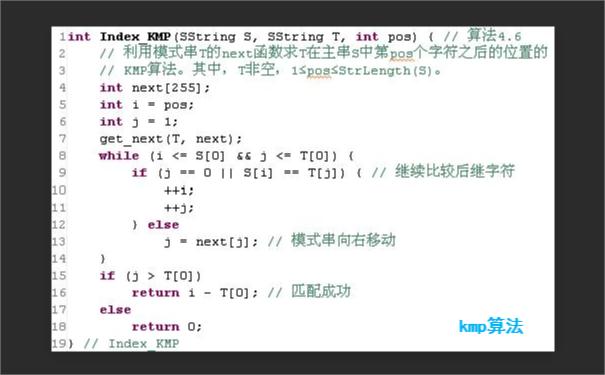
KMP (Knuth-Morris-Pratt)算法是一种用于在一个文本串S内查找一个模式串P的字符串匹配算法。它是由Donald Knuth,Vaughn Pratt和James H. Morris在1977年设计的。 KMP算法的主要优点是利用了匹配失败的信息来减少模式串与文本串的匹配次数,从而提高了字符串匹配的效率。时间复杂度是 O(n+m)
下面是一个简单的 KMP 算法示例,它在文本串S中查找模式串P的第一个匹配位置:
def KMPSearch(pat, txt):
M = len(pat)
N = len(txt)
# create lps[] that will hold the longest prefix suffix
# values for pattern
lps = [0]*M
j = 0 # index for pat[]
# Preprocess the pattern (calculate lps[] array)
computeLPSArray(pat, M, lps)
i = 0 # index for txt[]
while i < N:
if pat[j] == txt[i]:
i += 1
j += 1
if j == M:
print("Found pattern at index " + str(i-j))
j = lps[j-1]
# mismatch after j matches
elif i < N and pat[j] != txt[i]:
# Do not match lps[0..lps[j-1]] characters,
# they will match anyway
if j != 0:
j = lps[j-1]
else:
i += 1
def computeLPSArray(pat, M, lps):
len = 0 # length of the previous longest prefix suffix
lps[0] = 0 # lps[0] is always 0
i = 1
# the loop calculates lps[i] for i = 1 to M-1
while i < M:
if pat[i] == pat[len]:
len += 1
lps[i] = len
i += 1
else:
# This is tricky. Consider the example.
# AAACAAAA and i = 7. The idea is similar
# to search step.
if len != 0:
len = lps[len-1]
else:
lps[i] = 0
i += 1
txt = "ABABDABACDABABCABAB"
pat = "ABABCABAB"
KMPSearch(pat, txt)
转载说明:本文部分内容引用自电脑监控软件https://www.vipshare.com/archives/10957,转载请提供出处