【本教程更新于2023年5月13日,运行环境为Win10 x64】
目录
下载安装
1、浏览器中打开PaddleX 图形化客户端下载链接:飞桨PaddlePaddle-源于产业实践的开源深度学习平台![]() https://www.paddlepaddle.org.cn/paddlex/download
https://www.paddlepaddle.org.cn/paddlex/download
2、点击WIN版下载
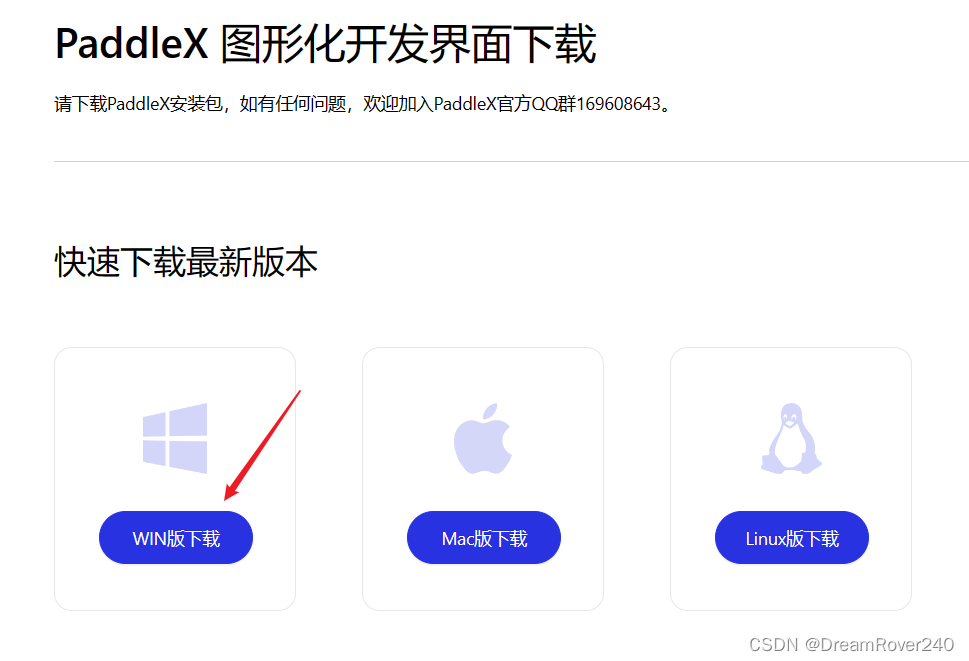
3、需要填写个人信息,填写并提交后,可自动跳转下载页面下载。
若下载速度过慢,可以从百度网盘上下载:
链接:https://pan.baidu.com/s/1v72UG0Qxs0prUhF6d1LN6Q?pwd=sycq
提取码:sycq
4、下载完成后,解压到本地硬盘。
5、解压后,进入PaddleX_GUI目录,找到PaddleX.exe文件,双击运行。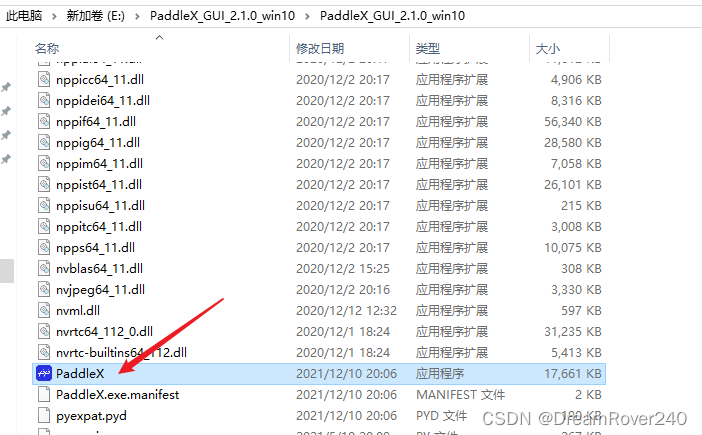
6、打开后进入欢迎界面,点击立即使用。

基础使用
1、首先需要初始化工作空间,注意工作空间路径不能包含中文字符集空格,尤其是默认路径存放在“用户”-“用户名”的路径情况下,尤其需要注意用户名为中文的情况。
建议放置在某个磁盘的根目录下,如C:\paddlex_workspace 或 D:\paddlex_workspace

2、创建好工作空间目录后,将询问是否下载样例工程,可以选择“确定”,如果此次不下载,也可以在后续的使用中再次下载。

3、在选择下载示例项目时,可以先选择“图像分类”,其他的以后用到的时候再下载。不同示例项目的体积大小不同,图像分类需下载的图片大约70-80M。

如果在此时未下载相关示例文件,则在安装完成后,可以在“项目管理”——“我的项目”,点击屏幕中间的“下载”链接,下载相应示例文件。

4、PaddleX会检测系统的GPU环境,如果系统未安装GPU及相关驱动,那么默认将启动CPU版本。

5、此时点击“确认”,再左侧导航栏中,进入“项目管理”——“我的项目”,就会出现已经下载好的图像分类示例项目:“果蔬类别”
6、此时对应在磁盘工作目录中,有下载好的数据集D0001。在本地磁盘找到刚刚创建的工作目录,paddlex_workspace,里面可以看到datasets目录,其中有数据集D0001.

7、进入 paddlex_workspace\datasets\D0001目录,可以看到数据集的结构,如下:

8、该数据集中包含了6个目录,分别为菠菜(bocai)、长茄子(changqiezi)、红苋菜(hongxiancai)、胡萝卜(huluobo)、西红柿(xihongshi)、西兰花(xilanhua)的图片。每个目录中大概有200张不同的图片,每张图片尺寸384×216,大小约25KB。

9、在D0001目录中,找到一个名为labels.txt的文件,通过记事本、Notepad++等文本编辑软件打开,可以看到其中的内容,是对应了本次分类识别目标的标签,一共6个,每个标签一行。如下图。

如何进行图像分类训练
1、接下来,我们来开始自己的图像分类训练。利用刚刚下载下来的果蔬类别图片数据集。
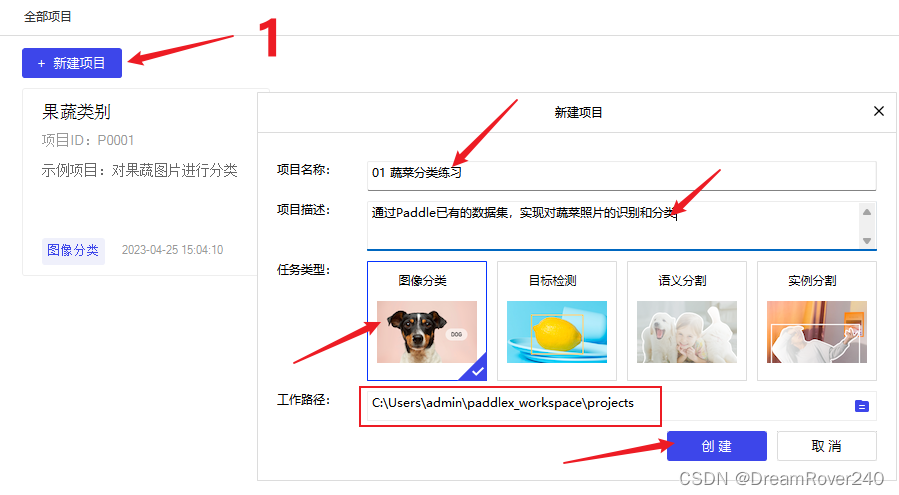
- 首先,在“项目管理”——“我的项目”当中,点击“新建项目”
填写以下信息:
| 项目名称: | 01 蔬菜分类练习 |
| 项目描述 | 自己填写项目描述信息 |
| 任务类型 | 选择“图像分类” |
| 工作路径 | 选择之前创建的paddlex_workspace |
- 全部填写完成后,点击“创建”。
2、创建完成后,进入“数据选择”步骤,在“选择数据集”的下拉框中,点击右侧的向下箭头,可出现刚刚下载的示例项目数据集“果蔬类别数据”。点击该数据集。

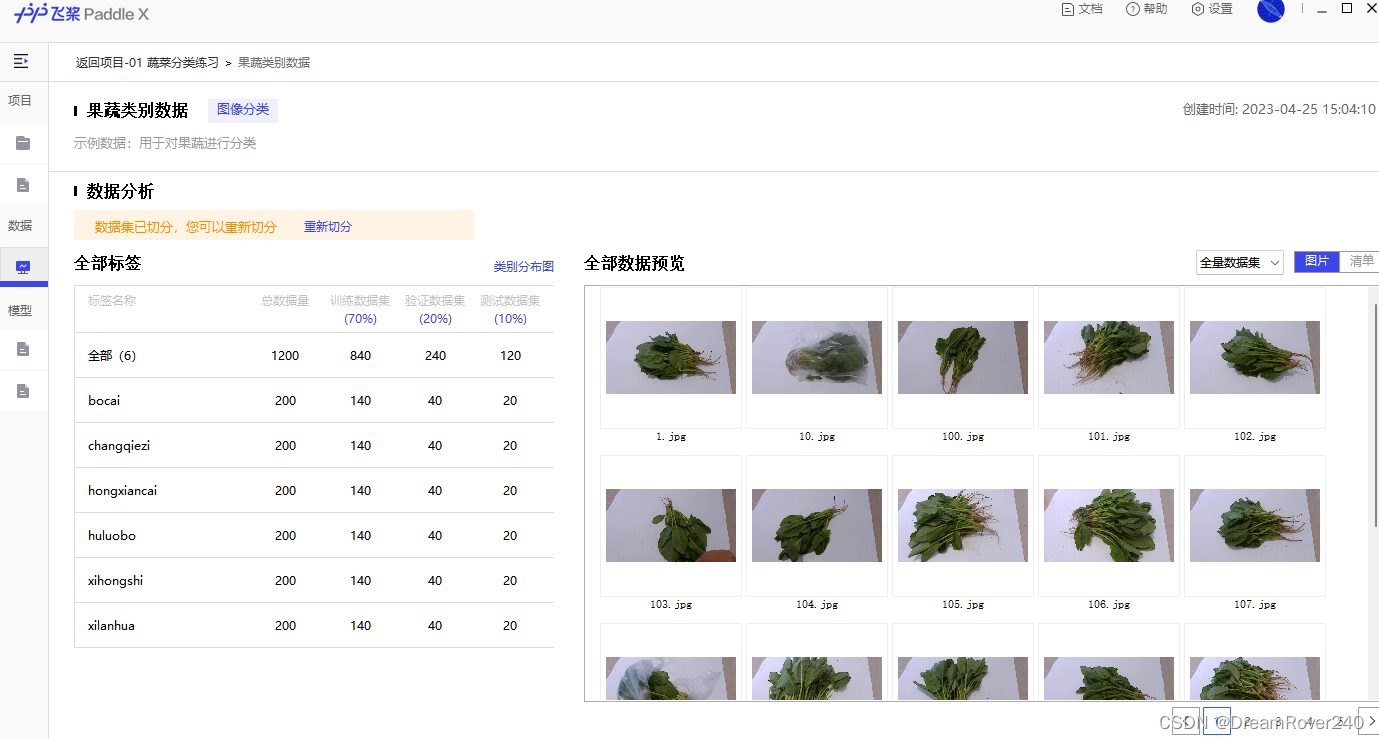
3、此时将出现该数据集的相关详细信息,如下图所示。出现了数据集的标签数量、训练集图片数量、验证集图片数量、测试集图片数量等。

4、 此时,点击“数据集预览”按钮,可以看到数据集的详细信息,以及图片内容。
左侧部分可以看到该数据集的所有标签,本示例中共有6个标签,对应每一行能看到每个标签的名字、图片总量、划分到训练集的图片数量、划分到验证集的图片数量以及划分为测试集的图片数量。
右侧部分是对应每个标签的具体数据集图片内容,可以看到图片缩略图。点击左侧不同标签,可以查看不同标签数据集图片。
5、查看完数据集详情后,点击界面最上方的路径中我们新建的项目名字,“01 蔬菜分类练习”
6、再点击“数据选择”——点击下方的“下一步”。
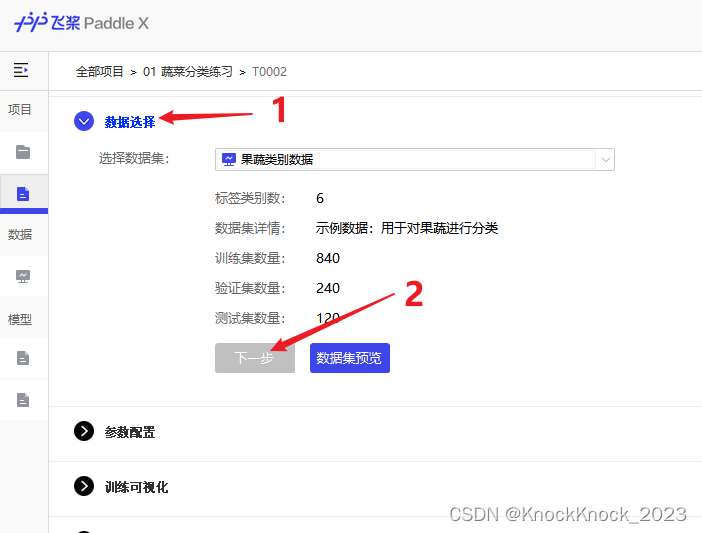
7、此时进入“参数配置”环节,此时可以采用默认参数,或者调整为如下参数:
| 模型选择 | MobileNetV2 |
| 使用自定义预训练模型 | 否 |
| 使用GPU | 是 |
| 迭代轮数(Epoch) | 10 |
| 学斜率(Learning Rate) | 0.025 |
| 批大小(Batch Size) | 125 |
然后点击“启动训练”。

8、此时PaddleX就开始了训练过程。通过“训练可视化”标签可以看到训练进度及过程数据。
等待训练结束。(本示例中,我们选择了10轮,则要等10轮训练完成,才结束训练。)
9、等到训练全部结束后, 点击“模型评估”
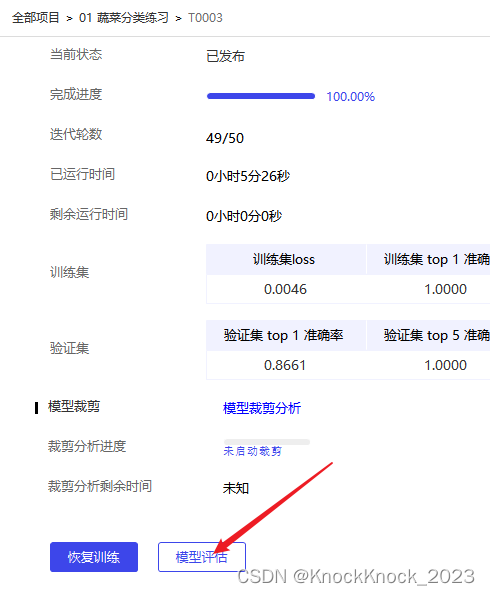
10、完成模型评估后,PaddleX会显示模型评估的结果数据。在模型评估结果数据的最后面,可以看到“模型测试”部分,点选“测试类型”为“测试集图片测试”,然后点击“启动测试”按钮。

11、测试完成后,可点击“下一步”。

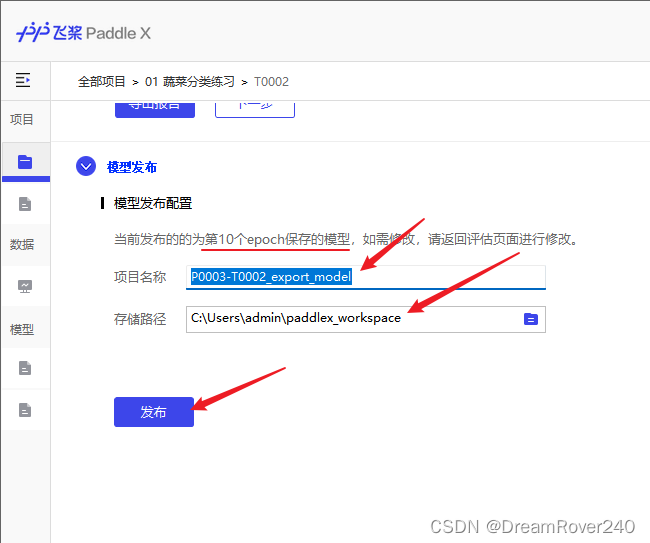
12、此时PaddleX会挑选训练效果最好的一轮的结果作为模型导出。选择好模型导出的目录后,点击“发布”。
13、发布完成后,可以点击“查看”,找到刚刚发布的模型。模型文件在 inerence_model中。
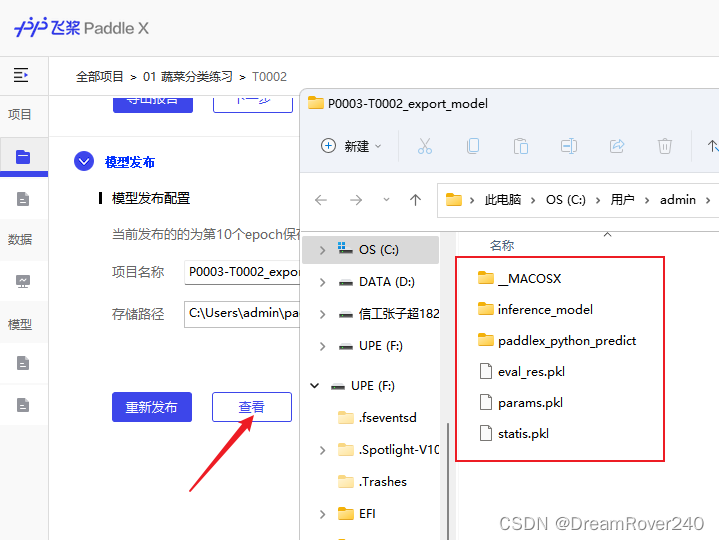
至此,我们已经利用PaddleX完成了自己数据集的训练和模型发布。
记住发布的模型所存放的路径,接下来的教程,我们将调用自己刚刚训练好的模型进行推理。