一、数据分析介绍
1.1 核心思路
1.什么是商务数据分析?
用适当的分析方法对收集来的大量数据进行分析,提取有用信息和形成结论的过程。
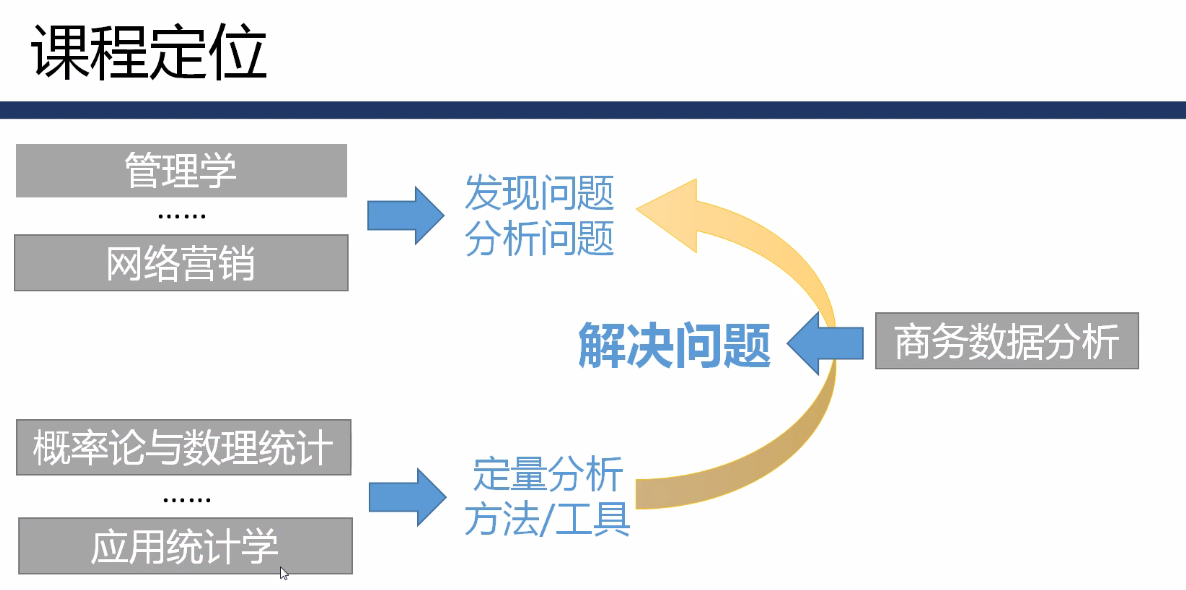
1.2 课程定位
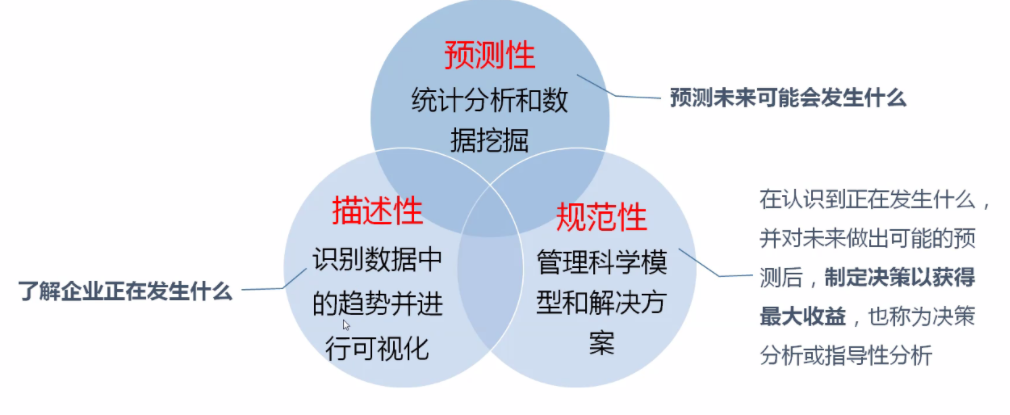
1.3数据分析的三大类型
1.4 数据测量尺度
(1)定类尺度:
- 定类尺度nominal measurement
- 对事物的类别或属性的测度
- 可计算︰频数、频率
e.g.,性别、城市、职业
(2)定序尺度ordinal measurement
- 对事物之间等级或顺序差别的测度·可计算∶频数、频率、排序
e.g.,学历、年级
(3)定距尺度interval measurement
- 对事物类别或次序之间间距的测度,通常以自然或物理单位为计量尺度·可计算︰频数、频率、排序、加减
e.g.,温度
(4)定比尺度scale measurement
- 能够测算两个测度值之间比值
- 可计算︰频数、频率、排序、加减、乘除e.g.年龄、重量
- 有一固定的绝对“零点”, “O”表示没有
总结:
1.类别型数据、有序型数据:分类型、离散型、定性数据
2.区间型数据、比值型数据:数值型、连续型、定量数据
1.5 针对不同数据属性,采用不同的统计图
| 变量个数 | 变量类型 | 可选图形 |
|---|---|---|
| 单变量 | 离散型 | 柱状图、条形图、饼图、圆环图 |
| 连续型 | 直方图、折线图、箱线图 | |
| 双变量 | 离散+离散 | 堆积柱状图 |
| 离散(不同类型)+连续(数值) | 折线图(两组)、分组箱线图 | |
| 连续+连续 | 散点图 | |
| 多变量 | 离散+多个连续 | 多个系列的散点图 |
| 三个连续 | 气泡图 | |
| 多个连续 | 雷达图、多组时间序列的折线图 |
通俗解释:
- 单变量离散型:就是对某一属性列根据属性值的不同而计数
- 单变量连续型:针对某一区间的经济价值计数,绘制直方图;针对某一时期的属性计数,绘制折线图 【描述收入在时间序列下的变化趋势】
- 双变量离散+离散:堆积柱状图【电影类别和电影的限制级别是否相关】
- 双变量离散+连续:某一属性列x的不同属性值影响下,产生了多少的经济价值y,绘制分组箱线图【计算类别对于票房收入的影响】;折线图【描述收入和支出在时间序列下的关系】
图示如下:

1.6 应用领域
数据分析早已渗透各行业各业,主要包含:互联网、电子商务、金融保险、在线教育、生产制造、生物医疗、交通物流、餐饮外卖、能源、城市管理、体育娱乐等行业。

二、数据来源
外部来源:数据购买、数据爬取、免费开源的数据等
内部来源:销售数据、财务数据、社交通信数据等
来源地址:
中国互联网信息中心
易观分析
国家数据
国家统计局
UCI
开源数据平台网站资源地址
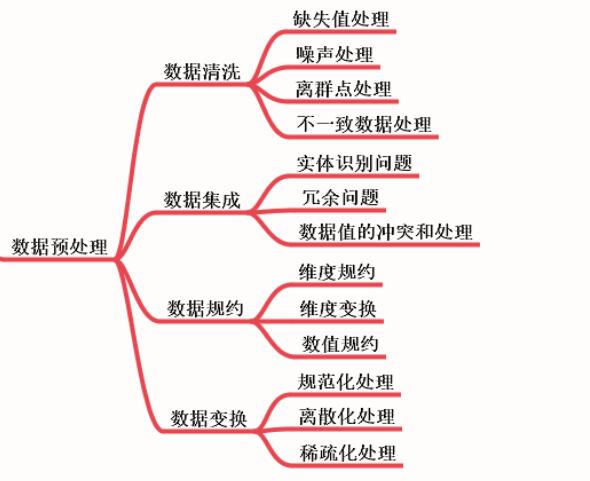
三、数据预处理
四、持续更新的数据预处理操作
1、处理数据属性列中NAN值的方法:
关于dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)参数的说明:
axis:默认是0,即删除行。1或者columns则是删除列
how:删除方式。any删除至少有一个NaN的行/列;all删除全部都是NaN的行/列
thresh:阈值。int,删除的行/列至少有n个NaN值
subset:列表。columns或者index,只删除指定列/行
2、根据特殊字符分割函数:
each = each[0].split(',')
3、去除数据属性列开头空格:each.strip()
4、去除属性列里面特殊字符:item.append(each.strip('["{","/","}"]'))
.5、replace替换中文字符
# 也可以用于去除非法字符
df_1 = df_1.replace('--', np.nan)
6、.rename方法,重命名列名或索引名
7、根据属性索引列取出数据框的特定数据列
df_1 = df.iloc[1:,[1,2,3,4,5,7]]
8、根据数据框2替换数据框1的所有对应值:
import pandas as pd
df1 = pd.DataFrame({
'col1': [1, 2, 3], 'col2': [4, 5, 6]})
df2 = pd.DataFrame({
'col1': [2, 3, 4], 'col2': [7, 8, 9]})
merged_df = pd.merge(df1, df2, on='col1', how='inner')
for index, row in merged_df.iterrows():
df2.at[df2['col1'] == row['col1'], 'col2'] = row['col2']
print(df2)
9、利用分组求均值,填补空缺值:
df_1['Budget'] = df_1.groupby('Genre')['Budget'].apply(lambda x: x.fillna(x.mean()))
10、检查是否含有空值
print(pd.isnull(data["时间戳"]).value_counts())
五、常用数据分析模型与方法
常用数据分析模型:
对比分析、漏斗分析、留存分析、A/B测试、用户行为路径分析、用户分群、用户画像分析等
常用数据分析的方法:
描述统计、假设检验、信度分析、相关分析、方差分析、回归分析、聚类分析、判别分析、主成分分析、因子分析、时间序列分析等
数据可视化
- 数据可视化:·数据可视化是指使用可视化的表达方式去探索、理解和交流数据。·将不可见或难以直接显示的数据转化为可感知的图形、符号、颜色等,增强数据识别效率,传递有效信息。
- 数据可视化的作用:
- 信息记录:用图形的方式将抽象的事物和信息记录下来,例如我国古人将观察到的星象信息以星象图的方式记录下来,用以推算历法
- 支持对信息的推理和分析:数据可视化极大地降低了数据理解的复杂度,有效地提升了信息认知的效率,从而有助于人们更快地分析和推理出有效信息
- 信息传播与协同
- 可视化分析 Visual analysis:视觉分析是一个动态的、迭代的过程,在这个过程中,您可以快速构建不同的视图来探索“是什么”及其背后的“为什么”的无限路径。可视化分析可以帮助您探索、寻找答案,并在您的数据中构建故事。它甚至超越了最初的见解,所以每个看到可视化的人都可以提问,并找到意想不到的发现。简而言之,可视化分析是一种以可视化方式实时探索数据的方法。
主要使用工具:python的
matplotlib、seaborn库
Python中常用的数据可视化的库:Matplotlib、Seaborn。
常见数据可视化图表:

————————————————————————————————
参考学习地址:
https://blog.csdn.net/longxibendi/article/details/82558801
https://www.cnblogs.com/caochucheng/p/10539282.html
https://www.cnblogs.com/HuZihu/p/11274171.html
https://www.cnblogs.com/bigmonkey/p/11820614.html
https://blog.csdn.net/weixin_43913968/article/details/84778833
https://www.zhihu.com/collection/275297497
http://www.woshipm.com/data-analysis/1035908.html
https://www.sensorsdata.cn/blog/20180512/
http://meia.me/act/1/schedule/112?lang=
http://www.360doc.com/content/20/0718/00/144930_924966974.shtml
https://zhuanlan.zhihu.com/p/51658537
https://www.cnblogs.com/ljt1412451704/p/9937833.html
https://www.cnblogs.com/peter-lau/p/12419989.html
https://zhuanlan.zhihu.com/p/138671551
https://zhuanlan.zhihu.com/p/83403033
https://blog.csdn.net/qq_33457248/article/details/79596384?utm_medium=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase
https://blog.csdn.net/YYIverson/article/details/100068865?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase
https://blog.csdn.net/weixin_30487317/article/details/101566492?utm_medium=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase