文章目录
过拟合和欠拟合的解释
`这里首先我们来看这张图
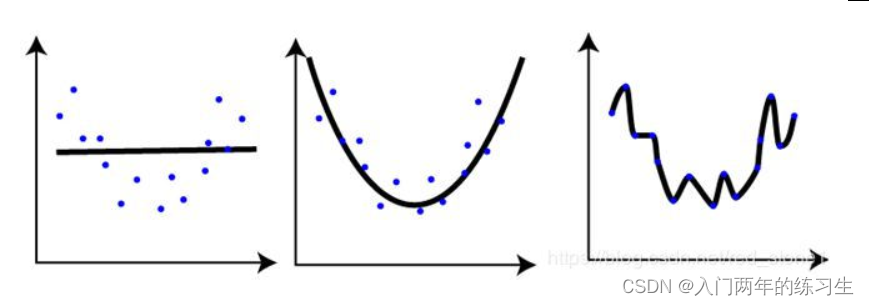
中间的图像表示为理想的训练预测结果
欠拟合是指模型在训练集、验证集和测试集上均表现不佳的情况;如上图左图
过拟合是指模型在训练集上表现很好,到了验证和测试阶段就很差,即模型的泛化能力很差。如上图右图
过拟合欠拟合出现原因
欠拟合:
出现欠拟合情况的原因有很多:模型不够强大、过度正则化,或者只是训练时间不够长。这种情况意味着网络尚未学习训练数据中的相关模式。
过拟合:
- 模型复杂度过高,参数过多
- 训练数据比较小
3.训练集和测试集分布不一致
- 样本里面的噪声数据干扰过大,导致模型过分记住了噪声特征,反而忽略了真实的输入输出特征
- 训练集和测试集特征分布 或 标签对应关系 不一样(如果训练集和测试集使用了不同类型的数据集会出现这种情况)
深度学习模型往往擅长拟合训练数据,但真正的挑战是泛化而非拟合。
解决办法
欠拟合解决方法:
欠拟合的情况比较好解决,因为是在训练阶段的性能就不好,因此可以使用更加强大的模型,提高模型的表征能力或者增加训练次数,使模型更好的拟合数据,通过观察验证指标和训练指标是否得到进一步优化做为评价标准。(model.fit()方法会返回指定的优化指标历史信息,通过打印该信息即可观察训练指标或验证指标)
过拟合解决方法:
要防止过拟合,最好的解决方案是使用更完整的训练数据。数据集应该涵盖模型要处理的所有输入。
在更完整的数据上训练的模型自然能更好地进行泛化。如果没有更完整的数据,则第二好的解决方案是使用正则化之类的技术。这些技术限制了模型可以存储的信息的数量和类型。如果网络只能记住少量的模式,则优化过程将迫使其关注最突出的模式,这些模式将有机会获得更好地泛化。