一、选取大数据平台
1、CDH大数据平台
- CDH大数据平台分为收费版和免费版,收费版和免费版它们共有系统管理、自动化部署、快速检查、统一界面管理、资源管理、高可用(Zookeeper)、管理客户端配置、节点模板、多集群管理、服务主机活动的监控和广泛API等。可以集成hadoop、hive、spark和flink常见组件。
- 付费版独享的功能
- 当前历史磁盘的用量展示。
- 基于用户和组的配额设置。
- 记录配置历史及回滚。
- 保留所有活动及配置变化的痕迹档案,包括回滚到之前的能力。
- 自动化备份和灾难恢复。
- 集中配置和管理快照,复制HDFS、Hive、Hbase工作流。
- 总结:收费版本提供了7X24小时的技术支持,提供版本回滚,CDH免费版支持常见的大数据组件,可以使用。
2、HDP大数据平台
- HDP是由美国大数据公司Hortonworks开发的企业级Hadoop平台,HDP是100%开源的,平台主要包括管制集成、工具、数据访问(MapReduce、Pig、Hive/Tez、NoSQL)、数据管理(HDFS、YARN)、安全性和运营等模块。
- HDP和CDH比较
- 1、HDP是100%完全开源的,而CDH还不是100%完全开源。
- 2、支持的组件,HDP和CDH基本支持所有的开源大数据组件。
- 3、代码包依赖。如果是HDP平台,编写代码直接依赖Hadoop的版本即可,如果是CDH平台,编写代码需依赖CDH的版本。
3、CDP大数据平台
- 2019年由原cloudera公司和hortonworks公司合并而来,CDP源自各自企业数据云平台CDH和HDP的合并。CDP公有云支持AWS、Azure,GCP和国内的aliCloud。CDP数据中心类似于CDH和HDP,直接安装在硬件服务器上,目前支持市面上主流的X86服务器,包括国内海光服务器。
- CDP是由CDH和HDP合作建在云数据库上的大数据平台,集成工具多,安全性高,价格较为昂贵,政府和大公司可以选择,对于初创公司不太友好,成本过高。
4、各种云数据中台
- 比如阿里云,腾讯云,袋鼠云,数梦工场等等数据中台,市场上有一定规模的公司,都会研究开发自己的数据中台,政府一般都会采用阿里云数据中台,一是安全有人维护,二是减少了运维和购买服务器的成本。
二、选取调度平台
市场上常见的调度平台有四种:
1、DolphinScheduler(海豚调度)
- Docker-compose部署海豚调度
- DolphinScheduler官网
- Apache DolphinScheduler 是一个分布式易扩展的可视化DAG工作流任务调度开源系统。适用于企业级场景,提供了一个可视化操作任务、工作流和全生命周期数据处理过程的解决方案。
- Apache DolphinScheduler 旨在解决复杂的大数据任务依赖关系,并为应用程序提供数据和各种 OPS 编排中的关系。 解决数据研发ETL依赖错综复杂,无法监控任务健康状态的问题。 DolphinScheduler 以 DAG(Directed Acyclic Graph,DAG)流式方式组装任务,可以及时监控任务的执行状态,支持重试、指定节点恢复失败、暂停、恢复、终止任务等操作。
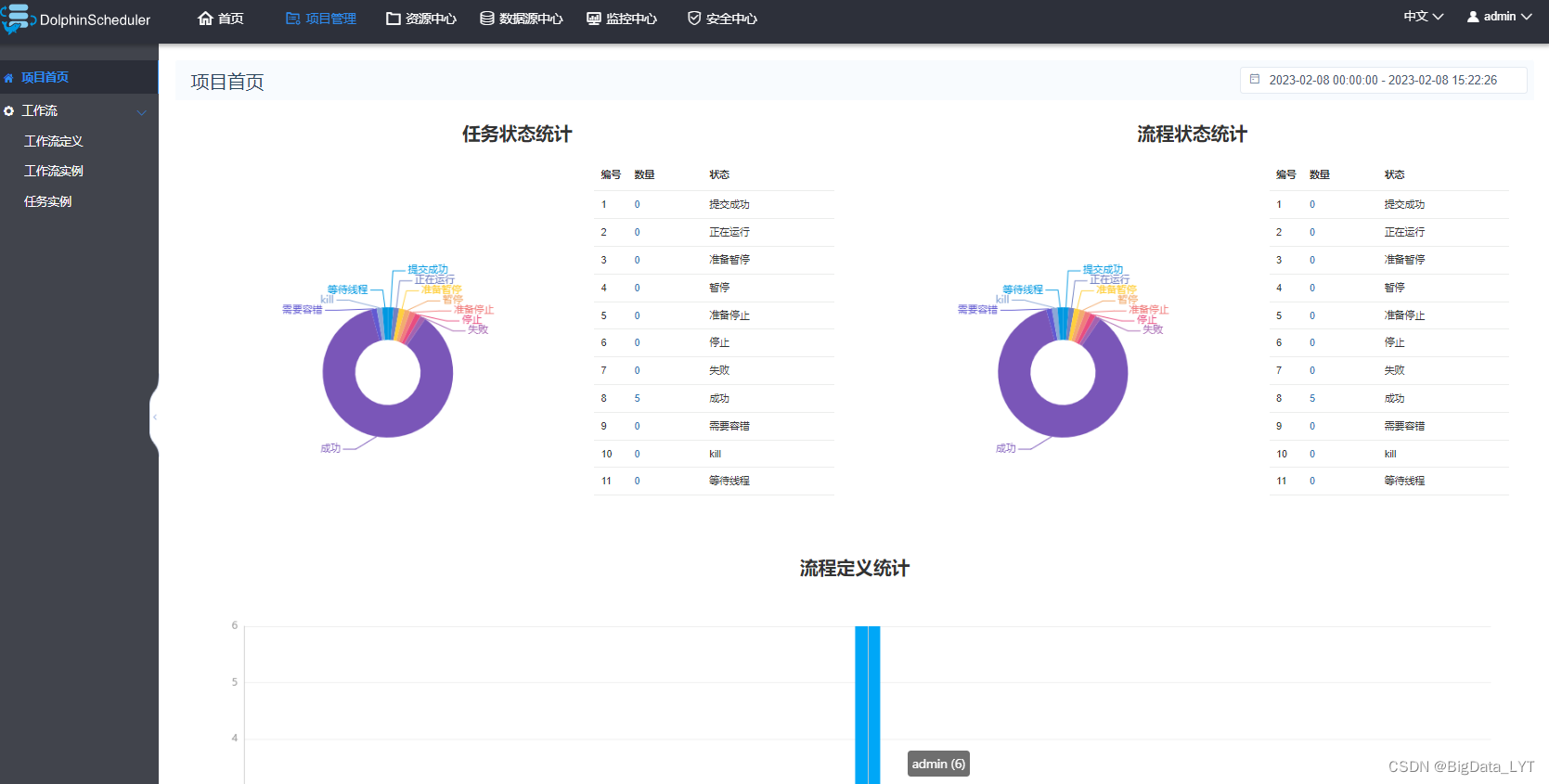
- 海豚调度是国内开发的调度工具,页面中文版,工作流中集成了shell脚本、数据库SQL、Spark、Flink、MapReduce、Python、HTTP、DataX和Sqoop等工具的调度。对初学者比较友好。
2、AzKaban
- AzKaban官网
- Azkaban是一套简单的任务调度服务,整体包括三部分webserver、dbserver、executorserver。
Azkaban是由Linkedin开源的一个Java项目,批量工作流任务调度器。用于在一个工作流内以一个特定的顺序运行一组工作和流程。
Azkaban定义了一种KV文件格式来建立任务之间的依赖关系,并提供一个易于使用的web用户界面维护和跟踪你的工作流。 - Azkaban的功能特点:
1)、 Web用户界面
2)、 方便上传工作流
3)、 方便设置任务之间的关系
4)、 工作流调度
5)、 认证/授权
6)、 能够杀死并重启工作流
7)、 模块化和可插拔的插件机制
8)、 项目工作区
9)、 工作流和任务的日志记录和审计
3、Oozie
- Oozie官网
- Oozie的特点
-
- Oozie是管理hadoop作业的调度系统。
-
- Oozie的工作流作业是一系列动作的有向无环图(DAG)。
-
- Oozie协调作业是通过时间(频率)和有效数据触发当前的Oozie工作流程。
-
- Oozie支持各种hadoop作业,例如:java、map-reduce、Streaming map-reduce、pig、hive、sqoop和distcp等等,也支持系统特定的作业,例如java程序和shell脚本。
-
- Oozie是一个可伸缩,可靠和可拓展的系统。
-
- CDH大数据平台中集成了Oozie调度器,可以在CDH平台打开Oozie页面,在Oozie平台上面设置工作流,Oozie调度器学起来较难。
4、Airflow
- Airflow官网
- Airflow 是一个 Airbnb 的 Workflow 开源项目,使用Python编写实现的任务管理、调度、监控工作流平台。Airflow 是基于DAG(有向无环图)的任务管理系统,可以简单理解为是高级版的crontab,但是它解决了crontab无法解决的任务依赖问题。与crontab相比Airflow可以方便查看任务的执行状况(执行是否成功、执行时间、执行依 赖等),可追踪任务历史执行情况,任务执行失败时可以收到邮件通知,查看错误日志。
5、corntab命令
- corntab菜鸟教程
- crontab的服务进程名为crond,英文意为周期任务。顾名思义,crontab在Linux主要用于周期定时任务管理。通常安装操作系统后,默认已启动crond服务。crontab可理解为cron_table,表示cron的任务列表。类似crontab的工具还有at和anacrontab,但具体使用场景不同。
- crontab的用途:
- 定时系统检测;
- 定时数据采集;
- 定时日志备份;
- 定时更新数据缓存;
- 定时生成报表;
…
三、选取数仓设计方案
数仓主要分为3类,离线数仓、实时数仓和离线实时一体化数仓(lambda架构)
1、离线数仓
- 在大数据的背景下,会存在海量的数据且实时性要求不高,可以建立一个离线数据仓库,抽取历史数据到离线数仓中,经过数仓设计,数据开发,数据挖掘,并进行报表和数据可视化的展示。
- 离线数仓主要会用到Hadoop中的HDFS做数据存储和YARN做资源调度。
- Hive做数据仓库权限的划分和数仓分层的设计。
- Mapreduce、Spark rdd或者Hive on Spark作为计算引擎。
- SparkML作为数据挖掘的工具。
- Datax、Sqoop、Kettle作为数据采集工具。
- FineBI和Superset做可视化。
- Zabbix做集群监控。
- Atlas做元数据管理。
2、实时数仓
- 随着社会对数据实时性要求的增加,抽取水流、订单等实时性很强的数据到实时数仓中,经过实时数仓设计,Source表,Chanel,Sink表,数据开发,数据挖掘,并进行报表和数据可视化的展示。
- 实时数仓主要会用到Hadoop中的HDFS做数据存储和YARN做资源调度。
- Hive做数据仓库权限的划分和数仓分层的设计。
- Sparkstreaming或者Flink作为计算引擎。
- SparkML作为数据挖掘的工具。
- Canal、Flume作为数据采集工具。
- FineBI和Superset做可视化。
- Prometheus做集群监控。
- Atlas做元数据管理。
3、离线实时一体化数仓(lambda架构)
- 离线实时一体化数仓主要应用在即包含离线数据的开发,又包含实时数据的开发;主要相关的项目有用户画像项目、推荐算法和电商平台的数仓开发等等,市场上几乎很多数仓开发项目都是lambda架构,很少有纯离线数仓和纯实时数仓的开发。根据业务数据的开发需求,选择合适的数仓开发方案。
四、选取数据采集方案
1、离线采集
- 离线采集的工具有DataX,Kettle和Sqoop等工具
1)DataX
- DataX官网
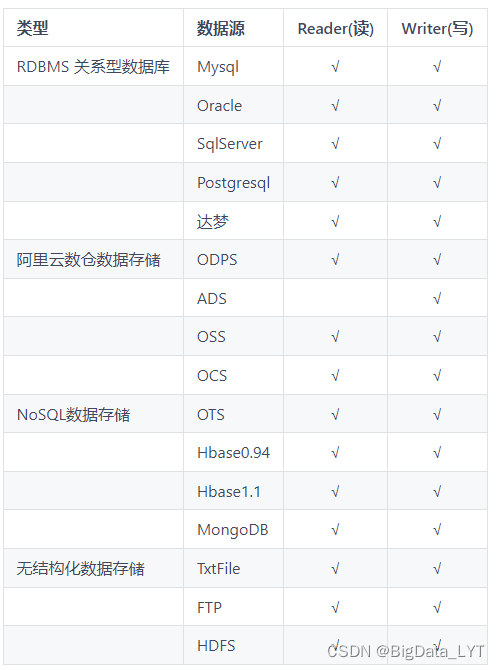
- DataX 是阿里开源的一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。
- 设计理念
- 为了解决异构数据源同步问题,DataX将复杂的网状的同步链路变成了星型数据链路,DataX作为中间传输载体负责连接各种数据源。当需要接入一个新的数据源的时候,只需要将此数据源对接到DataX,便能跟已有的数据源做到无缝数据同步。
- 框架设计
- Reader:数据采集模块,负责采集数据源的数据,将数据发给FrameWork。
- Writer:数据写入模块,负责不断的向FrameWork取数据,并将数据写入到目的端。
- FrameWork:用于连接Reader和Writer,作为两者的数据传输通道,并处理缓存,流控,并发,数据转换等核心问题。
- 支持的数据源
2)Sqoop
- Sqoop的安装和使用
- Sqoop是一个用于Hadoop和结构化数据存储(如关系型数据库)之间进行高效传输大批量数据的工具。它包括以下两个方面:
- 可以使用Sqoop将数据从关系型数据库管理系统(如MySQL)导入到Hadoop系统(如HDFS、Hive、HBase)中
- 将数据从Hadoop系统中抽取并导出到关系型数据库(如MySQL)
3)Kettle
- Kettle官网
- kettle 是纯 java 开发,开源的 ETL工具,用于数据库间的数据迁移 。可以在 Linux、windows、unix 中运行。有图形界面,也有命令脚本还可以二次开发。
2、实时采集
- 实时采集的工具有Canal,Flume等工具
1)Canal
Canal的安装和使用
- canal是阿里巴巴旗下的一款开源项目,纯Java开发。基于数据库增量日志解析,提供增量数据订阅&消费,目前主要支持了MySQL(也支持mariaDB)。
2)Flume
- Flume 是由 cloudera 软件公司产出的可分布式日志收集系统,后与 2009 年被捐赠了 apache 软件基金会, 为hadoop 相关组件之一。
- Flume 是一种分布式 , 可靠且可用的服务 , 用于高效地收集 , 汇总和移动大量日志数据 。 它具有基于流式数据流的简单而灵活的架构 。 它具有可靠的可靠性机制以及许多故障转移和恢复机制 , 具有强大的容错性和容错能力。它使用一个简单的可扩展数据模型,允许在线分析应用程序。
Flume自定义拦截器的编写
Flume自定义拦截器-筛选出以某文本开头的内容
3、离线和实时采集
1)Flinkx
- Flinkx官网
- FlinkX是一款基于Flink的分布式离线/实时数据同步插件,可实现多种异构数据源高效的数据同步,其由袋鼠云于2016年初步研发完成,目前有稳定的研发团队持续维护,已在Github/Gitee上开源,并维护该开源社区。目前已完成批流统一,离线计算与流计算的数据同步任务都可基于FlinkX实现。
- FlinkX将不同的数据源库抽象成不同的Reader插件,目标库抽象成不同的Writer插件,具有以下特点:
- 基于Flink开发,支持分布式运行;
- 双向读写,某数据库既可以作为源库,也可以作为目标库;
- 支持多种异构数据源,可实现MySQL、Oracle、SQLServer、Hive、Hbase等20多种数据源的双向采集。
- 高扩展性,强灵活性,新扩展的数据源可与现有数据源可即时互通。
- Flinkx支持的数据源

五、选取数据可视化方案
数据可视化工具主要有FineBI、FineRepoart、Superset、Echarts、Sugar、QuickBI和DataV等可视化工具。
1、FineBI
-
FineBI是帆软软件有限公司推出的一款商业智能(Business Intelligence)产品,它可以通过最终业务用户自主分析企业已有的信息化数据,帮助企业发现并解决存在的问题,协助企业及时调整策略做出更好的决策,增强企业的可持续竞争性。
-
数据处理:数据处理服务,用来对原始数据进行抽取,转换,加载。为分析服务生成数据仓库FineCube。
-
即时分析:可以选择数据快速创建表格或者图表以使数据可视化、添加过滤条件筛选数据,即时排序,使数据分析更快捷。
-
多维度分析:OLAP分析实现,提供各种分析挖掘功能和预警功能,例如任意维度切换,添加,多层钻取,排序,自定义分组,智能关联等等。
-
Dashboard:提供各种样式的表格和多种图表服务,配合各种业务需求展现数据。
-
大数据引擎
- 使用Spider高性能计算引擎,以轻量级的架构实现数据分析。
- Spider引擎支持实时数据与抽取数据两种模式,可以实现无缝切换。
- Spider引擎的高性能可实现亿级以内的数据秒级呈现。
- Spider引擎支持灵活的数据更新策略,提高数据准备效率。
-
权限管理
-
数据建模
-
数据准备
-
数据可视化智能分析
2、Superset
- Docker安装Superset
- Docker的安装 链接: Docker的安装
- Docker部署Superset 链接: Docker部署Superset
- Superset简介
- Superset是Airbnb开源BI数据分析与可视化平台(曾用名Caravel、Panoramix),该工具主要特点是可自助分析、自定义仪表盘、分析结果可视化(导出)、用户/角色权限控制,还集成了一个SQL编辑器,可以进行SQL编辑查询等,原来是用于支持Druid的可视化分析,后面发展为支持很多种关系数据库及大数据计算框架,如:mysql, oracle, Postgres, Presto, sqlite, Redshift, Impala, SparkSQL, Greenplum, MSSQL。整个项目基于Python框架,它集成了Flask、D3、Pandas、SqlAlchemy等。
- Github地址:https://github.com/airbnb/superset
- 官网地址:http://airbnb.io/projects/superset/
- 其他可视化工具仅供参考,市场上开源的可视化软件不多。