今天我们来获取古诗词网站的一些古诗词来提供给孩子们学习
PS前面几节课的内容在专栏这里,欢迎大家考古:点我
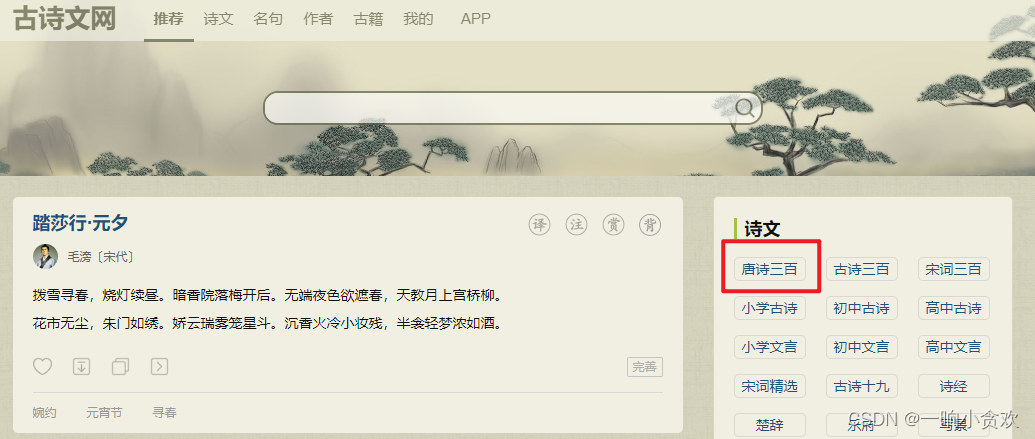
首先我们看一下网站:点我,今天我们来获取一下【唐诗三百首】
第 1 步:网页分析
在网页中我们发现有许多以古诗词名字作为链接的 URL
我们第一步是获取到【唐诗三百】网页中所有的古诗词 链接
代码1(获取所有的古诗词链接)
import requests
url = requests.get("https://so.gushiwen.cn/gushi/tangshi.aspx")
# url.encoding= "gbk"
# print(url.text)
data = url.text
print(data)
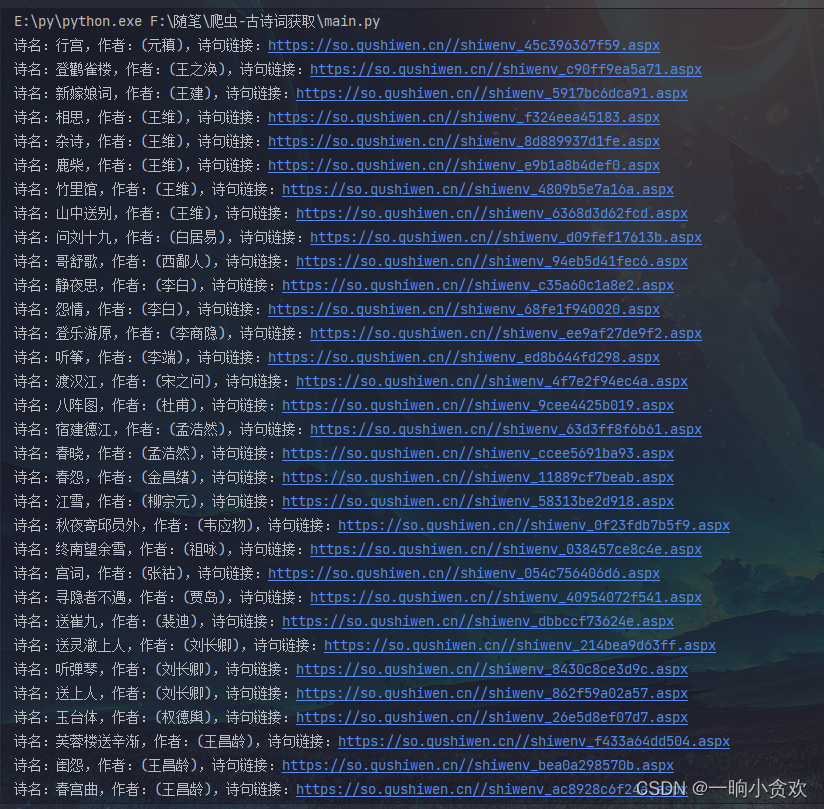
这里我们发现确实可以获取到所有的链接


第2 步:代码2(数据清洗)
import re
import requests
url = requests.get("https://so.gushiwen.cn/gushi/tangshi.aspx")
data = url.text
data2 = re.findall(r'<span><a href="(.*?)" target="_blank">(.*?)</a>(.*?)</span>',data)
for i in data2:
print(f'诗名:{
i[1]},作者:{
i[2]},诗句链接:https://so.gushiwen.cn/{
i[0]}')
第 3 步:请求链接URL+数据清洗,获取诗词(完整代码)
import re
import requests
url = requests.get("https://so.gushiwen.cn/gushi/tangshi.aspx")
data = url.text
# print(data)
data2 = re.findall(r'<span><a href="(.*?)" target="_blank">(.*?)</a>(.*?)</span>',data)
# print(data2)
for i in data2:
url2 = 'https://so.gushiwen.cn/'+i[0]
data2 = requests.get(url2).text
# print(data2)
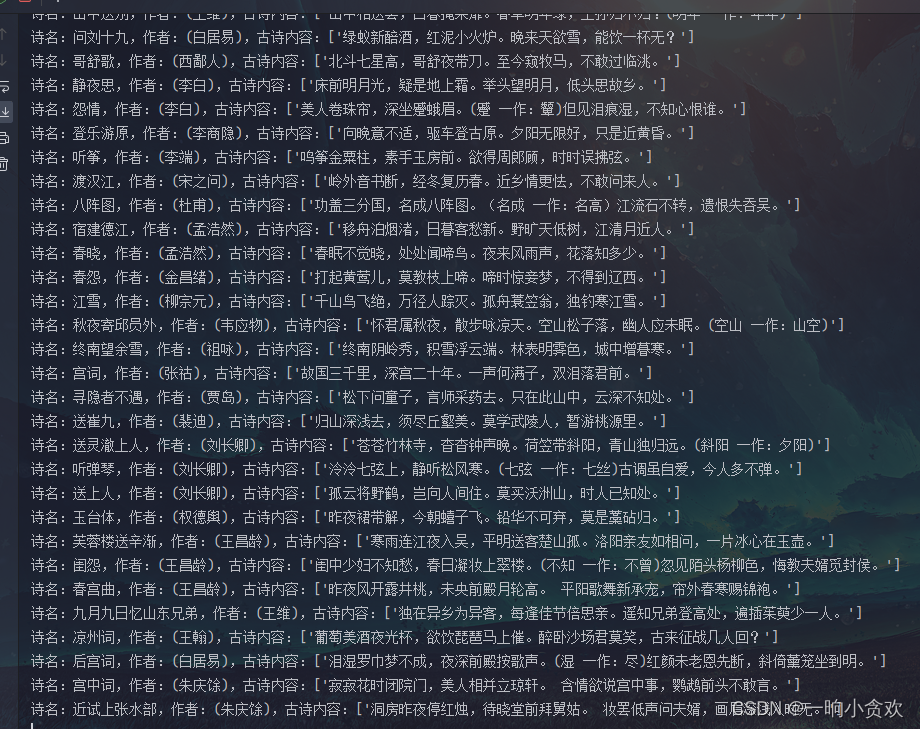
gushi = re.findall('name="description" content="(.*?)" /',data2)
# print(gushi)
# print(f'诗名:{i[1]},作者:{i[2]},诗句链接:https://so.gushiwen.cn/{i[0]}')
print(f'诗名:{
i[1]},作者:{
i[2]},古诗内容:{
gushi}')
搞定:
1、 其实代码到这,大家可以继续数据清洗,从网页中清洗出【译文及注释】、【赏析】、【创作背景】、【作者介绍】等等,这里就当布置一个小作业,大家回去后可以继续完善
2、 大家可以将获取的古诗词写入word(用到的库是
python-docx),可以写入txt,可以写入Excel(用到的库是openpyxl)我这里就不存了,如果你在存入的途中有任何问题,都可以咨询我。。虽然我技术也不高。。但是只要我会就一定告诉你。。。