Sentinel
要使用Sentinel肯定要结合微服务,这里我们使用以前用过的SpringCloud工程。有需要的小伙伴可以下载这个工程
springCloud案例演示: springcloud学习演示 (gitee.com)
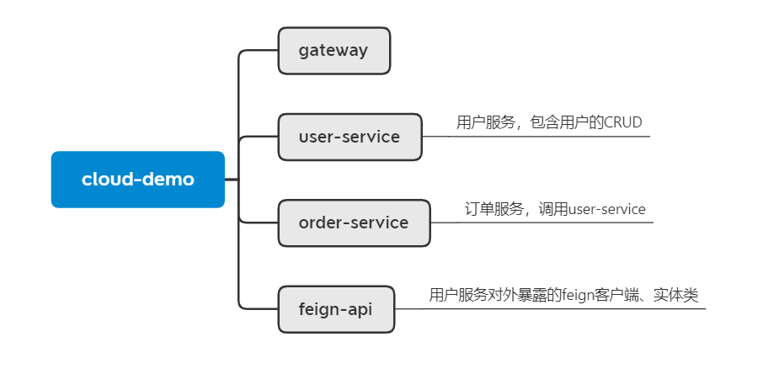
项目结构如下:
然后大家记得启动一下Nacos
然后启动这三个项目:
现在我们的微服务已经准备好了,那下一步就可以去整合Sentinel了。
我们基于order-service去讲解。
4.1 引入依赖
<!--sentinel-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>
4.2 配置控制台
修改application.yaml文件,添加下面内容:
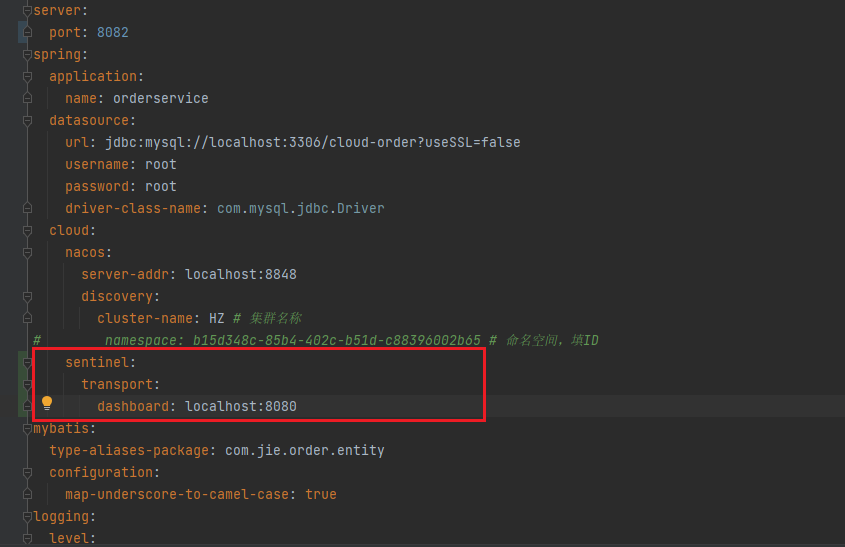
弄完之后重启服务!!!
4.3 访问order-service的任意端点(接口)
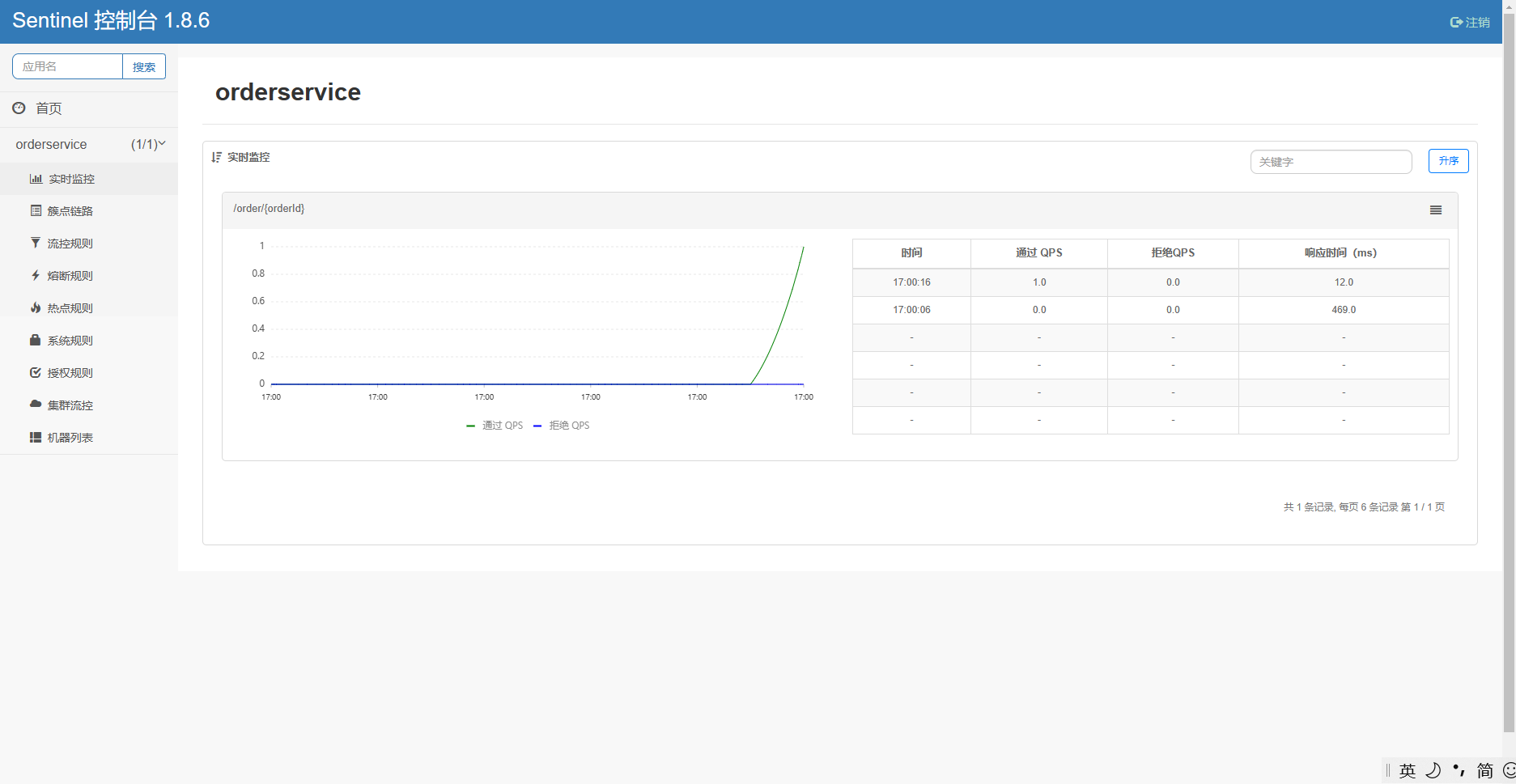
打开浏览器,访问http://localhost:8088/order/101,这样才能触发sentinel的监控。
然后再访问sentinel的控制台,查看效果:
5、限流规则
接下来我们就要去学习Sentinel的用法,去解决我们之前说到的雪崩问题。
之前我们在讲解雪崩问题的时候提到了4种解决方案,而Sentinel主要是实现了其中的三种。
分别是:
- 限流
- 线程隔离
- 降级熔断
5.1 快速入门
首先我们通过一个快速入门了解一下Sentinel它的限流基本用法。
我们先来了解一个概念。
簇点链路:
当请求进入微服务时,首先会访问DispatcherServlet,然后进入Controller、Service、Mapper,这样的一个调用链就叫做簇点链路。簇点链路中被监控的每一个接口就是一个资源。
默认情况下sentinel会监控SpringMVC的每一个端点(Endpoint,也就是controller中的方法),因此SpringMVC的每一个端点(Endpoint)就是调用链路中的一个资源。
例如,我们刚才访问的order-service中的OrderController中的端点:/order/{orderId}
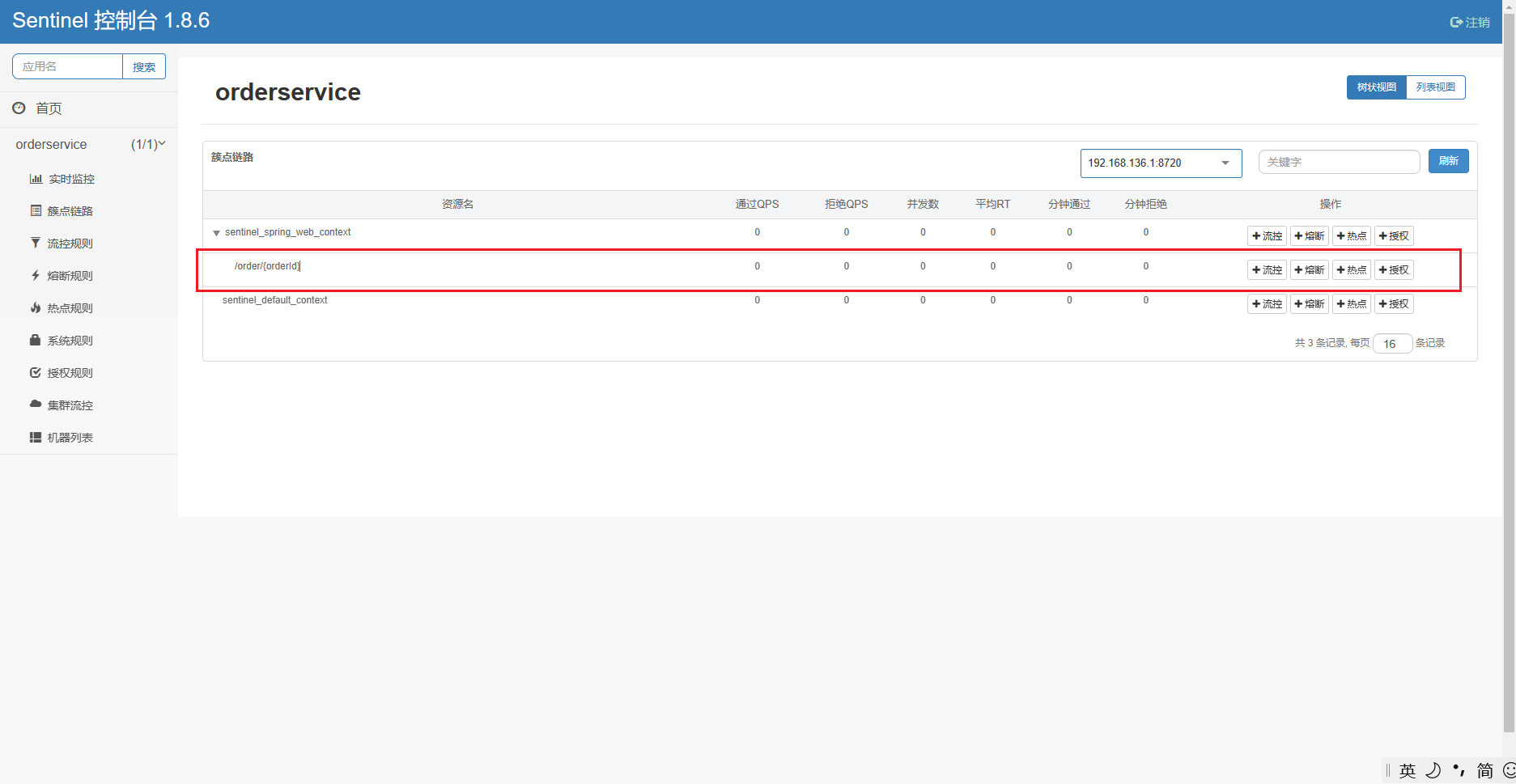
流控、熔断等都是针对簇点链路中的资源来设置的,因此我们可以点击对应资源后面的按钮来设置规则:
- 流控:流量控制
- 降级:降级熔断
- 热点:热点参数限流,是限流的一种
- 授权:请求的权限控制
那也就是说,我们将来可以去给资源去做降级等等各种各样的操作。
那具体怎么去做呢?
比如,我们点击资源/order/{orderId}后面的流控按钮,就可以弹出表单。
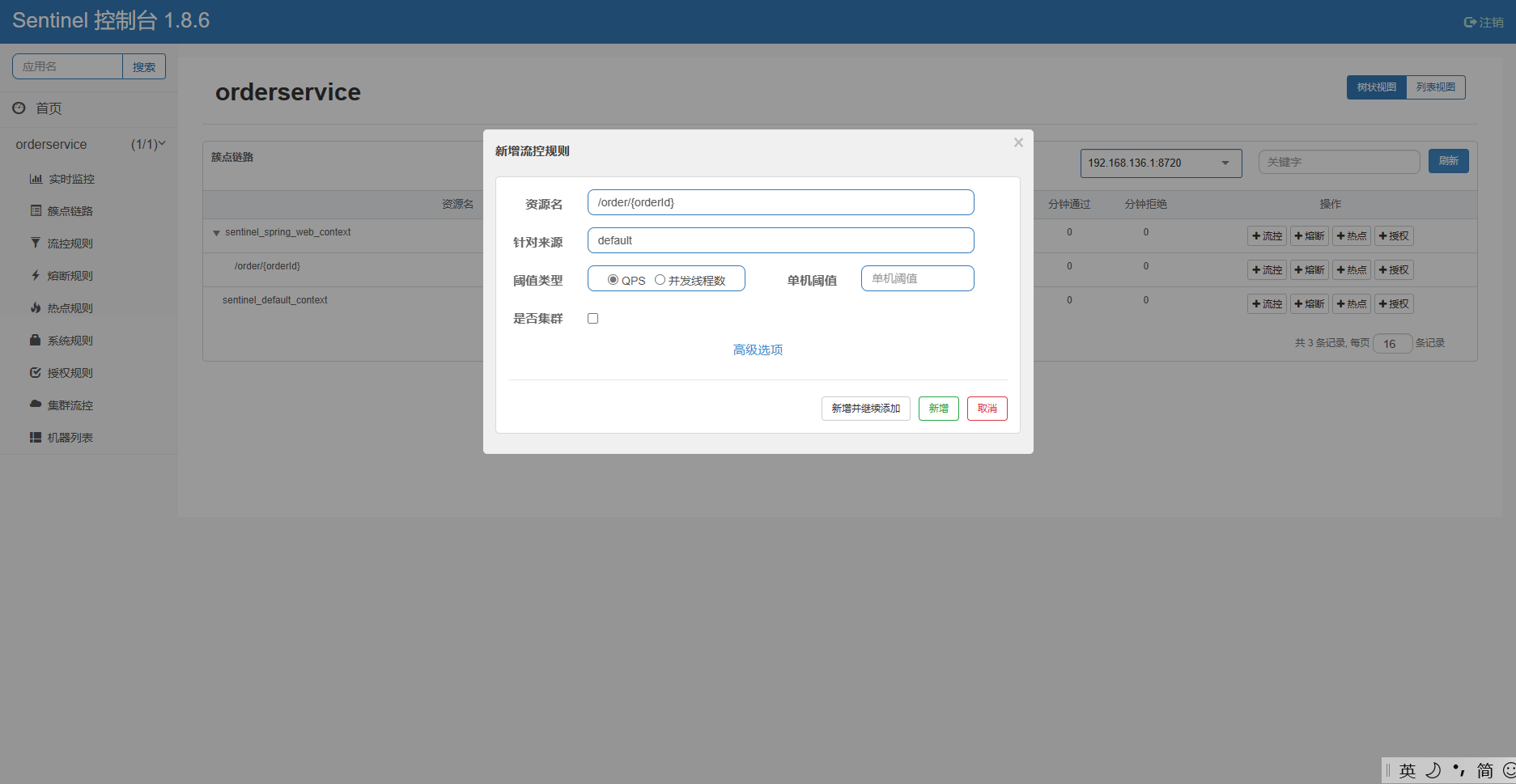
这个表单有几个需要你去填写的东西。
第一是资源名称,因为你点的是 /order/{orderId} 这个资源,所以默认资源名称就是它,也就说这个流控规则是针对这个请求的。
第二个是针对来源,就是说从哪访问过来的请求需要被限流,default 就是一切进来的请求都要被限流,那一般情况下限流我们不需要去制定来源,就是所有请求都要限流。
第三个是阈值类型,一般都选择QPS, QPS就是指并发量嘛,也就是说每秒钟的请求数量,而后面指定的单击阈值就是指这个QPS的上限。1就代表即每秒只允许1次请求,超出的请求会被拦截并报错。至于将来这个单击阈值设置多少呢?就设置你的这个接口它最大的一个并发量就行了。怎么知道自己的这个服务的并发量是多少呢?做压力测试。
5.1.1演示
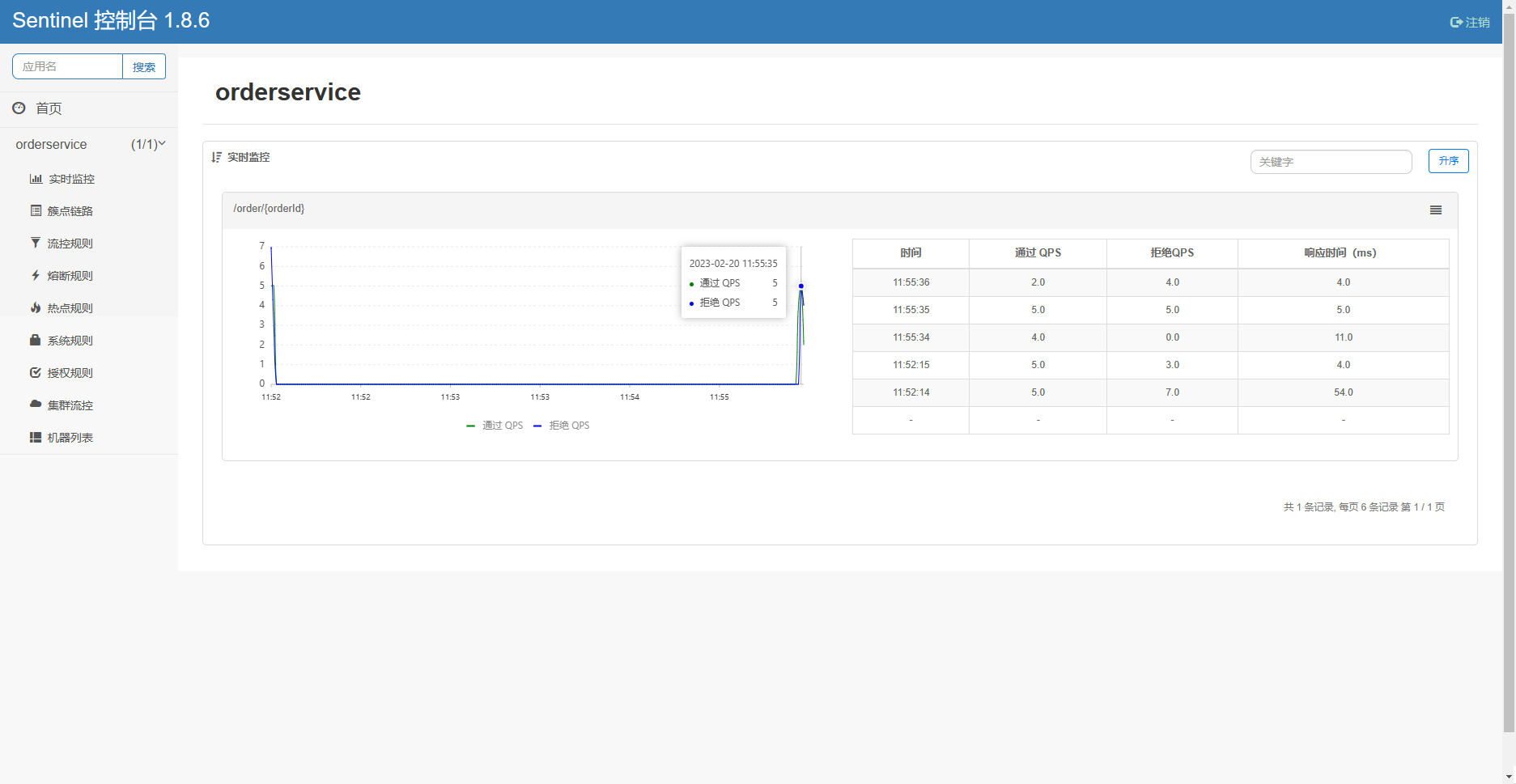
接下来我们给 /order/{orderId}这个资源设置流控规则,QPS不能超过 5,然后利用Jemeter进行压力测试。
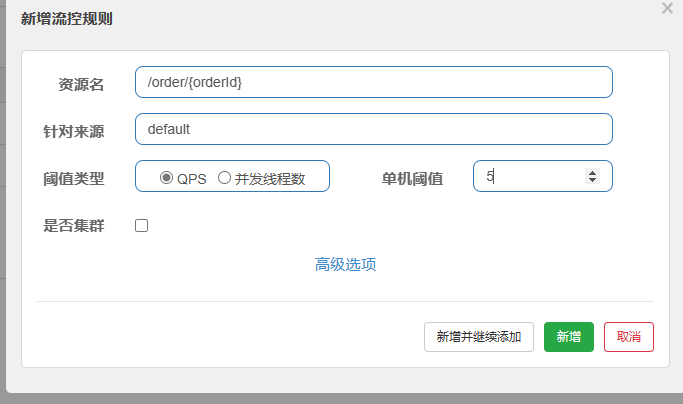
使用Jemeter。
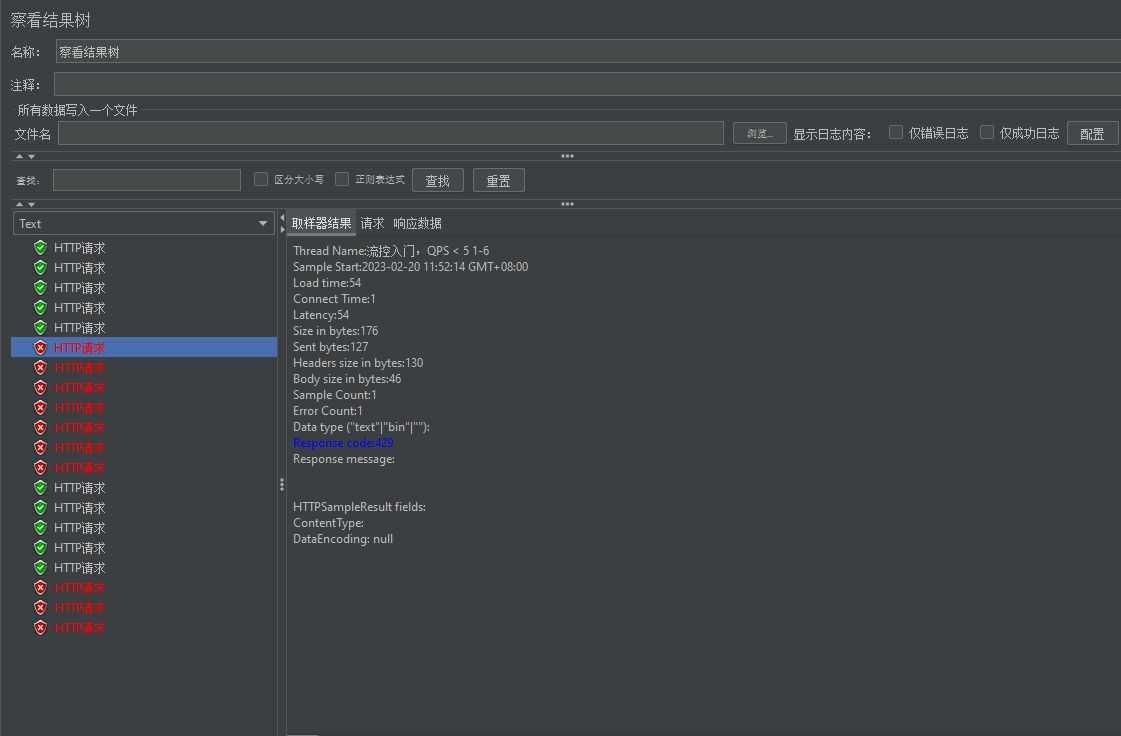
我们可以看到,请求发出了,但是每次通过只有五个,另外的就失败了。
我们还可以看看Sentinel控制台。
5.2 流控模式
通过快速入门,我们已经学习Sentinel 的基本用法,我们接下来就来看一下限流里面的高级配置。
在添加限流规则时,点击高级选项,可以选择三种流控模式:
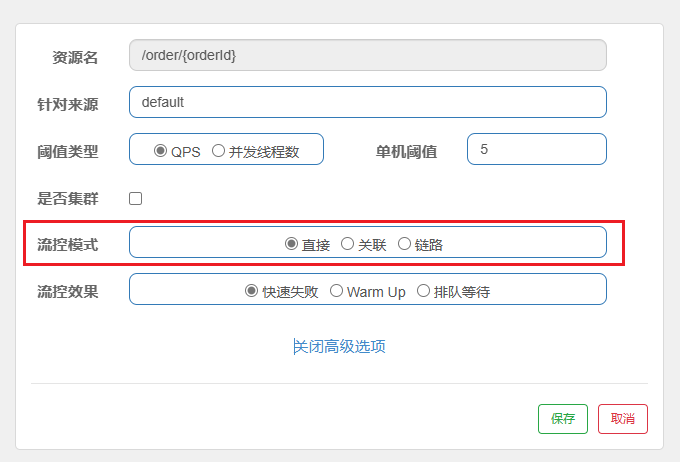
- 直接:统计当前资源的请求,触发阈值时对当前资源直接限流,也是默认的模式
- 关联:统计与当前资源相关的另一个资源,触发阈值时,对当前资源限流,也就是说 ,我现在有A和B两个资源,a触发了阈值,但我却对B做限流。
- 链路:统计从指定链路访问到本资源的请求,触发阈值时,对指定链路限流,不是对当前资源做限流;例如,现在我有A,B,C三个资源,A和B都要访问资源C,但是我在统计资源C的时候,只统计从A过来的请求,B的我不管。
直接模式我们就不做过多介绍,我们主要来看关联模式和链路模式,它们在什么情况下选择去用呢?
5.2.1 关联模式
使用场景:我们有一个用户支付的业务,用户支付完了,要修改订单状态,同时,另外一边可能还会有用户要去查询订单,那大家都知道,查询和修改的动作,他们会去争抢数据库的锁,那因此会产生竞争关系。写的操作过于频繁,自然会影响读的操作,反之亦然。
但是我们知道在业务里面,支付业务更新订单,这个业务肯定优先级更高,我们肯定要用户优先支付呀,那查询业优先级相对较低,所以我们希望当更新订单的这个业务触发阈值时,说明它有更高的要求,那我们就要对查询业务做限流,防止它影响到我们的修改业务。
案例:
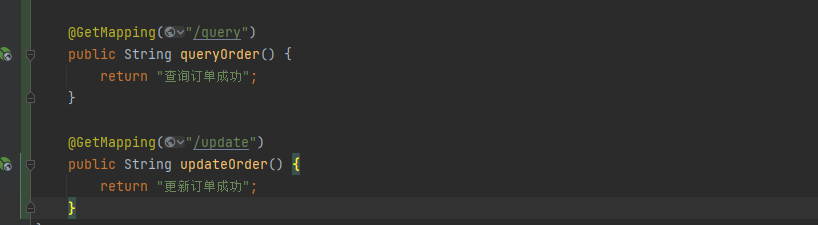
接下来我们通过一个案例来演示一下关联模式如何使用。
我们先在代码中增加两个接口。
重启服务,查看sentinel控制台的簇点链路:
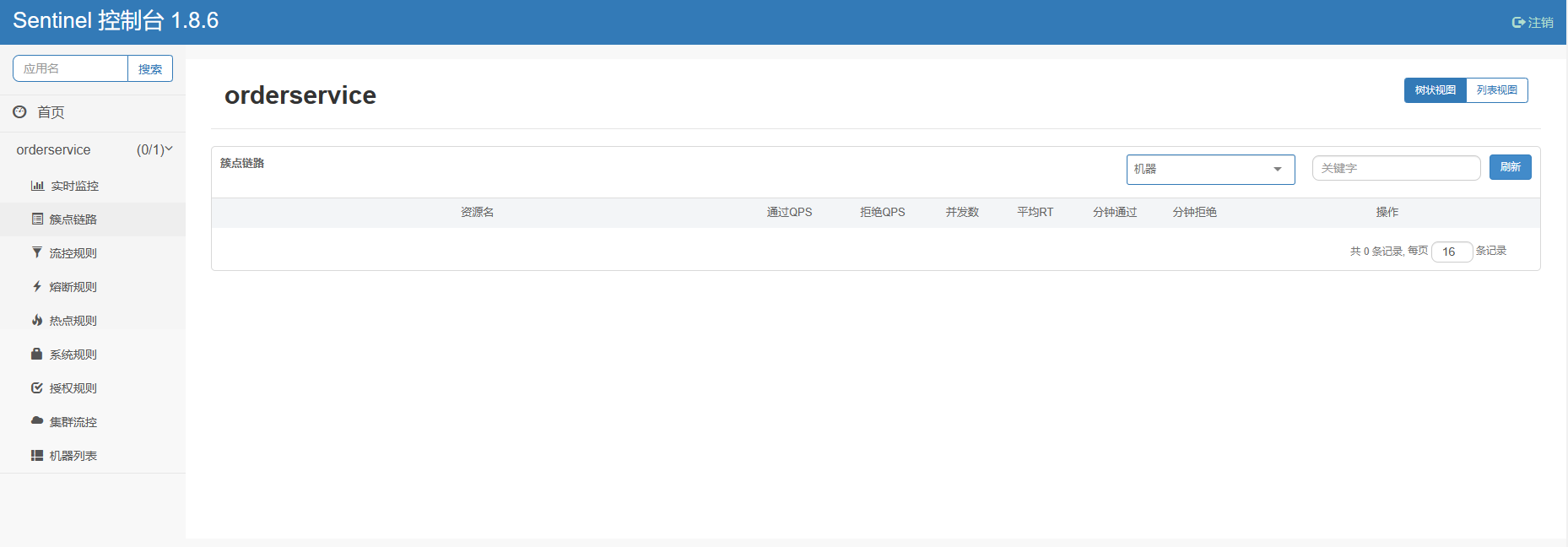
重启之后,所有东西都消失了,我们得重新访问一下接口。
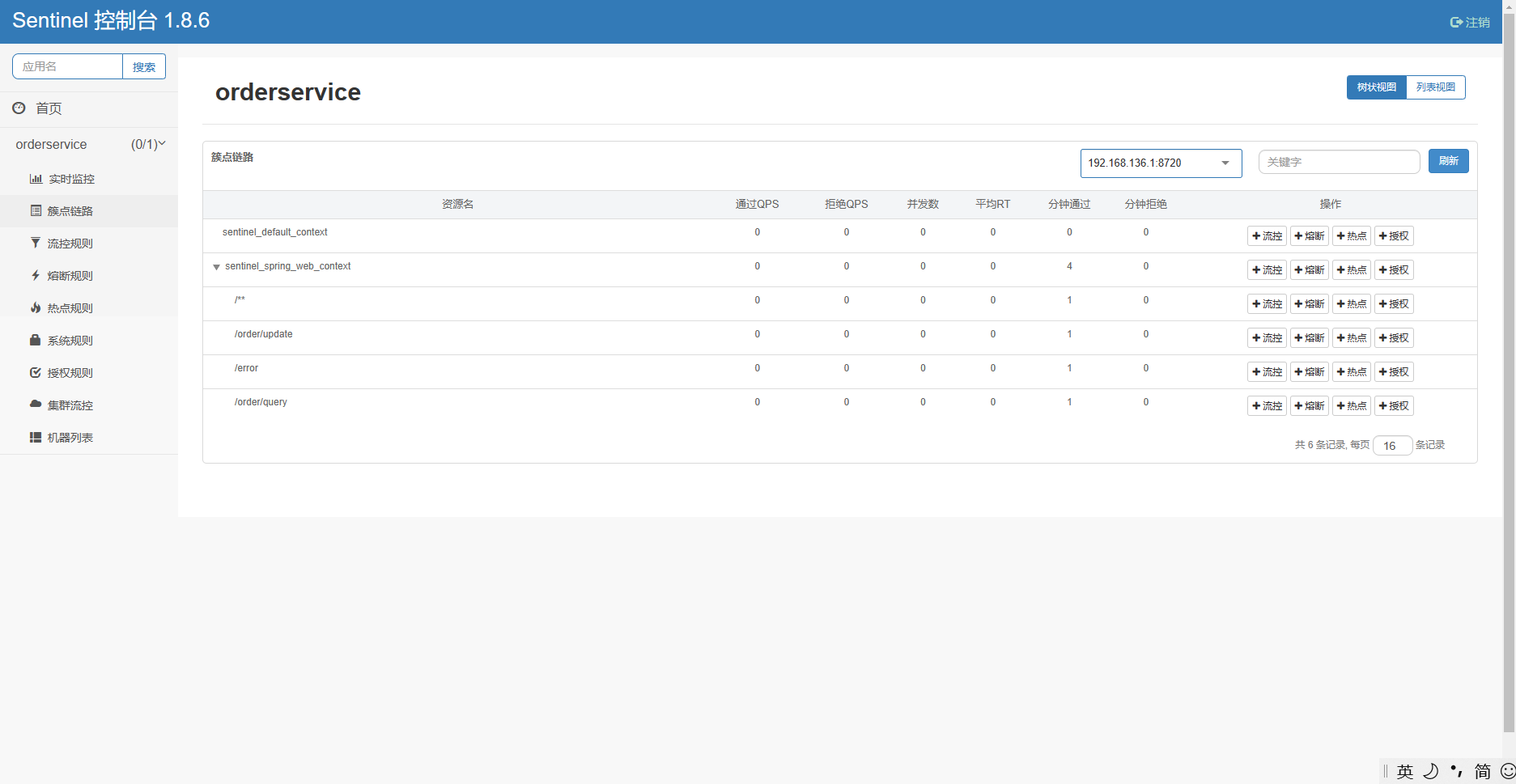
现在我们得query 和 update 已经出现在Sentinel 控制台中了,现在我们的需求是,当update的QPS 达到 5时,对Query 做限流处理。
请问,我要给谁添加流控规则?
我们要记住,给谁限流我们就要给谁添加规则。
那我们就要给query 增加流控规则。
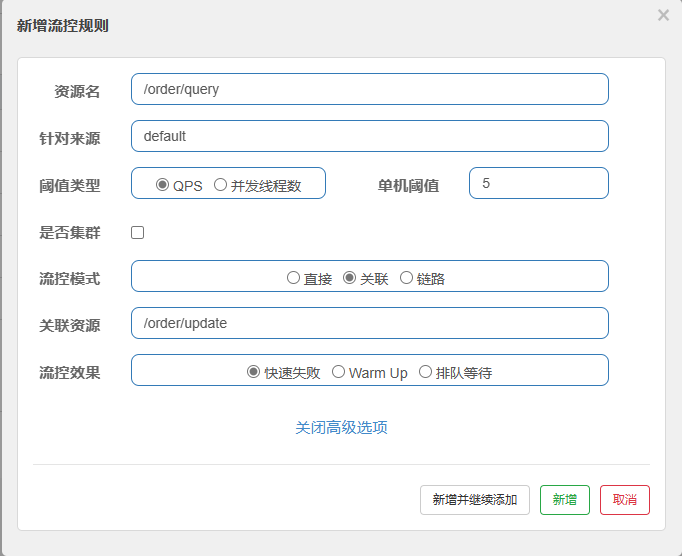
我们接下来就使用Jmeter 去做一下测试。
Jmeter 正常请求没有没有限流,我们看看query。
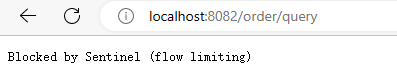
确实被限流了。
总结一下:
满足以下两个条件我们可以使用关联模式。
- 两个有竞争关系的资源
- 一个优先级较高,一个优先级较低
5.2.2 链路模式
接下里我们来了解链路模式。这里我们直接通过一个例子来学习
例如我有两条请求链路:
-
/test1 --> /common
-
/test2 --> /common
一个是从test1 来访问 common,一个是test2访问common。、
而我们下面有这么一个配置。
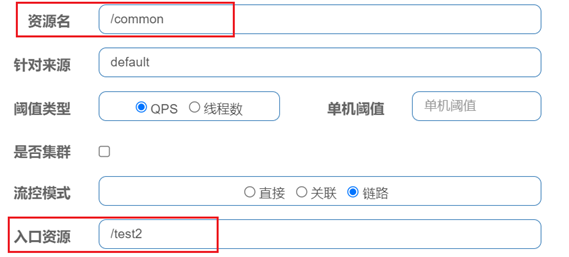
配置的资源名称是common,而流控的方式呢?是链路方式。入口资源是test2。
那入口资源这个配置的意思是什么呢?
就是我在做限流统计时,只统计从test2进入common的请求,那test1进来的我就不管了。
所以这种统计是对请求来源的一种统计。
问题来了,什么情况下?我们要用到这种模式呢?
我有一个查询订单和创建订单的业务,而这俩业务都需要查询商品。那这不就形成了两个链路了吗?
从查询订单到查商品和创建订单到查商品。而我们知道查询订单业务的并发往往会比较高,但是查询商品这个业务肯定会有自己的并发上限,如果查询业务的并发过高,势必会影响到创建订单的业务,那因此,我们应该把查询业务的并发做一个限制,怎么做呢?
步骤:
在OrderService中添加一个queryGoods方法,不用实现业务
在OrderController中,改造/order/query端点,调用OrderService中的queryGoods方法
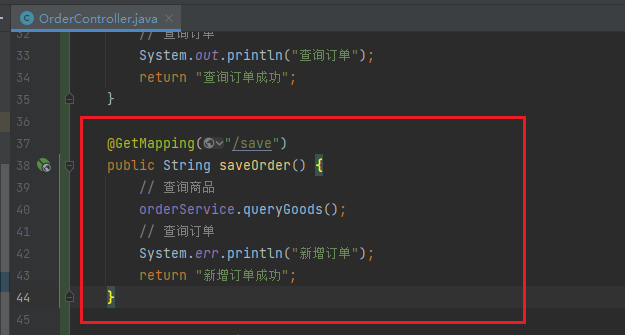
在OrderController中添加一个/order/save的端点,调用OrderService的queryGoods方法
给queryGoods设置限流规则,从/order/query进入queryGoods的方法限制QPS必须小于2
知道了步骤,我们就去实现一下:
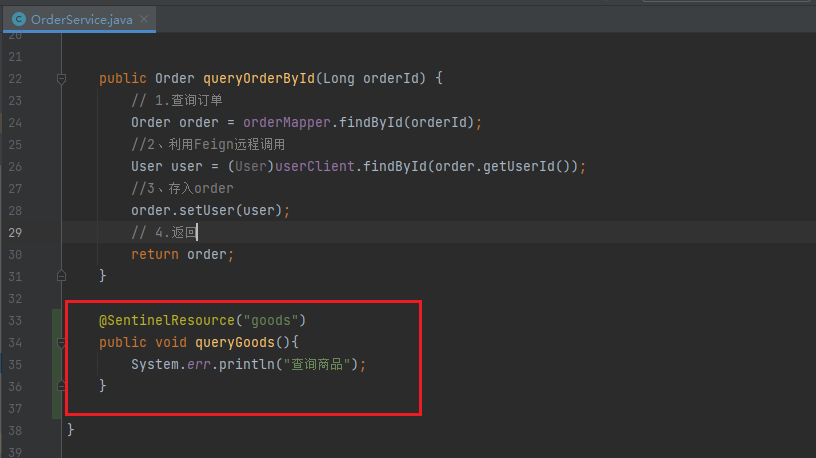
首先在order-service服务中,给OrderService类添加一个queryGoods方

在order-service的OrderController中,修改/order/query端点的业务逻辑:
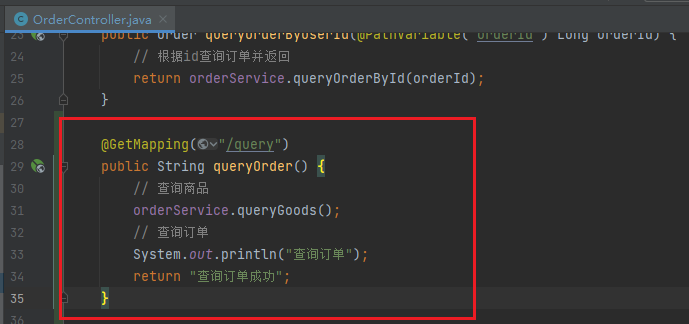
然后在order-service的OrderController中,修改/order/save端点,模拟新增订单:
默认情况下,OrderService中的方法是不被Sentinel监控的,需要我们自己通过注解来标记要监控的方法。
给OrderService的queryGoods方法添加@SentinelResource注解:
链路模式中,是对不同来源的两个链路做监控。但是sentinel默认会给进入SpringMVC的所有请求设置同一个root资源,会导致链路模式失效。
我们需要关闭这种对SpringMVC的资源聚合,修改order-service服务的application.yml文件:
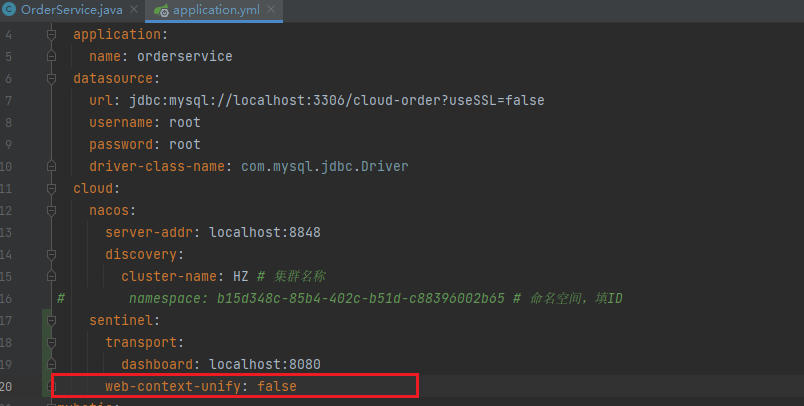
重启服务,访问/order/query和/order/save,可以查看到sentinel的簇点链路规则中,出现了新的资源:
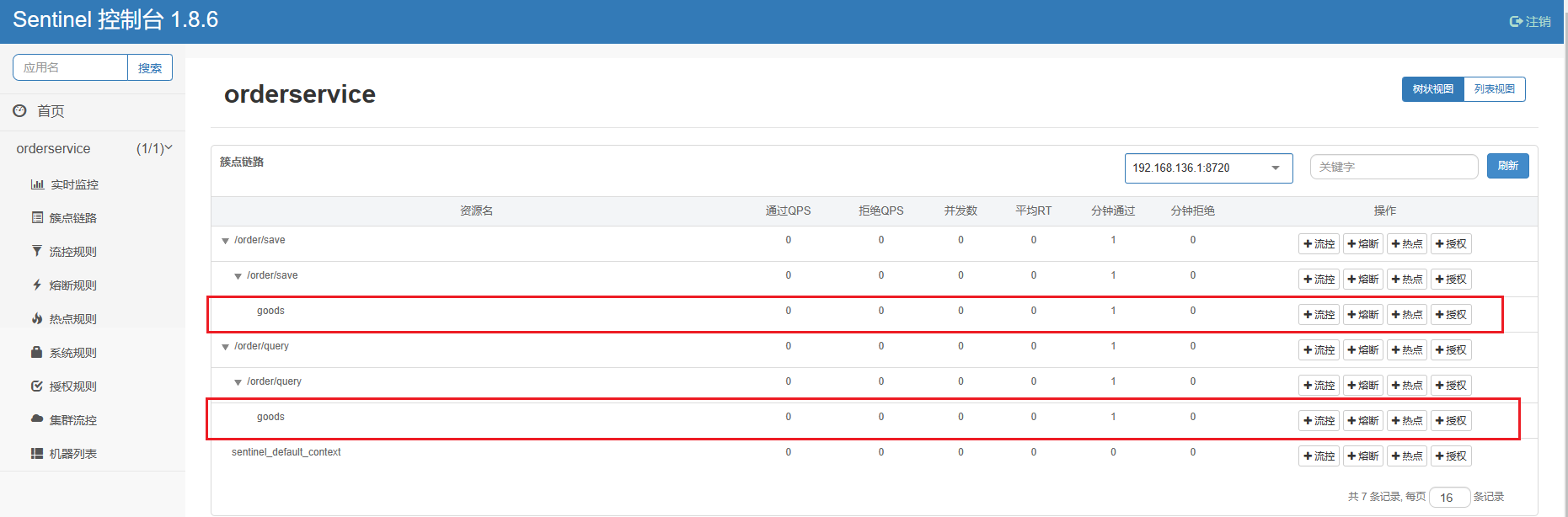
我们可以看到order/save 和 order/query 变成了两个独立的链路,在这之前没有关闭context 整合的时候,它俩还是属于同一个根链路下的两个子链路。
解下来我们就可以给这个 goods 去添加流控规则,上面有两个,我们可以随意选择一个,这两个goods 其实是同一个。
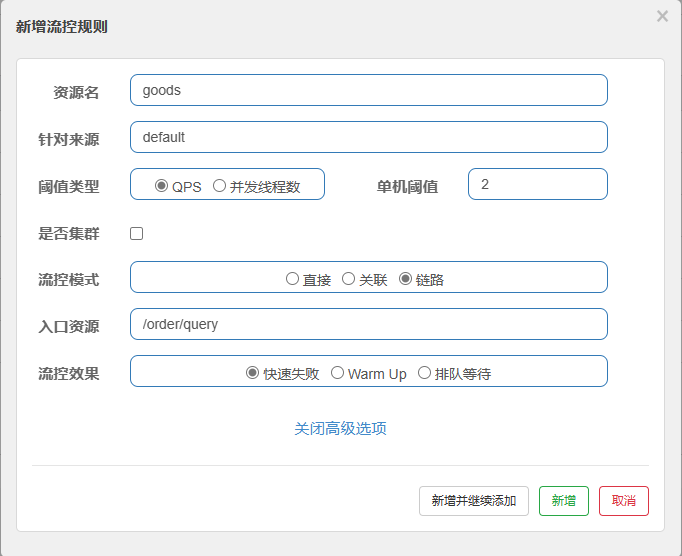
这样链路规则就配置好了,接下来我们就利用Jmeter 去做测试。(现在我们只对query做限制)
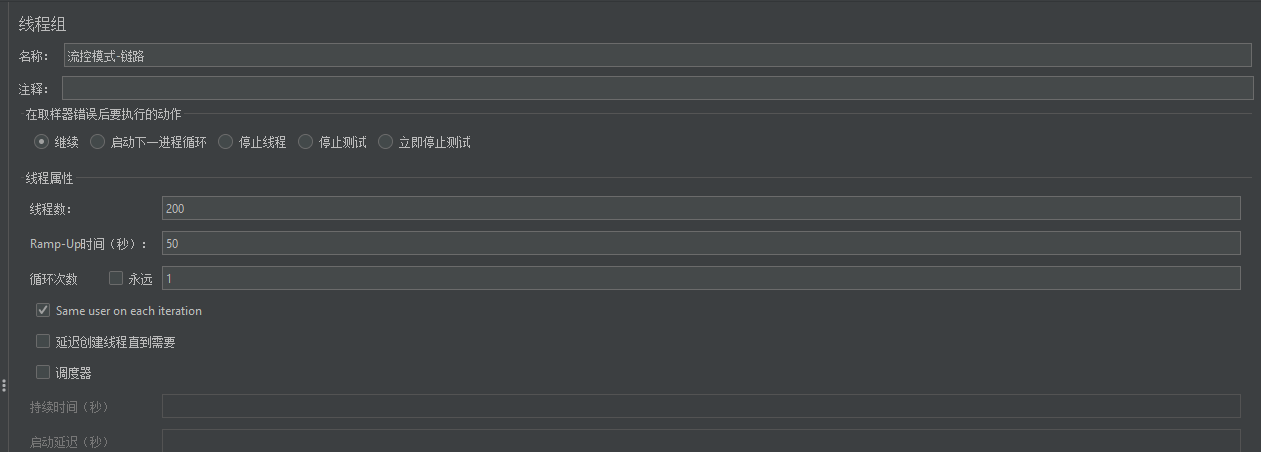
可以看到这里200个用户,50秒内发完,QPS为4,超过了我们设定的阈值2
一个http请求是访问/order/save:
一个http请求是访问/order/query:
运行的结果:
sava:

query:

我们可以看到save不受任何影响,query 都是俩个俩个失败的,这就是根据来源请求做限流。
5.3 流控效果
前面我们已经学习完了流控模式,接下来我们学习流控效果。什么是流控效果呢?
流控效果是指请求达到流控阈值时应该采取的措施,包括三种:
快速失败:达到阈值后,新的请求会被立即拒绝并抛出FlowException异常。是默认的处理方式。所以我们之前在做测试的时候会发现,一旦服务触发了限流,那就会得到一个异常状态码(429),抛出的信息就是flow limiting 就是被限流了。
warm up:预热模式,与快速失败相似,都是对超出阈值的请求同样是拒绝并抛出异常。但它们不同的地方在于这种模式阈值会动态变化,预热模式从一个较小值逐渐增加到最大阈值。
排队等待:它前面的模式不一样,它不会立即抛出异常,而是让所有的请求按照先后次序排队执行,两个请求的间隔不能小于指定时长,如果大于,就会被拒绝并抛出异常。
5.3.1 warm up:预热模式
我们先来学习 warm up:预热模式。
这个预热模式,它同样会把超出阈值的请求直接拒绝,并且抛出异常,但特殊之处在于,它的阈值不是一成不变的。这种方案是来应对服务冷启动的方案,那什么是服务冷启动呢?
这就像一个人,你要去做一些剧烈的运动之前,你肯定得先做一些拉伸的运动,给你的身体做一个预热,如果不做,你很容器在运动中;拉伤自己的肌肉。
那服务器也一样,服务器它的最大QPS 能够达到 比如说是10,但是它刚刚启动,你立马就直接把QPS打满,它可能还没有反应过来呢,就被你打懵了。它挂了,所以说呀,我们的服务刚刚启动时,不能上来就把QPS打满。
怎么办呢?
在预热模式中,初始的请求阈值初始值 = maxThreshold(最大阈值) / coldFactor(冷启动因子),持续指定时长后,逐渐提高到maxThreshold值。而coldFactor的默认值是3。
预热模式就是为了避免冷启动那一刻避免过高并发导致故障。
例如,我设置QPS的maxThreshold为10,预热时间为5秒,那么初始阈值就是 10 / 3 ,也就是3,然后在5秒后逐渐增长到10.
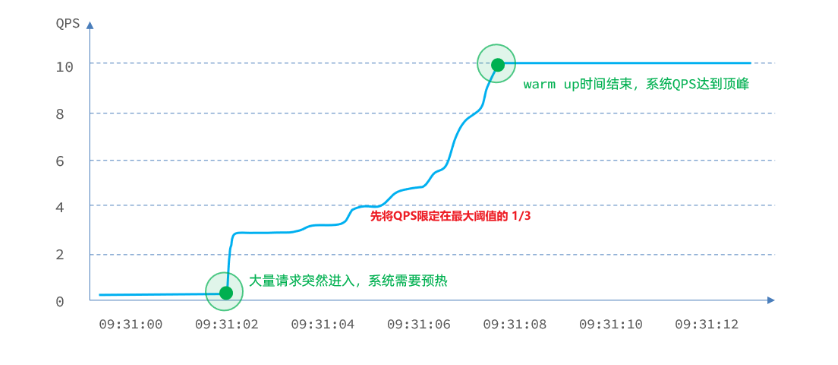
案例:
我们给/order/{orderId}这个资源设置限流,最大QPS为10,利用warm up效果,预热时长为5秒
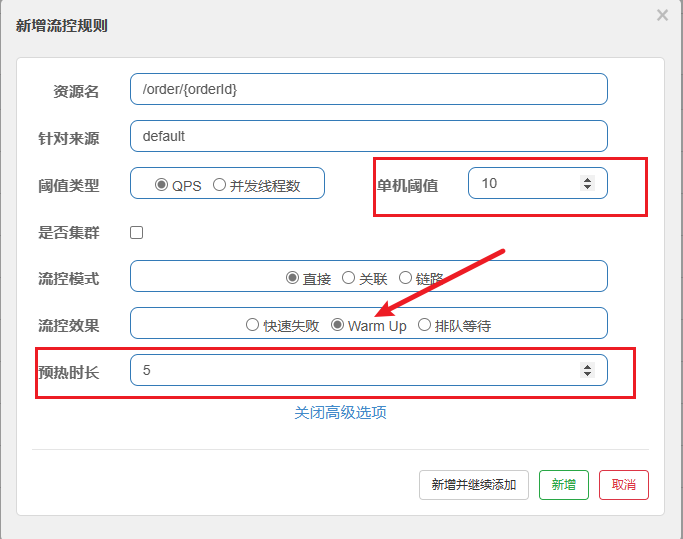
Jmeter测试:
QPS为10.

刚刚启动时,大部分请求失败,成功的只有3个,说明QPS被限定在3:
随着时间推移,成功比例越来越高:
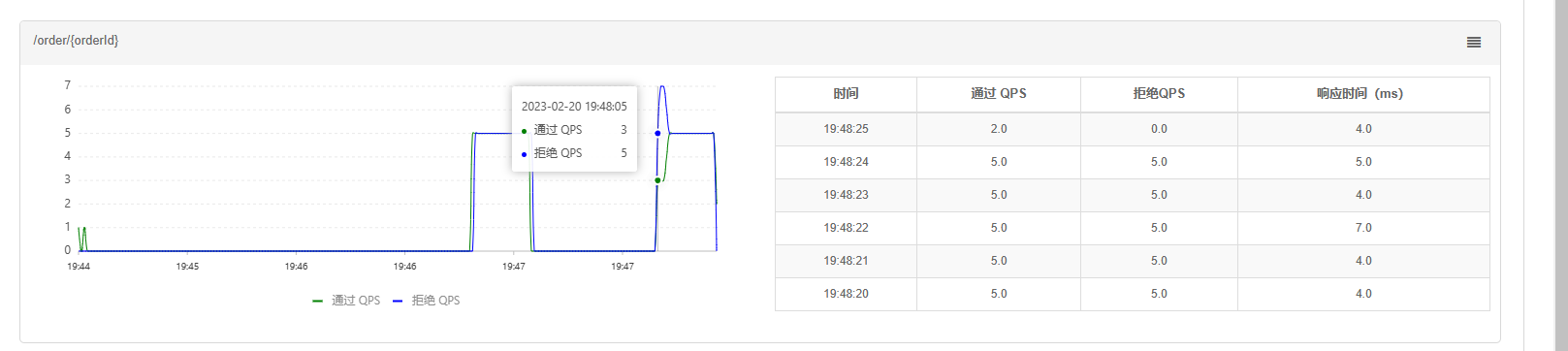
到Sentinel控制台查看实时监控:
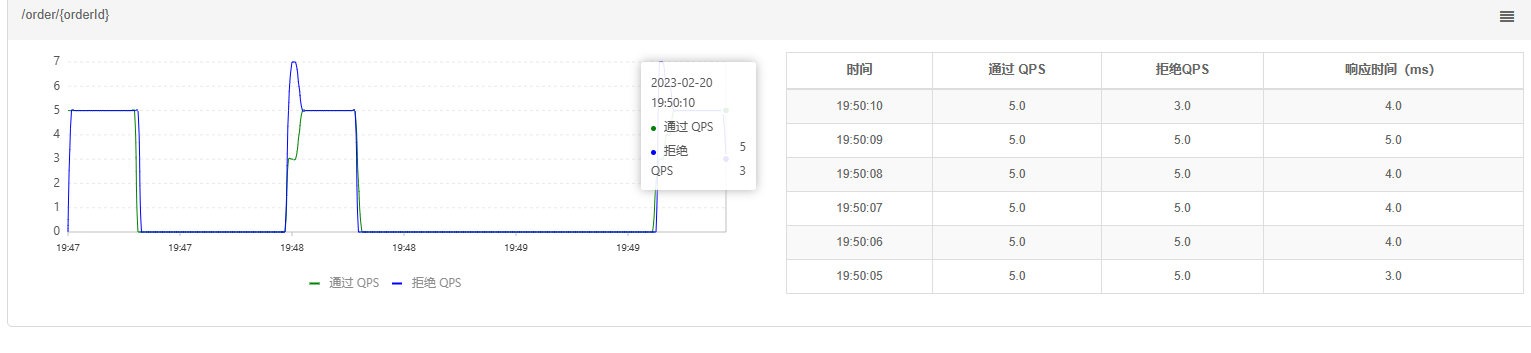
一段时间后:
5.3.2 排队等待
我们之前讲的快速失败和warm up 会拒绝新的请求并抛出异常,而排队等待则是让所有请求进入一个队列中,然后按照阈值允许的时间间隔依次执行。
后来的请求必须等待前面执行完成,如果请求预期的等待时间超出最大时长,则会被拒绝。
举个栗子:
QPS等于5(一秒钟5个请求),意味着每200ms处理一个队列中的请求;那Sentinel 就会严格去执行这个时间间隔,前面一个请求执行完,第二个请求一定要等够200毫秒。
比如说前面的请求执行小于200毫秒,不管那么多,第二个一定要等够200毫秒才行。所以这个200毫秒叫预期等待时间。
那我们就可以换算一下,我的前面已经有5个请求了,我要等待多久?1秒。这个就叫预期等待时长。
timeout = 2000,意味着预期等待超过2000ms的请求会被拒绝并抛出异常。
现在,第1秒同时接收到10个请求,但第2秒只有1个请求,此时QPS的曲线这样的:
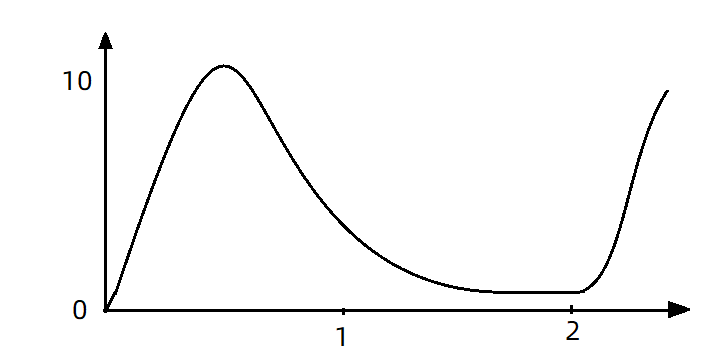
如果使用队列模式做流控,所有进入的请求都要排队,以固定的200ms的间隔执行,QPS会变的很平滑:
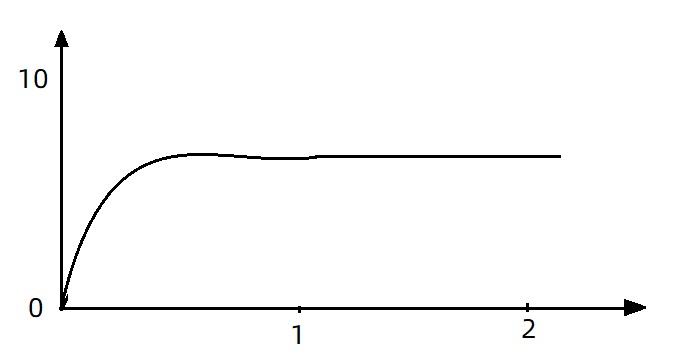
平滑的QPS曲线,对于服务器来说是更友好的。
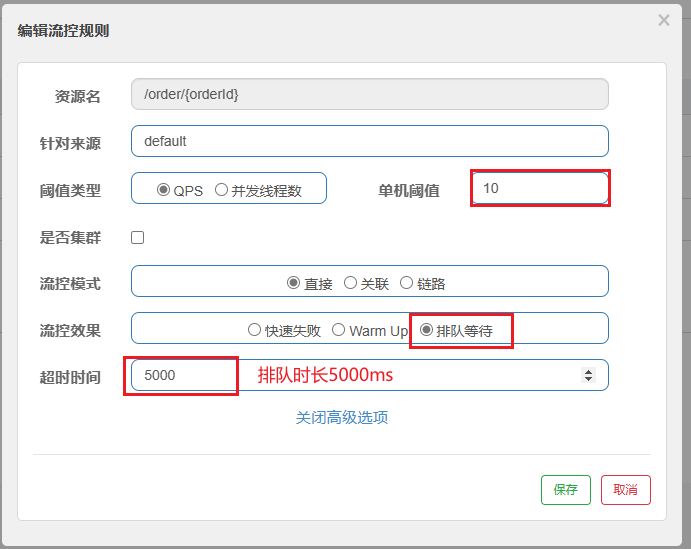
我们接下来去实现一个案例,给/order/{orderId}这个资源设置限流,最大QPS为10,利用排队的流控效果,超时时长设置为5s。
然后我们利用Jmeter进行测试
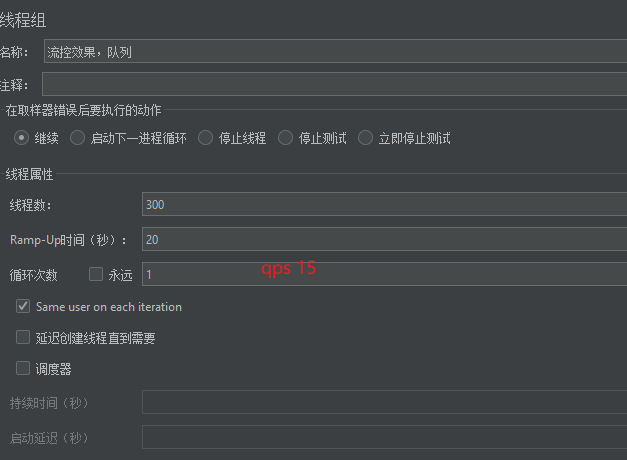
QPS为15,已经超过了我们设定的10。
如果是之前的 快速失败、warmup模式,超出的请求应该会直接报错。
但是我们看看队列模式的运行结果:
全部都通过了。
再去sentinel查看实时监控的QPS曲线:
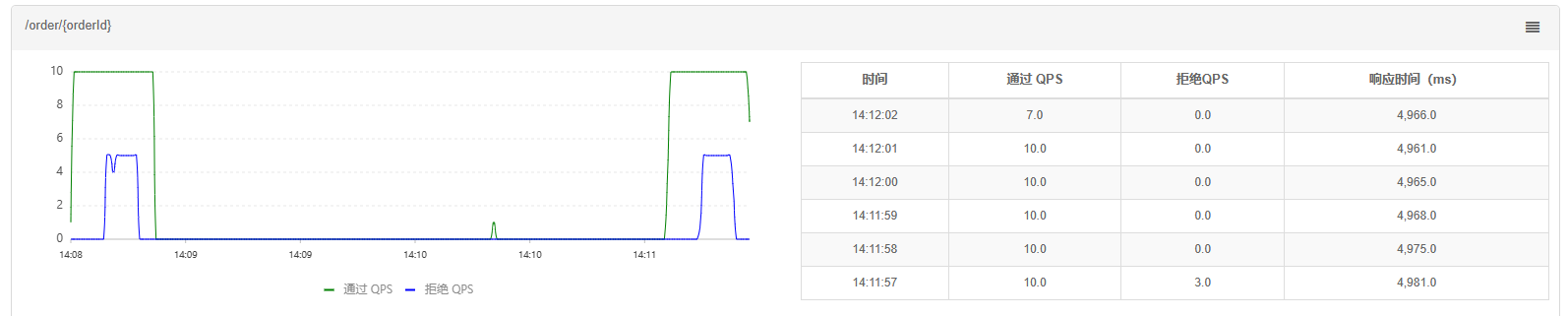
看后面那一段,QPS中间非常平滑,一致保持在10,我们发的明明是15,但通过的却是10,那多余的请求到哪里去了?是不是到队列里面等待执行去了,因此你可以看到响应时间(等待时间)会越来越长。
当队列满了以后,才会有部分请求失败。
5.4 热点参数限流
5.4.1.全局参数限流
这一章节我们来学习一个特殊的限流,热点参数限流。那它特殊在哪里呢?
我们前面所学习的限流,在去统计资源的QPS的时候,会统计进入该资源的所有请求,然后判断它有没有超过QPS阈值。
而热点参数限流是分别统计参数值相同的请求,判断它有没有超过阈值。什么意思?
比方说,我现在有一个资源是根据ID查询商品。

现在有4个请求过来了。
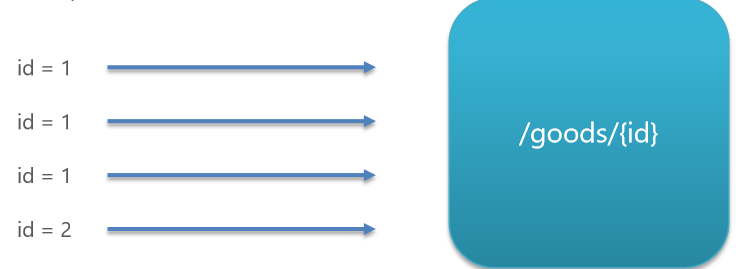
如果是按照原来的统计方式,那我的QPS就是4,而按照热点参数,它会根据参数值来去判断,那前三个的请求的ID都为1.而最后一个传递ID为2。

那QPS就会分开统计了,ID为1的统计一下为3,ID为2的统计一下为1。
配置示例:
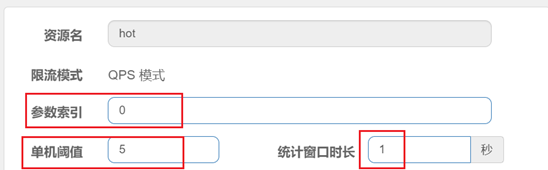
在这里比较关键的就是这三个配置,第一是参数索引,这里给了0,代表的是当前这个资源的参数列表中的第0索引,就是第一个参数。
单机阈值为5还有统计窗口时长1,这两合在一起就是指一秒钟最多五个请求。
那整个配置的含义就是给hot这个资源的0号参数(第一个参数)做统计,每1秒相同参数值的请求数不能超过5。
5.4.2.热点参数限流
刚才的配置中,对查询商品这个接口的所有商品一视同仁,QPS都限定为5.
而在实际开发中,可能部分商品是热点商品,例如秒杀商品,我们希望这部分商品的QPS限制与其它商品不一样,高一些。那就需要配置热点参数限流的高级选项了:
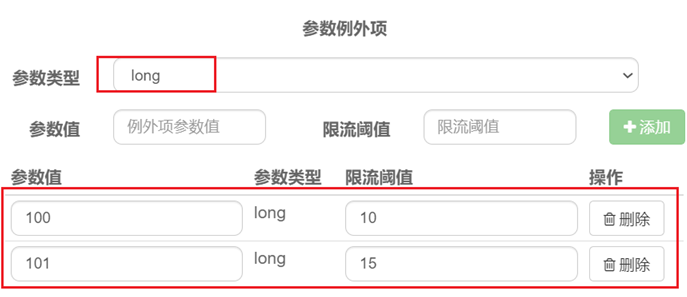
结合上一个配置,这里的含义是对0号的long类型参数限流,每1秒相同参数的QPS不能超过5,有两个例外:
•如果参数值是100,则每1秒允许的QPS为10
•如果参数值是101,则每1秒允许的QPS为15
案例:
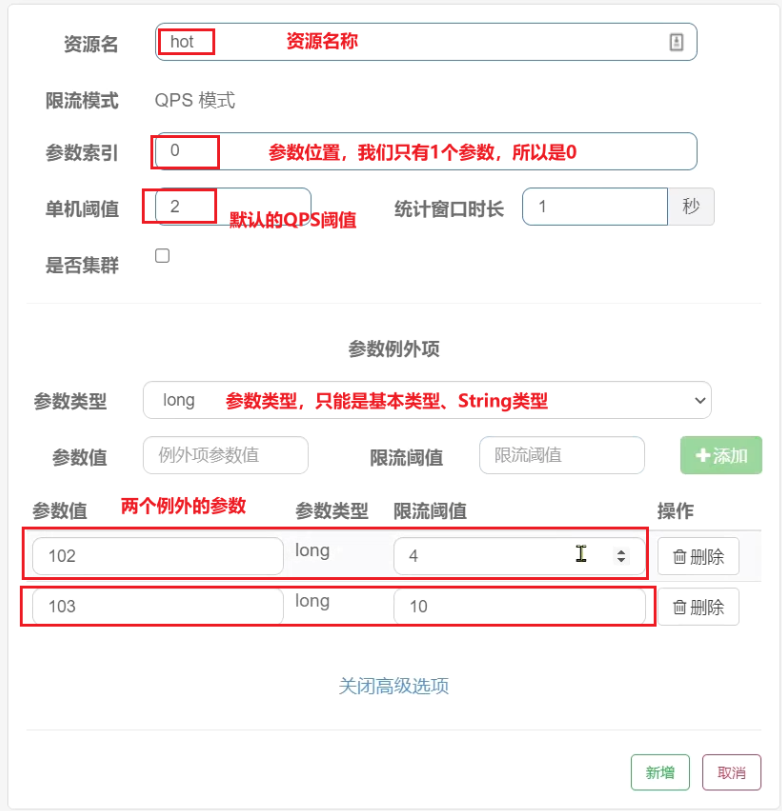
给/order/{orderId}这个资源添加热点参数限流,规则如下:
默认的热点参数规则是每1秒请求量不超过2
给102这个参数设置例外:每1秒请求量不超过4
给103这个参数设置例外:每1秒请求量不超过10
!!!!!!!
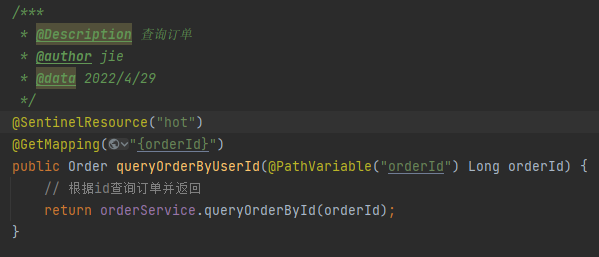
注意事项:热点参数限流对默认的SpringMVC资源无效,需要利用@SentinelResource注解标记资源!!!!!
所以我们要做的第一件事不是来配置规则,而是去修改代码添加注解。
我们先给给order-service中的OrderController中的/order/{orderId}资源添加注解。
重启一下服务。
访问该接口,可以看到我们标记的hot资源出现了:
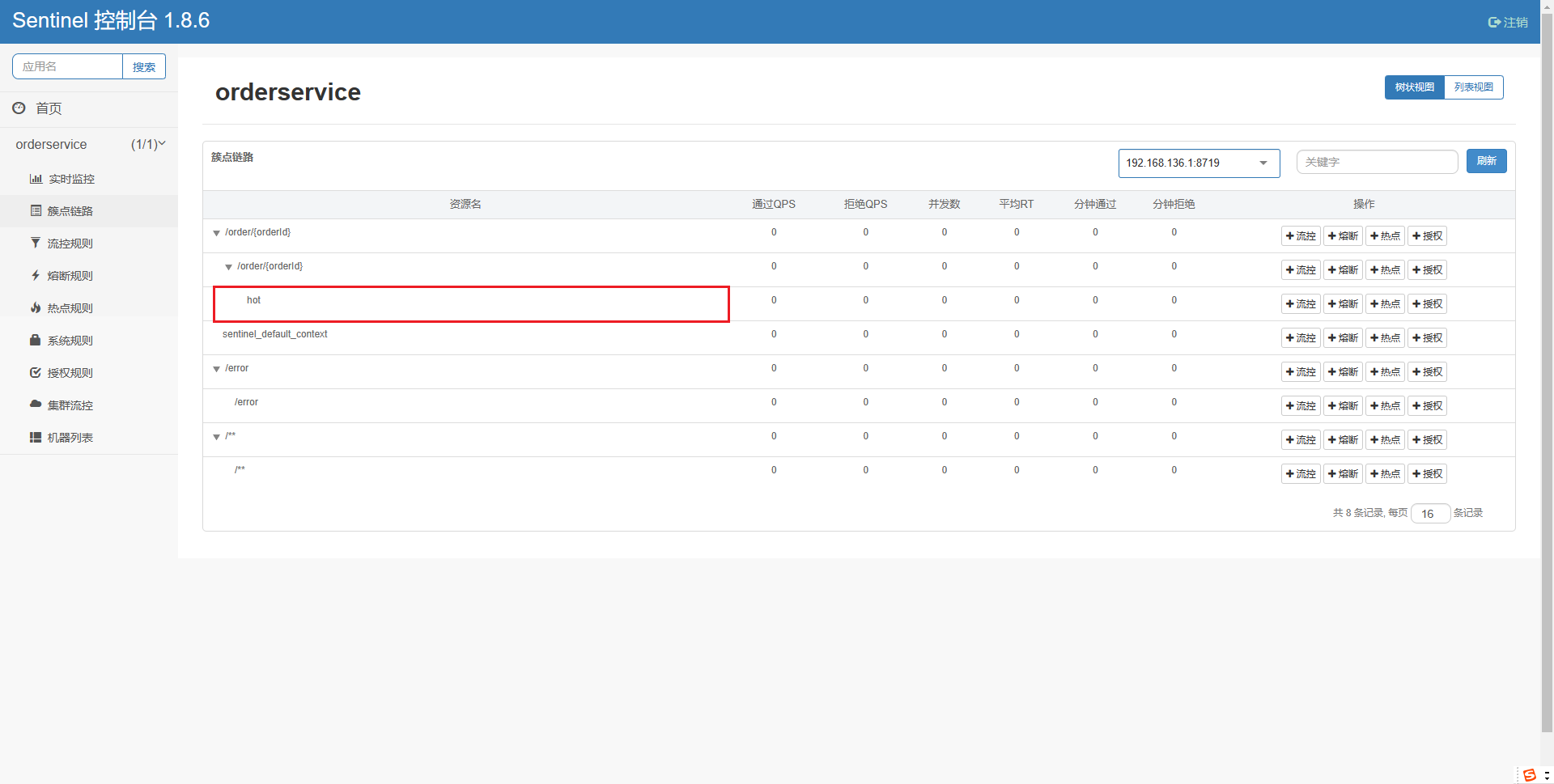
这里不要点击hot后面的按钮,页面有BUG
点击左侧菜单中热点规则菜单:
点击新增
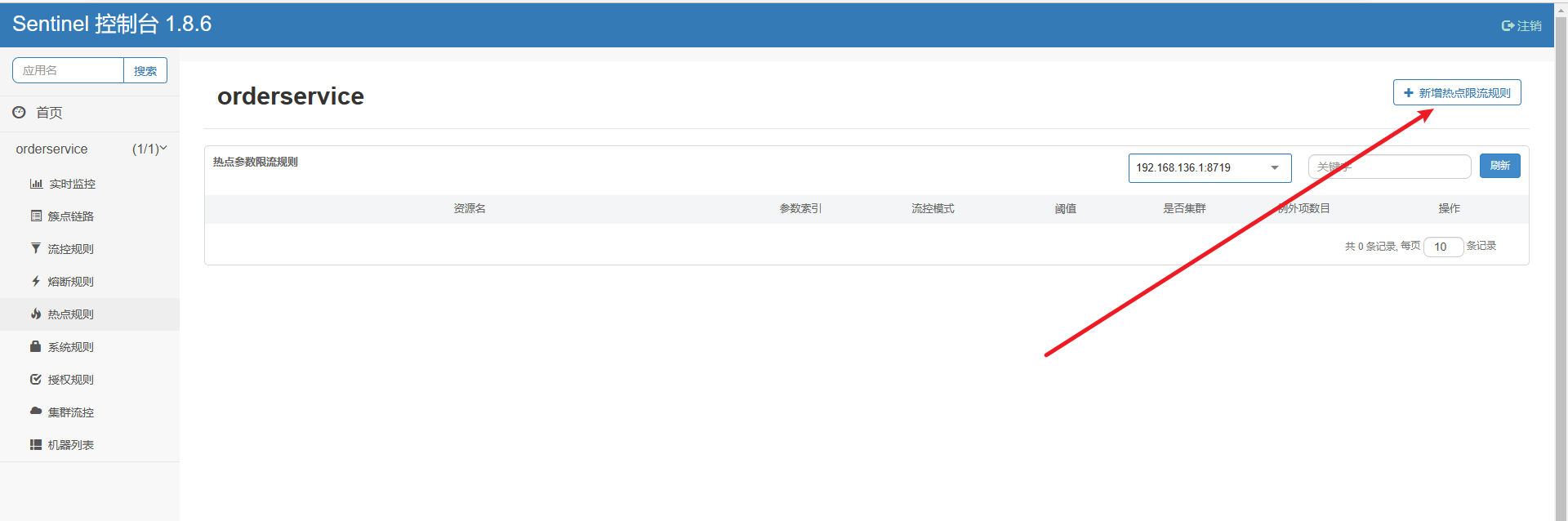
填写表单
点击新增,打开jenkins。
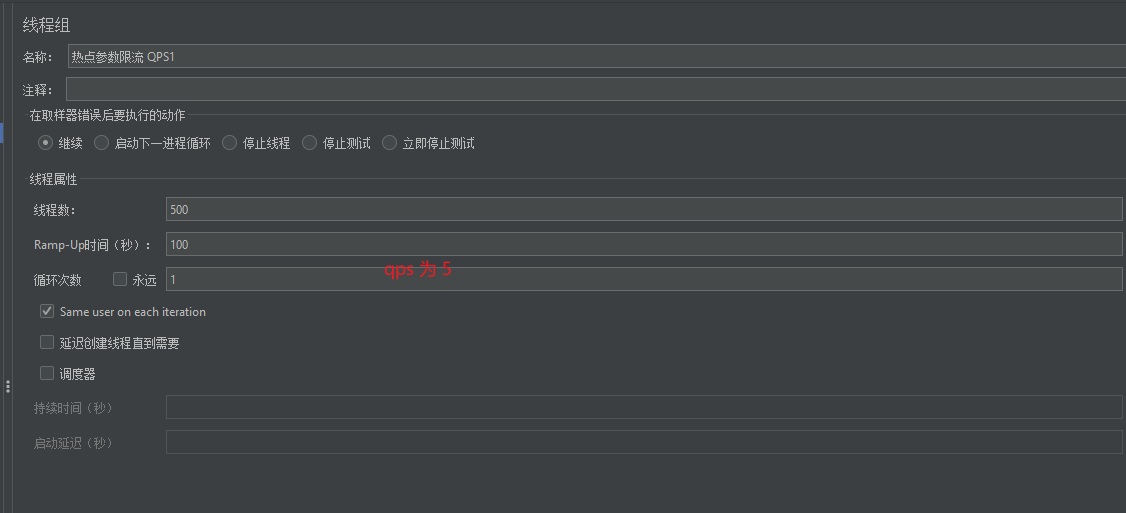
包含3个http请求:
普通参数,QPS阈值为2

运行结果:

例外项,QPS阈值为4

运行结果:
例外项,QPS阈值为10

运行结果: