在分布式开发中,Redis 的使用还是比较多的,因为它的高性能、高并发,能轻松支持几万的QPS。在这里做个总结,让大家不只会简单 Set 和 Get 操作。
一、Redis 是什么?
Redis 是一个开源(BSD许可)的,内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件。 它支持多种类型的数据结构,如 字符串(strings), 散列(hashes), 列表(lists), 集合(sets), 有序集合(sorted sets) 与范围查询, bitmaps, hyperloglogs 和 地理空间(geospatial) 索引半径查询。 Redis 内置了 复制(replication),LUA脚本(Lua scripting), LRU驱动事件(LRU eviction),事务(transactions) 和不同级别的 磁盘持久化(persistence), 并通过 Redis哨兵(Sentinel)和自动 分区(Cluster)提供高可用性(high availability)。
归结成一句话:Redis 是一个基于内存的高性能 K-V数据库,支持丰富的数据类型(strings,hashes, lists ,sets,sorted sets等)。
二、Redis为什么这么快?
先看下阿里云对Redis QPS的测试结果

单线程的Redis为什么能支持10w+的QPS?
主要是三个方面:
- 纯内存操作
- 单线程操作,避免了多线程情况下的上下文切换问题
- 采用了非阻塞I/O多路复用机制
这里重点说下非阻塞I/O多路复用机制。
非阻塞I/O多路复用
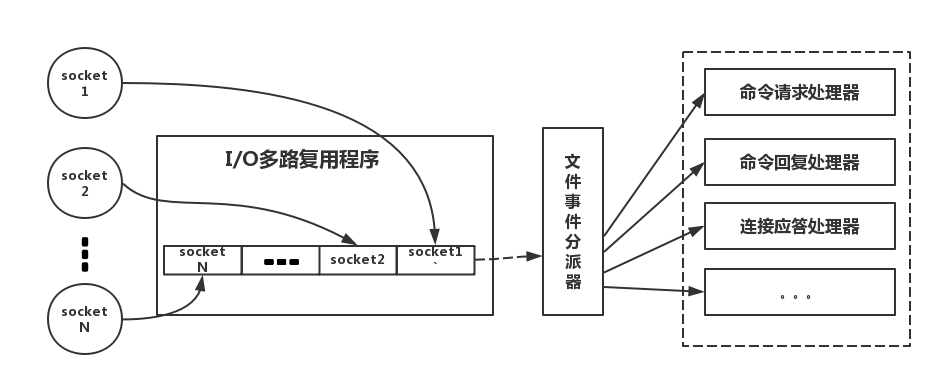
参照上图,简单来说,Redis 使用基于 Reactor 模式实现的网络通信,使用 I/O 多路复用程序来同时监听多个socket,将其置入队列之中,然后文件事件分派器,依次从队列中取,转发到不同的事件处理器中。
三、常用数据类型及对应场景
| 类型 |
特点 |
使用场景 |
| strings | 最基本的类型,value可以是String也可以是数字,最大能存储 512MB。 常用命令:get、set、incr、decr、mget等 |
缓存、原子计数器等 |
| hashes | 一个字符串字段和字符串值之间的映射,hash特别适合用于存储对象 |
用一个对象来存储数据(比如用户信息) |
| lists | 有序可重复列表,按照插入顺序排序, |
简单的消息队列 |
| sets | 无序不可重复列表 |
全局去重 |
| sorted sets | 每个元素带有分值的有序集合 |
排行榜应用,取TOP N操作 |
四、Redis持久化
Redis 提供了不同级别的持久化方式:
- RDB持久化方式能够在指定的时间间隔能对你的数据进行快照存储.
- AOF持久化方式记录每次对服务器写的操作,当服务器重启的时候会重新执行这些命令来恢复原始的数据,AOF命令以redis协议追加保存每次写的操作到文件末尾.Redis还能对AOF文件进行后台重写,使得AOF文件的体积不至于过大.
- 如果你只希望你的数据在服务器运行的时候存在,你也可以不使用任何持久化方式.
- 你也可以同时开启两种持久化方式, 在这种情况下, 当redis重启的时候会优先载入AOF文件来恢复原始的数据,因为在通常情况下AOF文件保存的数据集要比RDB文件保存的数据集要完整.
RDB和AOF持久化方式的区别:
RDB
RDB持久化是将Reids在内存中的数据库记录定时dump到磁盘上的RDB进行持久化。
优点:
1、RDB在保存RDB文件时父进程唯一需要做的就是fork出一个子进程,接下来的工作全部由子进程来做,父进程不需要再做其他IO操作,所以RDB持久化方式可以最大化redis的性能.
2、与AOF相比,在恢复大的数据集的时候,RDB方式会更快一些.
缺点:
RDB是以时间为单位存储的,如每隔5分钟或者更久做一次完整的保存,万一在Redis意外宕机,你可能会丢失几分钟的数据。
AOF
AOF持久化是将Reids的操作日志以追加的方式写入文件。
优点:
1、使用AOF 会让你的Redis数据更加安全: 你可以使用不同的fsync策略:无fsync,每秒fsync,每次写的时候fsync.使用默认的每秒fsync策略,Redis的性能依然很好(fsync是由后台线程进行处理的,主线程会尽力处理客户端请求),一旦出现故障,你最多丢失1秒的数据.
2、Redis 可以在 AOF 文件体积变得过大时,自动地在后台对 AOF 进行重写
缺点:
对于相同的数据集来说,AOF 文件的体积通常要大于 RDB 文件的体积。
五、过期Key处理策略
Redis对过期的key,有两种清除方式:定期删除+惰性删除。
定期删除策略:Redis默认每隔100ms随机抽取一些设置了过期时间的key,检查是否过期,如果过期就删除。(会导致很多key到时间,就不会删除)
惰性删除策略:获取某个key的时候,redis会先检查一下,这个key如果设置了过期时间那么是否过期了?如果过期了此时就会删除。(如果一直不请求某个key,那么这个key会一直保存)
按照上面的分析,一些过期的key会被遗漏清除,一直存在Redis服务器中。redis的内存会越来越高。那么就应该采用内存淘汰机制。
在redis.conf中有一行配置
# maxmemory-policy volatile-lru
Redis提供了8种内存淘汰机制:
volatile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key(这个是最常用的)
allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰。
no-eviction:禁止驱逐数据,默认配置,也就是说当内存不足以容纳新写入数据时,新写入操作会报错。这个应该没人使用吧!
4.0版本后增加以下两种:
volatile-lfu:从已设置过期时间的数据集(server.db[i].expires)中挑选最不经常使用的数据淘汰
allkeys-lfu:当内存不足以容纳新写入数据时,在键空间中,移除最不经常使用的key
六、使用redis有什么缺点
1、缓存和数据库双写一致性问题
一致性问题是分布式常见问题,数据库和缓存双写,就必然会存在不一致的问题。我们只能保证最终一致性。因此,有强一致性要求的数据,不能放缓存。
在这里简单的说一说更新策略:先更新数据库,再删缓存。
其次,因为可能存在删除缓存失败的问题,可以利用消息队列进行补偿操作。
2、缓存穿透、缓存雪崩问题
缓存穿透,即故意去请求缓存中不存在的数据(如id为"-1"的数据),导致所有的请求都怼到数据库上,从而数据库连接异常。
解决方案:
1、接口层增加校验,如id<=0的直接拦截;
2、利用布隆过滤器,内部维护一系列合法有效的key。
缓存雪崩,即缓存同一时间大面积的过期,这个时又来了一波请求,结果请求都怼到数据库上,从而导致数据库压力过大,连接异常。
解决方案:
1、给缓存的过期时间,加上一个随机值,避免集体失效。
2、使用互斥锁。