【ICLR2023】HiViT: A Simpler and More Efficient Design of Hierarchical Vision Transformer
HIVIT: A SIMPLER AND MORE EFFICIENT DESIGN OFHIERARCHICAL VISION TRANSFORMER - 知乎 (zhihu.com)
【本文贡献】
本文深入研究了ViT和Swin之间的比较,提出了以下几点:
- Swin的性能增益主要是由加深的主干和相对位置编码带来的
- Swin的分层设计可以简化为分层patch嵌入
- 可以去除其他设计,如转移窗口注意力
基于以上几点,提出了HiViT,它比Swin更简单、更高效,但进一步提高了其在全监督和自监督视觉表示学习上的性能。
【网络结构】

在基础的ViT中,对于大多数样本,每个区块的平均注意图的方差很小,这表明模型已经学习了稳定的注意模式。一些离群点在深层表现出较大的方差,这意味着在深层不再需要patch间的信息。在较深的VIT中,对于几乎所有的样本,浅层的注意图的具有更高的方差,这表明这些层没有学习到可靠的注意图。这些观察表明,早期层不能在更深的体系结构中学习有效的注意力,因此移除HiViT中的浅层窗口注意力几乎没有负面影响。由此本文在swin的基础上进行改造,将原本的窗口注意力替换为MLP,将Swin的分层设计简化为分层patch嵌入,形成了HiViT。

【心得体会】
改模型不一定非要做的多花哨多复杂,简单点也挺好(
【ARXIV2304】RIFormer: Keep Your Vision Backbone Effective While Removing Token Mixer
RIFormer: Keep Your Vision Backbone Effective But Removing Token Mixer - 知乎 (zhihu.com)
【本文贡献】
- 本文建议通过为简单模型架构开发高级学习范式来探索视觉主干,以满足实际应用的需求。
- 采用重新参数化思想,建立了一个没有token mixer的transformer——RIFormer,提高了归纳偏差建模能力,同时提高了推理效率。
【网络结构】
阐明如何学习极其简单的模型,本文的学习策略总结如下:
- 不使用真实标签的软蒸馏更有效
- 在没有蒸馏的情况下使用仿射变换很难对性能退化的情况进行调整
- 本文所提出的块知识蒸馏,称为模块模仿,有助于利用仿射算子的建模能力
- 具有大感受野的教师有利于提高感受野有限的学生
- 将教师模型(token mixer除外)的预训练权重加载到学生中可以提高收敛性和性能
本文提出的RIFormer使用了结构重参数化,采用强大模型,在student模型中引入了仿射变换进行训练,在推理时将仿射变换的参数合并到LayerNorm中,等效转化为简单模型。

除此之外,RIFormer采用了模块模仿方法,利用教师网络中的有用token mixer信息,使用预训练好的PoolFormer作为教师网络,让结合LN层的affine operator在训练阶段去近似token mixer。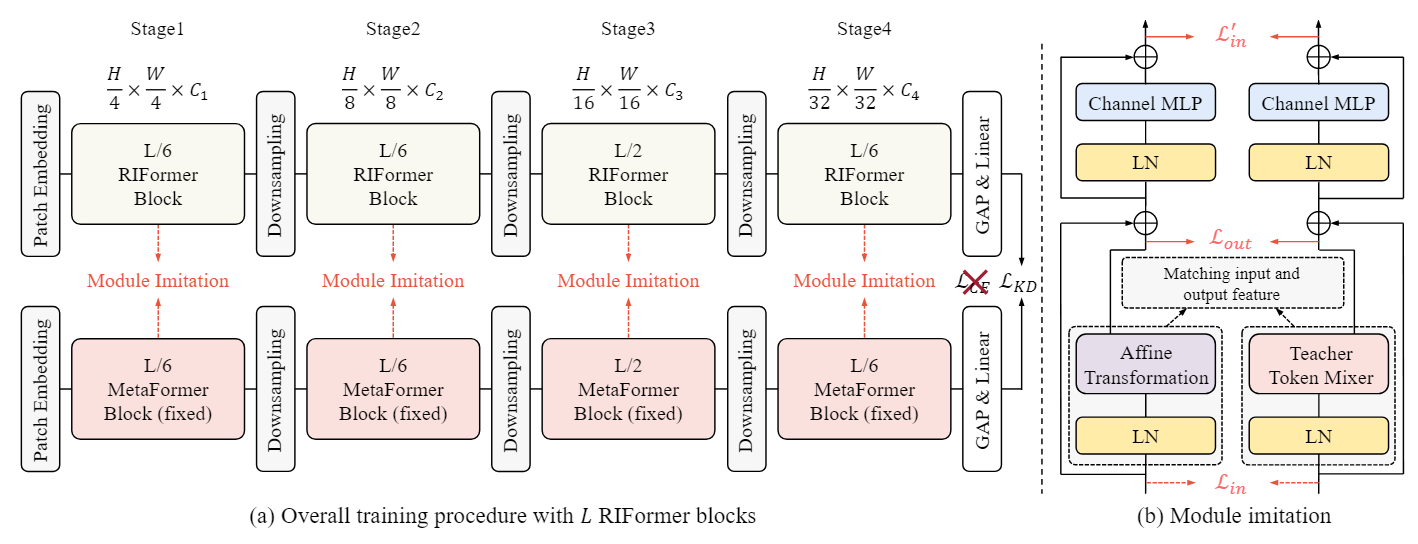
【心得体会】
感觉这个比token mixer更麻烦,但也是个很好的探索,未曾设想的道路增加了(
【JSTARS21】Applications of Deep Learning-Based Super-Resolution for Sea Surface Temperature Reconstruction
【本文贡献】
本文是一个在海面温度图上进行超分辨率的工作,它首次提出了一种包括多尺度特征提取和多感受野映射的超分辨率模型,称为ODRE,然后将所提出的模型和其他四个已有的超分辨率模型应用于海温重建,并进行了分析。
针对本文指出的影响超分辨率性能的两个重要因素,ODRE使用的多尺度特征提取可以提高超分辨率的性能,特别是对于小区域和稳定的海温区域。
除此之外,本文通过一系列论证表明,虽然更深的网络有助于提高超分辨率性能,但简单地添加更多膨胀卷积(dilation convolution)可能不会提高超分辨率重建的精度。
【网络结构】

ODRE的网络结构如上图,先使用双三次插值(Bicubic interpolation)进行上采样,再进行训练。训练过程主要分为两个阶段:
①多尺度特征提取:SST在低分辨率和高分辨率地图上的分布是相似的,因此不同尺度上的上下文信息可以为超分辨率过程提供有用的空间特征。首先对输入数据同时进行3×3、5×5、7×7三种大小的卷积运算,每次卷积运算可生成单尺度64通道特征图,在每次卷积后使用非线性激活函数RELU,然后将3个特征图进行拼接,生成多尺度特征图,并使用1×1卷积层和RELU将通道数减少到64个,从而减少计算量。最终的多尺度64通道特征图包含不同尺度的上下文信息,可用于后续处理。
②多感受野映射:这部分主要由7层膨胀卷积串联而成,膨胀卷积的膨胀系数从1递增到4,再从4递减到1,所有层的核大小为3×3,步长为1个像素,每层的感受野是3×3、7×7、13×13、21×21、27×27、31×31和33×33。其中本文发现,“感受野越大,超分辨率表现越好”在SST超分辨率中并不总是有效的。除此之外还添加了跳过连接,形状类似U-Net,通过跳过连接保留更多的图像信息,减小梯度消失的发生。
训练网络时,利用基于微波和基于红外的海温的相似性,本文不再直接使用MODIS海温作为标签来计算损失函数,而是使用AMSR2和MODIS海温之间的残差图像作为标签来训练ODRE网络。
测试时,将残差图像添加到相应的放大的AMSR2 SST图中,即可生成对应的高分辨率SST。
损失函数使用的是均方误差MAE,N设置为64。学习率和动量分别固定为1e-6和0.9,训练epoch为40,并且所有的卷积都使用MSRA进行了初始化。
本文使用的评估指标有均方误差MSE、均方根误差RMSE、信噪比SNR、峰值信噪比PSNR和结构相似性SSIM。
【心得体会】
如果要使用膨胀卷积,每层的膨胀系数不要全都一样,避免网格化。
本文的MODIS数据集也可以当作训练集在超分工作里用一用。