目录
1.printf返回值:
成功:返回打印字符的个数
失败:返回EOF,EOF是文件结束的标志,宏定义为-1
#include <stdio.h>
int main() {
char str[] = "123456789";
printf("%d\n", printf("%d\n", printf("%s\n", str)));
return 0;
}

最内部printf打印“123456789\n”,共10个字符,返回值为10,通过第二个printf打印出来,以此类推。
2.scanf
成功:返回成功输入的个数,可能为0
失败:返回EOF,EOF是文件结束的标志,宏定义为-1
#include <stdio.h>
int main() {
int a = 0, b = 0;
printf("scanf返回值=%d\n", scanf("%d %d", &a, &b));
printf("a=%d\nb=%d", a, b);
return 0;
}

因此可以书写以下类型的代码:
#include <stdio.h>
int main() {
int a;
char arr[10] = { 0 };
while (scanf("%d %s", &a, arr)==2){
printf("%d %s\n", a, arr);
}
return 0;
}
3.sizeof返回值
sizeof的返回值是size_t类型,是无符号整形,代表占内存的大小,单位是字节。
size_t 是一些C/C++标准在stddef.h中定义的,size_t 类型表示C中任何对象所能达到的最大长度,它是无符号整数。它是为了方便系统之间的移植而定义的,不同的系统上,定义size_t 可能不一样。size_t在32位系统上定义为 unsigned int,也就是32位无符号整型。在64位系统上定义为 unsigned long ,也就是64位无符号整形。size_t 的目的是提供一种可移植的方法来声明与系统中可寻址的内存区域一致的长度。
推荐用%zu打印,%u和%lu有时候也是可以的。
#include <stdio.h>
int main() {
char a[] = "123456789";
char* p = a;
printf("%zu", sizeof(p));
return 0;
}

4.[ ]下标引用操作符
#include <stdio.h>
int main() {
char a[] = "123456789";
printf("%c\n", a[5]);
printf("%c\n", 5[a]);
printf("%c\n", *(&a[0] + 5));
printf("%c\n", "123456789"[5]);
printf("%c\n", 5["123456789"]);
printf("%c\n", *("123456789"+5));
return 0;
}乍一看,这玩意是什么,好诡异的代码。首先你要搞明白[ ]的意思。
定义字符串两种方式:
char* p="123456789"
char a[]="123456789"
两种都可以定义字符串,当输出字符串中的某一个字符时:
*(p+i);
a[i]
两者是等价的,所以*(a+i)=a[i]
下面给出 [ ] 操作符的定义:
1.定义数组时,向编译器申请一段连续的空间。
2.指针[ i ] 表示以指针当前位置为起点,向后跳过i个该指针所指类型的大小的空间。
3.p[q] 等价于 *(p+q),若pq都不是指针则会报错!
根据第三条,我们可以写出这样的代
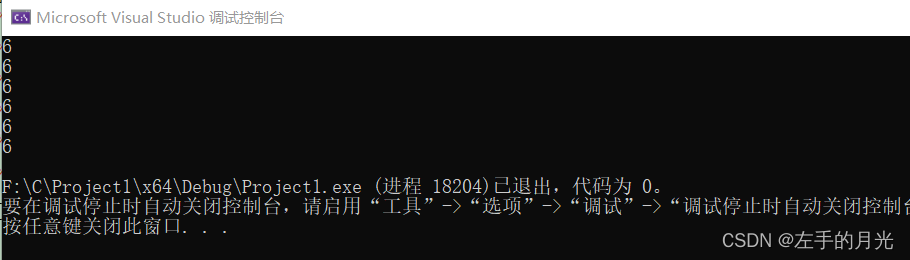
5.{ }和[ ]的替代
在某些编译器下,比如是dev 5.11下我们可以使用<:和:>代替 [ 和 ] ,用<%和%>代替 { 和 }。
#include <stdio.h>
int main()
<%
char a<::>="abcdefghigk";
printf("%s",a);
return 0;
%>
6.字符串拼接
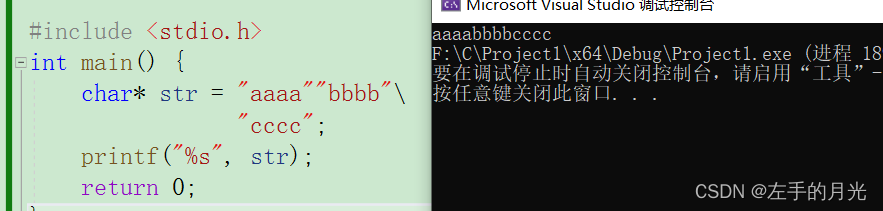
由“” 包围的字符串放在一起,会自动拼接一个字符串;
#include <stdio.h>
int main() {
char* str = "aaaa""bbbb"\
"cccc";
printf("%s", str);
return 0;
}
7.数组和数组名
你真的懂数组和数组名吗?数组名可是个难搞的东西。比如我定义一个数组int arr[10],那么arr代表什么你知道吗?看完后可能刷新你对数组名的认知。
1.代表首元素的地址,注意是代表首元素第一个字节的地址。
2.sizeof(arr)和&arr代表的是整个地址的地址(两个特殊)
#include <stdio.h>
int main() {
int arr[10] = { 0 };
printf("%p\n", arr);
printf("%p\n", arr+1);
printf("%p\n", &arr);
printf("%p\n", &arr+1);
return 0;
}
打印arr和&arr发现地址相同,你要记住地址相同但是其意思却天差地别,arr是首元素的地址,arr+1代表第二个元素的地址,步长为4个字节,也就是int类型的大小。而&arr是整个数组的地址,而&arr+1代表跨越整个数组,步长为40,也就是整个数组的大小。
#include <stdio.h>
int main() {
int arr[10] = { 0 };
printf("%d\n",sizeof(arr));
return 0;
}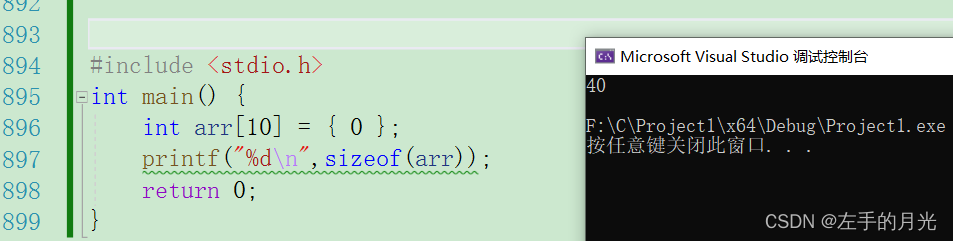
sizeof(arr)返回值为40个字节,证明了此时arr是整个数组的地址。代表整数组的地址一共就这两个特殊情况,其余情况都是代表收元素的地址。你以为就这?还没完呢。
#include <stdio.h>
int main() {
int arr[10][10] = {0};
printf("%d\n",sizeof(arr));
printf("%d\n",sizeof(arr[0]));
printf("%d\n",sizeof(arr[0][0]));
return 0;
}
懂了没?arr是一个二维数组,arr代表整个数组大小所以是400字节,arr[0]代表第一行的大小所以是40,arr[0][0]是第一个元素的大小所以是4;我们继续看。
#include <stdio.h>
int main() {
int arr[10][10] = {0};
printf("&arr: %u\n", &arr);
printf("&arr+1: %u\n", &arr+1);
printf("arr: %u\n", arr);
printf("arr+1: %u\n", arr+1);
printf("arr[0]: %u\n", arr[0]);
printf("arr[0]+1: %u\n", arr[0]+1);
printf("&arr[0]: %u\n", &arr[0]);
printf("&arr[0]+1: %u\n", &arr[0]+1);
printf("&arr[0][0]: %u\n", &arr[0][0]);
printf("&arr[0][0]+1:%u\n", &arr[0][0] + 1);
return 0;
} 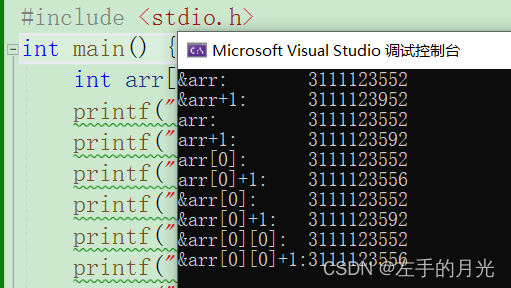
&arr代表整个数组的地址,所以&arr+1步长为400,arr代表首元素地址,注意该数组是二维数组,首元素是第一行的10个int类型的数,因此步长为40。arr[0]代表arr的第一个元素内的第一个元素,也就是a[0][0],所以步长为4。&arr[0]代表整个arr[0],因此步长也为40,&a[0][0]代表第一行第一列的地址,步长为4。你看&arr,arr,arr[0],&a[0],&a[0][0]打印的地址一样,但是本身的含义却完全不一样。你以为就这样完成了?接着来。
#include <stdio.h>
int main() {
int arr[3][4] = {
{1,22,333,444},
{5,66,777,8888},
{99,130,113,123}
};
printf("&arr:\t%u\n", &arr);
printf("&arr+1:\t%u\n", &arr+1);
printf("*arr:\t%u\n", *arr);
printf("*arr+1:\t%u\n", *arr+1);
printf("**arr:\t%u\n", **arr);
printf("**arr+1:\t%u\n", **arr+1);
printf("*arr[2]:\t%u\n", *arr[2]);
printf("*arr[2]:\t%u\n", *arr[2]+1);
return 0;
} 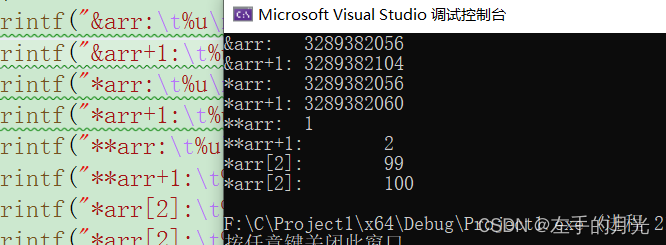
*arr代表整个arr[0],为什么呢?*arr=*(arr+0)=a[0],懂了吧,所以步为一行的元素大小,也就是12字节,**arr代表a[0][0],因为*arr=a[0]已经知道了。所以
**arr=*arr[0]=*(arr[0]+0)=a[0][0],a[0][0]的值为1,因此打印为1,后面加1代表值加1,并不是地址加减。*arr[2]也是如此。你以为完成了?别急还有呢。
#include <stdio.h>
int main()
{
int i, j;
int arr[3][4] = { 1,22,3333,4,55,666,7,88,999,101,1167,12242 };
printf("*(arr+4*i+j)\n");
for (i = 0; i < 3; i++) {
for (j = 0; j < 4; j++) {
printf("%d ",**(arr + 4 * i + j));
}
}
printf("\n");
for (i = 0; i < 3; i++) {
for (j = 0; j < 4; j++) {
printf("%d ",**arr + 4 * i + j);
}
}
return 0;
}
**(arr + 4 * i + j),arr代表首个元素,步长为一行元素12个字节,因此前三个是每一行的首个元素,随后地址越界,为随机值。**arr + 4 * i + j,**arr也就是arr[0][0],因此每次加1。我们再继续看。
#include <stdio.h>
int main()
{
int i, j;
int arr[3][4] = { 1,22,3333,4,55,666,7,88,999,101,1167,12242 };
for (i = 0; i < 3; i++) {
for (j = 0; j < 4; j++) {
printf("arr[%d][%d]=%d\t", i, j, *(&arr[0][0] + 4 * i + j));
}
printf("\n");
}
printf("\n");
for (i = 0; i < 3; i++) {
for (j = 0; j < 4; j++) {
printf("arr[%d][%d]=%d\t", i, j, *(*(i + arr) + j));//i[a][j]
}
printf("\n");
}
return 0;
}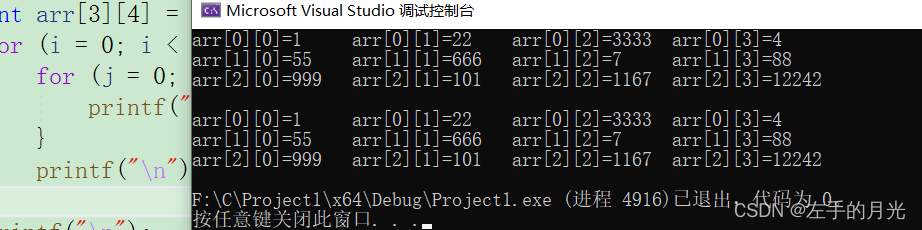
*(&arr[0][0] + 4 * i + j),取第一行第一列的元素地址步长为1,随后加1解引用,打印数组所有的值。*(*(i + arr) + j)其实就是a[i][j],你问怎么来的?a[i][i]=*(a[i]+j)=*(*(arr+i)+j),很简单对不对。到这里我才敢说我熟悉数组名的应用,注意是熟悉。