背景
一致性hash
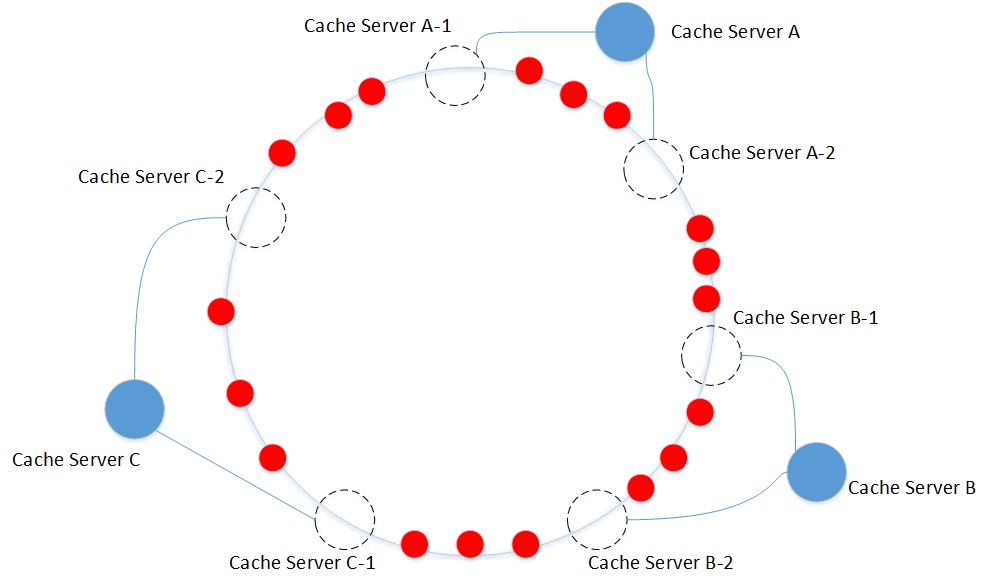
- 一致性哈希将整个哈希值空间组织成一个虚拟的圆环,将各个服务器使用Hash值进行一个哈希,比如可以选择服务器的ip或主机名进行哈希,这样每台机器就能确定其在哈希环上的位置。
- 数据定位算法是将数据key使用相同的函数Hash计算出哈希值,并确定此数据在环上的位置,从此位置沿环顺时针“行走”,第一台遇到的服务器就是其应该定位到的服务器。
- 优点:一致性哈希算法对于节点的增减都只需重定位环空间中的一小部分数据,具有较好的容错性和可扩展性。
缺点:一致性哈希算法在服务节点太少时,容易因为节点分布不均匀而造成数据倾斜问题。同时,在节点增减的过程中,也容易导致数据分布或负载不均。 - 优化:引入虚拟节点机制,将对象均匀的映射到虚拟节点,再将虚拟节点映射到物理节点,最终达到平均分布到物理节点上的效果。
分布式事务
- 指涉及到操作多个数据库的事务,其实就是将对同一数据库事务的概念扩大到了对多个数据库的事务,目的是为了保证分布式系统中的数据一致性。
- 如果想让分布式部署的多台机器中的数据保持一致性,那么就要保证在所有节点的数据写操作,要不全部都执行,要么全部都不执行。
- 当一个事务跨越多个节点时,一台机器在执行本地事务的时候无法知道其他机器中的本地事务的执行结果,因此,它也就不知道本次事务到底应该commit还是 roolback,为了保持事务的ACID特性,需要引入一个作为协调者的组件来统一执行。
二阶段提交(2PC)
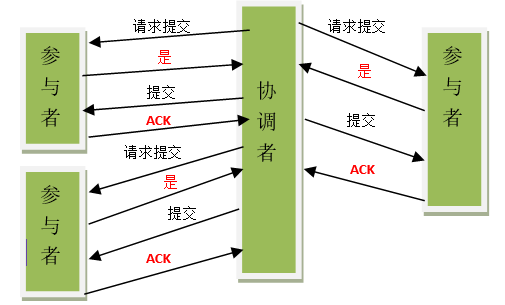
参与者将操作成败通知协调者,再由协调者根据所有参与者的反馈情报决定各参与者是否要提交操作还是中止操作。
准备阶段
事务协调者给每个参与者发送Prepare消息,每个参与者要么直接返回失败(如权限验证失败),要么在本地执行事务,写本地的redo和undo日志,但不提交,到达一种“万事俱备,只欠东风”的状态。
提交阶段
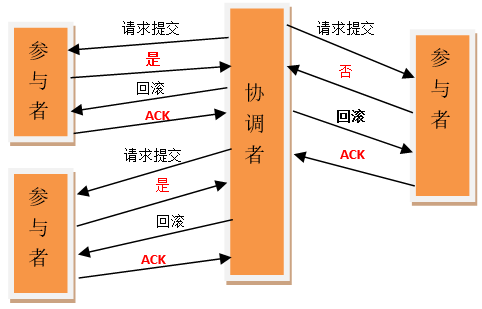
如果协调者收到了参与者的失败消息或者超时,直接给每个参与者发送回滚(Rollback)消息,否则,发送提交(Commit)消息。参与者根据协调者的指令执行提交或者回滚操作,释放所有事务处理过程中使用的锁资源。
二阶段提交的问题
同步阻塞问题:执行过程中,所有参与节点都是事务阻塞型的。
单点故障:一旦协调者发生故障。参与者会一直阻塞下去。尤其在提交阶段,协调者发生故障,那么所有的参与者还都处于锁定事务资源的状态中,而无法继续完成事务操作。
数据不一致:在提交阶段,当协调者向参与者发送commit请求之后,发生了局部网络异常或者在发送commit请求过程中协调者发生了故障,这会导致只有一部分参与者接受到了commit请求,而在这部分参与者接到commit请求之后就会执行commit操作, 但是其他部分未接到commit请求的机器则无法执行事务提交,于是整个分布式系统便出现了数据不一致的问题。
脑裂(二阶段无法解决的问题):协调者再发出commit消息之后宕机,而唯一接收到这条消息的参与者同时也宕机了,那么即使协调者通过选举协议产生了新的协调者,这条事务的状态也是不确定的,没人知道事务是否被已经提交。
三阶段提交(3PC)
三阶段提交(Three-phase commit),是二阶段提交(2PC)的改进版本,三阶段提交相对二阶段提交有两个改动点:
引入超时机制:同时在协调者和参与者中都引入超时机制。
在第一阶段和第二阶段中插入一个准备阶段:保证了在最后提交阶段之前各参与节点的状态是一致的。
CanCommit阶段
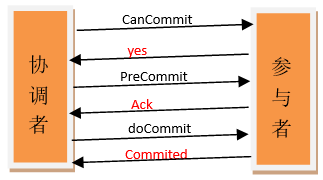
事务询问:协调者向参与者发送CanCommit请求。询问是否可以执行事务提交操作。然后开始等待参与者的响应。
响应反馈:参与者接到CanCommit请求之后,正常情况下,如果其自身认为可以顺利执行事务,则返回Yes响应,并进入预备状态,否则反馈No。
PreCommit阶段
协调者根据参与者的反应情况来决定是否可以记性事务的PreCommit操作,根据响应情况,有以下两种可能:
1.假如协调者从所有的参与者获得的反馈都是Yes响应,那么就会执行事务的预执行。
发送预提交请求:协调者向参与者发送PreCommit请求,并进入Prepared阶段。
事务预提交:参与者接收到PreCommit请求后,会执行事务操作,并将undo和redo信息记录到事务日志中。
响应反馈:如果参与者成功的执行了事务操作,则返回ACK响应,同时开始等待最终指令。
2.假如任何一个参与者向协调者发送了No响应,或者等待超时之后,协调者都没有接到参与者的响应,那么就执行事务的中断。
发送中断请求:协调者向所有参与者发送abort请求。
中断事务:参与者收到来自协调者的abort请求之后(或超时之后,仍未收到协调者的请求),执行事务的中断。
doCommit阶段
该阶段进行真正的事务提交,也可以分为以下两种情况:
1.执行提交
发送提交请求:协调接收到参与者发送的ACK响应,那么他将从预提交状态进入到提交状态。并向所有参与者发送doCommit请求。
事务提交:参与者接收到doCommit请求之后,执行正式的事务提交。并在完成事务提交之后释放所有事务资源。
响应反馈:事务提交完之后,向协调者发送Ack响应。
完成事务:协调者接收到所有参与者的ack响应之后,完成事务。
2.中断事务
发送中断请求:协调者向所有参与者发送abort请求
事务回滚:参与者接收到abort请求之后,利用其在PreCommit阶段记录的undo信息来执行事务的回滚操作,并在完成回滚之后释放所有的事务资源。
反馈结果:参与者完成事务回滚之后,向协调者发送ACK消息。
中断事务:协调者接收到参与者反馈的ACK消息之后,执行事务的中断。
3.说明
在doCommit阶段,如果参与者无法及时接收到来自协调者的doCommit或者rebort请求时,会在等待超时之后,会继续进行事务的提交。
其实这个应该是基于概率来决定的,当进入第三阶段时,说明参与者在第二阶段已经收到了PreCommit请求,那么协调者产生PreCommit请求的前提条件是他在第二阶段开始之前,收到所有参与者的CanCommit响应都是Yes。所以,一句话概括就是,当进入第三阶段时,由于网络超时等原因,虽然参与者没有收到commit或者abort响应,但是他有理由相信:成功提交的几率很大。
2PC与3PC的区别
相对于2PC,3PC主要解决的是单点故障问题,并减少阻塞,因为一旦参与者无法及时收到来自协调者的信息之后,他会默认执行commit。而不会一直持有事务资源并处于阻塞状态。但是这种机制也会导致数据一致性问题,因为,由于网络原因,协调者发送的abort响应没有及时被参与者接收到,那么参与者在等待超时之后执行了commit操作。这样就和其他接到abort命令并执行回滚的参与者之间存在数据不一致的情况。
了解了2PC和3PC之后,我们可以发现,无论是二阶段提交还是三阶段提交都无法彻底解决分布式的一致性问题。Google Chubby的作者Mike Burrows说过, there is only one consensus protocol, and that’s Paxos” – all other approaches are just broken versions of Paxos. 意即世上只有一种一致性算法,那就是Paxos,所有其他一致性算法都是Paxos算法的不完整版。
paxos
paxos是分布式环境下强一致性算法,它在2PC上至少有两点改进:
1. 不存在说网路问题导致事务阻塞甚至失败,尤其是连接coordinator的,因为paxos的角色是可以互串的,必要时participant也能充当coordinator。
2. 加在任何一个在1b、2b阶段投了赞成票的participant上的锁是可以被砸开的,只要新提案的编号更大,这样就提高吞吐量了,当然频繁的产生新proposer可能会导致活锁,永远无法达成协议,最好设置一个超时机制,过了超时时间才产生一个proposer。
basic paxos

算法流程
1) proposer选中一个提议编号n,设置提议值value。
2) 将提议消息Prepare(n)发送到所有的acceptor上,等待acceptr的响应,这个过程中设置提议超时时间。
3) acceptor收到proposer发送的Prepare消息后,做如下处理:if (提议编号n > minProposal){ minProsal = n; }else{ return ; //do not send response,proposer timeout。 } return response{ AcceptedProposal, AcceptedValue }``4) proposer判断是否收到大多数acceptor的响应消息,如果是,则做如下处:
for (res in responses){ if (res.AcceptedValue){ choose AcceptedValue with max AcceptedProposal } } if (AcceptedValue){ value = AcceptedValue }5) 将Accept(n,value)消息发送到所有acceptor。
6) acceptor收到proposer发送过来的accept消息后,做如下处:if (n >= minProposal){ AcceptedProPosal = minProposal = n AcceptedValue = value } return minProposal7) 判断是否收到大多数acceptor的响应消息,如果是,则做如下处理:
for (res in responses){ if (res.minProposal > n){ goto 1) }else{ confirm chosen value } }
实际工程场景
- 如果一个提议发起之前,对应的值已经被大多数Accept,那么这个提议必须使用已经被Accept的值。

- 如果之前提议的值已经被部少分节点Accept,但是还没有被选中。新的提议可以看到之前少部分节点Accept的值。则这个Accept的值会作为新的提议Accept请求的值。

- 如果之前的提议被部分节点Accept,但是还没有被选中。新的提议看不到之前提议的Accept的值。则新的提议的Accept的请求会使用自己的值。

活锁问题

解决方法
1.每次失败后,重新发起提议前,随机delay一段时间。
2.通过Leader选举,只有Leader有权发起提议。
总结
- proposer可以有多个。
- proposer并不需要发送propose到全部acceptor,也可以发送到部分acceptor,只要有半数以上的acceptor通过即可。
- 第二阶段的时候client仍需要等着,只有在第二阶段大半acceptor返回accepted后,client才能得到成功的信息。
- 存在活锁的问题。
multi paxos
multi-paxos协议中有一个Leader,Leader是系统中唯一的Proposal,在lease租约周期内所有提案都有相同的ProposalId,可以跳过prepare阶段,议案只有accept过程,一个ProposalId可以对应多个Value。
一阶段a:发起者(leader)直接告诉Acceptor,准备递交协议号为I+1的协议
一阶段b:收到了大部分acceptor的回复后(图中是全部),acceptor就直接回复client协议成功写入
leader选举
选主实质也是一次确定“谁是leader”这个值的Paxos算法的过程,由于任何一个节点都可以发起提议,在并发情况下,可能会出现多主的情况,比如A,B先后当选为leader。因此,当选leader的节点需要根据多数派原则写一条特殊日志(start-working日志)确认其身份,只有一个leader的startworking日志可以达成多数派。
选出leader后,leader可以通过lease机制(租约)维持自己的leader身份,其它proposal不再发起提案,由于没有并发冲突,因此可以直接进入accept阶段,leader任期内的所有日志都只需要一个网络RTT(Round Trip Time)即可达成一致。
新主恢复
由于Paxos中没有限制,任何节点都可以参与选主并最终成为leader,无法保证新选出的leader包含所有日志,可能存在空洞,需要经过一个获取所有已提交日志的恢复过程后,才能真正提供服务。
1)新主向所有成员查询最大logId的请求,收到多数派响应后,选择最大的logId作为日志恢复结束点。
2)拿到日志恢复结束点的logId后,从头开始对每个logId逐条进行paxos协议,在新的leader获得所有日志之前,系统无法提供服务。
confirm机制
如果日志非常多,每次重启后对每条日志做一次paxos,那么新leader恢复时间会非常,因此引入了confirm机制,缩短新leader的恢复时间。
在paxos协议中,只有主即proposer知道哪些日志达成了一致,因此,proposer可以将已经达成一致的日志id告诉其他acceptor,acceptor写一条确认日志到日志文件中。后续重启的时候,扫描本地日志只要发现对应的确认日志就知道这条日志已经达成多数派,不需要重新使用paxos进行确认了。
confirm机制的问题
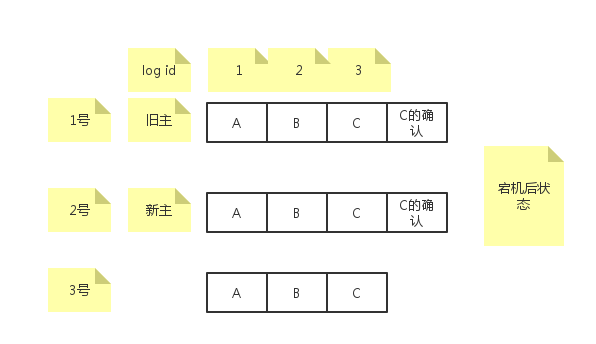
旧主给自己和2号成员发送了确认日志,但是在给3号成员发送成功前旧主挂了,然后2号成员被选为新主,新主不会对log id=3的日志重新运行paxos,因为本机已经存在确认日志。
解决这个问题的做法就是followers主动向主询问日志到底有没有达成一致,如果有缺失的未达成一致日志,则自己补充确认日志。
“幽灵复现”日志

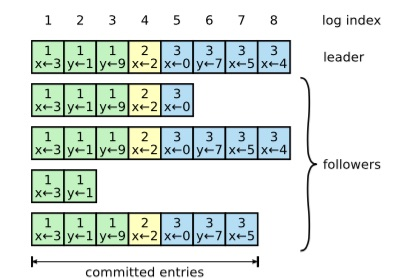
1) 第一轮,A被选为Leader,写下了1-10号日志,其中1-5号日志形成了多数派,并且已给客户端应答。
2) 第二轮,A宕机,B被选为Leader,B和C的最大的logID都是5,B不会去重确认6-10号日志,后续会从6开始写新的日志,此时如果客户端查询不到6-10号日志内容,此后,又写入了6-20号日志,但是只有6号和20号日志在多数派上持久化成功。
3) 第三轮,A又被选为Leader,从多数派中可以得到最大logID为20,因此,要重确认7~20号日志,其中就包括A上的7-10号日志,之后,客户端会发现上次查询不到的7-10号日志像幽灵一样出现了。
为了处理“幽灵复现”问题,可以在每条日志的内容中保存一个generateID,leader在生成每条日志时以当前的leader ProposalID作为generateID,当按logID顺序回放日志时,由于leader在开始服务之前一定会写一条StartWorking日志,所以如果出现generateID相对前一条日志变小的情况,说明这是一条“幽灵复现”日志(它的generateID会小于StartWorking日志),需要忽略掉这条日志。
raft vs multi-paxos
- raft仅允许日志最多的节点当选为leader,而multi-paxos允许任意节点都可以当选leader。
multi-paxos则允许日志出现空洞,而raft为了比较的方便和便于拉平两个节点的日志,不允许日志出现空洞。
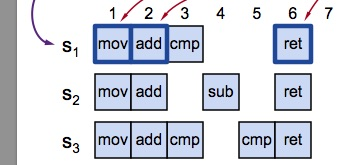
multi-paxos的leader只是知道最大的log index是多少,但是空洞部分,可以异步填充,而raft的leader,不但知道最大的log index是多少,也必须拥有从0到log index直接的之间日志,在被选择为leader后,raft的leader可以单向的向其他follower节点同步落后的日志,log只会从leader到follower单向同步
由于raft不允许日志的空洞,因此方便了比较和拉平两个节点的日志,同时,这种连续确认更大的一个优势是新的leader上任过程更简单了,而Multi Paxos的新leader上任过程很复杂。
paxos中一开始没有包含全部已提交的条目的节点也可以被选为leader,在当选为leader后需要有一些另外的机制来保证找到丢失的条目,这种方式大大增加了复杂性。而Raft协议的选举过程中,日志落后的候选节点无法被选中为Leader,这大大减小了选举和日志复制的相关性,简化了raft的算法理解难度。
ceph monitor中multi paxos的工程实现
Leader选举
leader选举时序图
Recovery
在Leader选举成功后,Leader和Peon都会进入Recovery阶段。Recovery阶段的目的是为了保证新Quorum的所有成员状态一致,这些状态包括:最后一个批准(Committed)的提案,最后一个没批准的提案,最后一个接受(Acceppted)的提案。
对旧Quorum的所有成员来说,最后一个通过的提案应该都是相同的,但对不属于旧Quorum的成员来说,它的最后一个通过的提案是落后的。

Recovery阶段恢复流程:
- leader生成新的更大的新的pn,并通过collect消息发送给所有的quorum中成员。
- 收到collect消息的节点,判断当pn大于自己已经accept的最大pn时,接受并通过last消息返回自己的commit位置及uncommitted位置。
- leader收到last消息,更新自己的commit位置及数据,如果last中的pn大于leader的accepted_pn,则更新leader的accpted_pn,并基于last中pn值发送collect消息,直到quorum中所有的节点accepted_pn相同。
- leader会根据收到last消息中commit及uncommitted位置,分别用commit消息和begin消息更新对应的peon。
- leader向quorum中所有节点发送lease消息,使整个集群进入active状态。
Lease
经过了上面的初始化、选主、恢复阶段,整个集群进入到一个非常正常的状况,就可以利用Paxos进行一致性地读写,其中读过程比较简单,在lease内的所有quroum均可以提供服务,而所有的写都会转发给leader。

Lease阶段写入流程:
- leader在本地记录要提交的value,并向quroum中的所有节点发送begin消息,其中携带了要提交的value, accept_pn及last_commit。
- peon收到begin消息,如果accept过更高的pn则忽略,否则将value写入db并返回accept消息。同时,peon会将当前的lease过期掉,在下一次收到lease前不再提供服务。
- leader收到全部quorum的accept后进行commit,本地commit后向所有quorum节点发送commit消息。
- peon收到commit消息,本地commit数据。
- leader通过lease消息将整个集群带入到active状态。
参考文档
[Paxos三部曲之一] 使用Basic-Paxos协议的日志同步与恢复
[Paxos三部曲之二] 使用Multi-Paxos协议的日志同步与恢复
[Paxos三部曲之三] Paxos成员组变更
ceph中log实现
Ceph Monitor源码机制分析(三)—— 选举