计算和人才的增加使强化学习(RL)研究成为机器学习的热门领域 - 它已被用于解决自动驾驶汽车,机器人技术,药物发现等方面的问题。但是,找到一种方法来重现现有工作并准确评估迭代改进仍然是RL面临的一项艰巨挑战。
为了保持RL的发展势头,来自Machine Zone,Google Brain和California Institute of Technology的一组研究人员推出了一种新的软件框架和基准,用于可重复的强化学习研究。
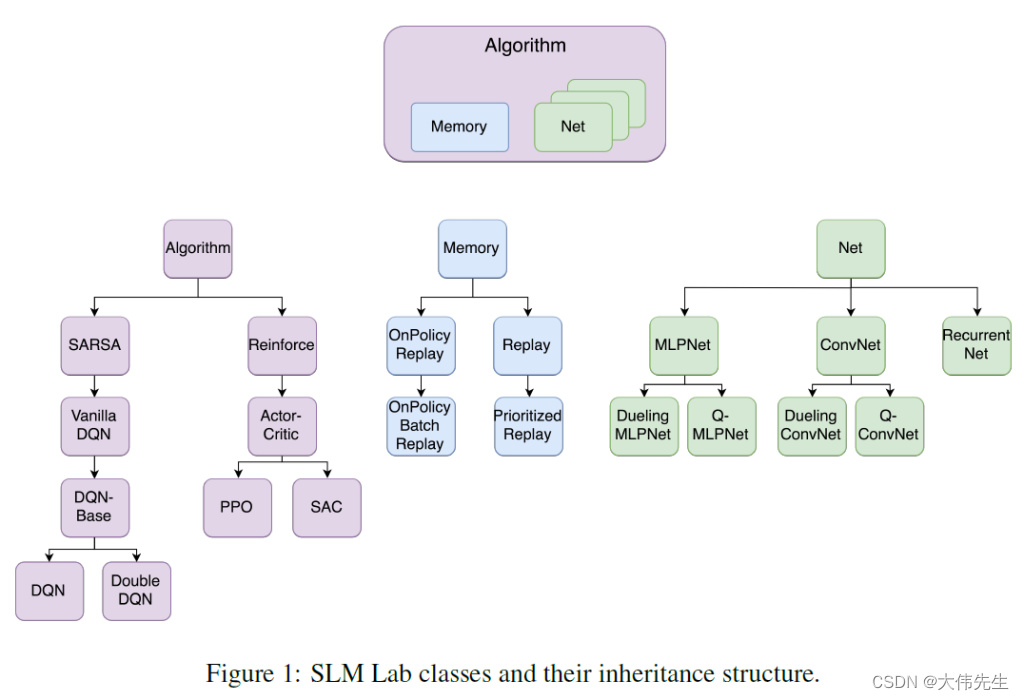
“SLM Lab”是PyTorch中的一个模块化深度强化学习框架。研究人员解释说,当两种RL算法只有很小的差异时,运行每种算法的独立实现然后比较相对性能可能会产生不清楚的性能分析。因此,他们选择在SLM实验室中模块化地实现RL算法,因此性能的差异可以自信地归因于算法之间的差异,而不是实现之间的差异。
该团队还表示,模块化代码可能对研究目的有益,因为它使新的RL算法的实现更容易。模块化是SLM实验室的核心,其RL算法在三个基类中定义:
1、算法:处理与环境的交互,实现操作策略,计算特定于算法的损失函数,并运行训练步骤。
2、网络:实现用作算法函数近似器的深度网络。
3、内存:提供训练所需的数据存储和检索。
正如实现会导致 RL 算法的性能差异显著一样,环境和超参数设置等其他因素也是如此。为了帮助用户更好地了解各种设置和性能差异,该团队以结构化的“会话-试验-实验”顺序组织实验。在 SLM Lab 中,在环境中单次运行算法是“会话”,而会话集合包含试用。试验是具有各种算法和环境的试验的集合。该团队还在规范文件中为算法指定了每个可配置的超参数。


该团队在 62 款 Atari 游戏、11 款通过 OpenAI 健身房的 Roboschool 环境和 4 个 Unity 环境中测试了这些算法。每 10k 或 1k 训练帧,环境中的代理就会被检查点。结果表示在前 100 个训练检查点上每次训练平均后每集的分数。研究人员解释说,这种测量更适合显示平均性能,而不是跟踪剧烈的性能变化。
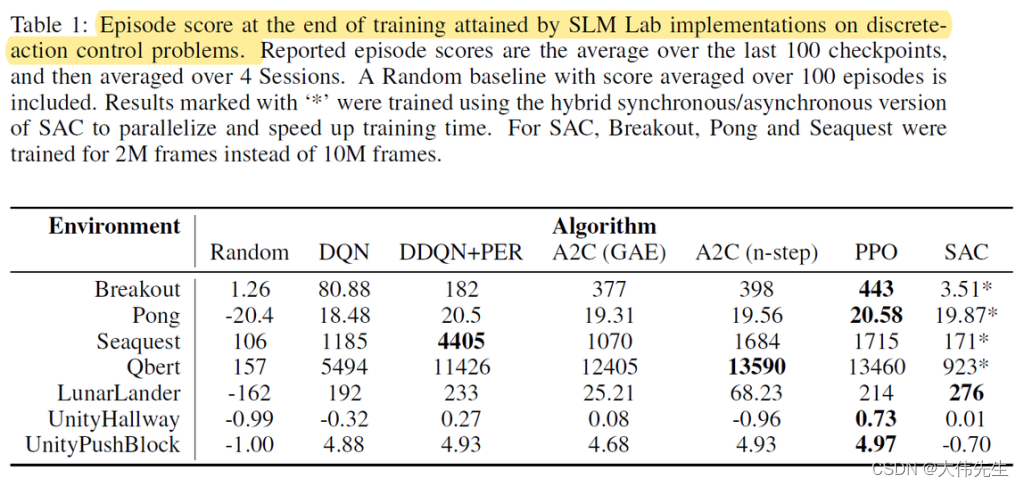
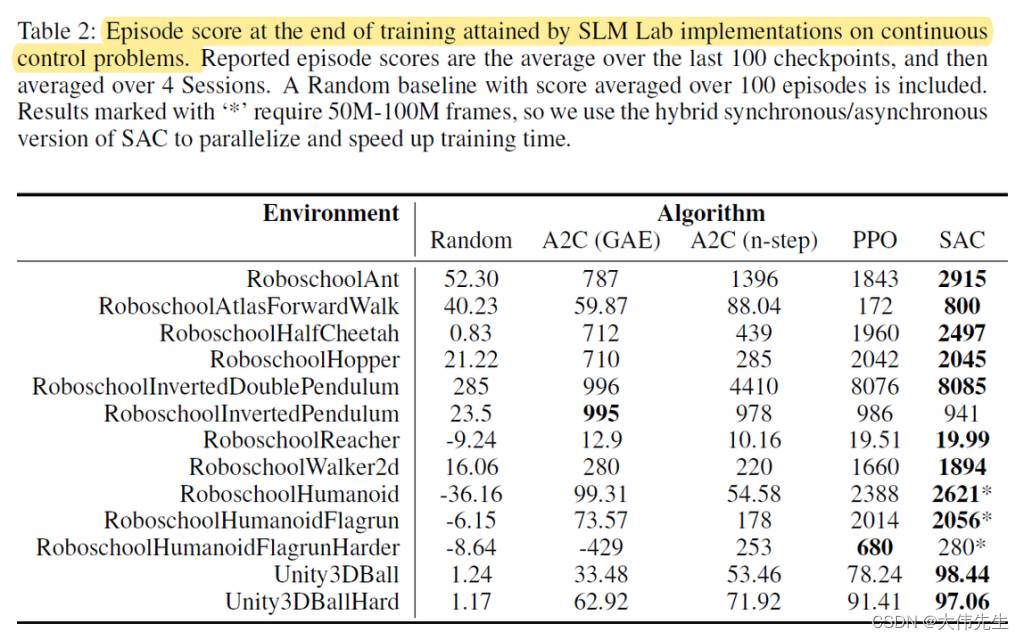
在Atari游戏中对DQN和DDQN + PER算法的实验产生了不同的性能结果,而PPO和A2C算法的结果与OpenAI之前所做的工作相似。实验还证实了SAC算法相对于PPO在连续控制问题上的强度。研究人员指出,计算约束可能是导致不同结果的一个因素。
展望未来,随着RL继续快速发展,研究人员实施新算法并发布新结果,SLM实验室为RL研究社区提供了一个有用的新工具来检查算法和可重复性。
Synced之前报道了一些相关研究 - DeepMind的Bsuite,这是一组实验,旨在评估RL代理的核心功能,并帮助研究人员更好地了解它们在各种应用程序中的优缺点。论文强化学习行为套件(Bsuite)使用清晰,信息丰富且可扩展的问题,通过在基准上观察RL代理行为来研究不同学习算法的核心问题。
论文SLM Lab:用于可重现深度强化学习的综合基准和模块化软件框架发表在arXiv上。SLM Lab 可以从 GitHub 安装。