问题描述
根据给定的语料库,统计其中共包含多少字、平均每个词使用了多少次以及常用词的分布以及累计分布情况。
本文就以大秦帝国第一部小说为例进行实验
本文可以使用在毕业设计中,如果有帮助采用请点赞关注下呗,欢迎大家交流技术,也可以私聊毕设题目交流解决方法
构建语料库
因为我们要处理的语言是中文,部分方法 NLTK 是针对英文语料的,中文
语料不通用(典型的就是分词)。这个问题的解决方法很多,诸如通过插件等在NLTK 工具包内完成对中文的支持。另外也可以在 NLTK 中利用Standford NLP 工具包完成对自己语料的操作。
可以对汉字字体以及字号进行设置,然后通过PlaintextCorpusReader函数创建语料库
from nltk.corpus import PlaintextCorpusReader
worlists = PlaintextCorpusReader(corpus_root, '.*')
统计字数
在创建完语料库后,我们可以打开语料库中的每个文件,然后统计每个文件中的字符数以及字数,统计字数时需要使用words函数
str1 = f.read() # 读取文件的所有字符
len_str = len(str1)
print(text + '文本的字符数为:' + str(len_str)) # 输出文件的字符数
len_word = len(worlists.words(text))
print(text + '文本的字数为:' + str(len_word)) # 输出文件的字数
之后可以统计每个文件的指定字符出现的次数,使用的是字符串的count函数
str1.count("周")
查看文本中的出现次数最多的字,这里使用的是FreqDist包Construct a new frequency distribution,然后使用pformat函数得到a string representation of this FreqDist,也就是返回按照字数出现频率的一个字符串,然后再使用max函数Return the sample with the greatest number of outcomes in this frequency distribution,也就是返回出现次数最多的字符
from nltk import FreqDist
最后得到的结果如下

统计词频分布
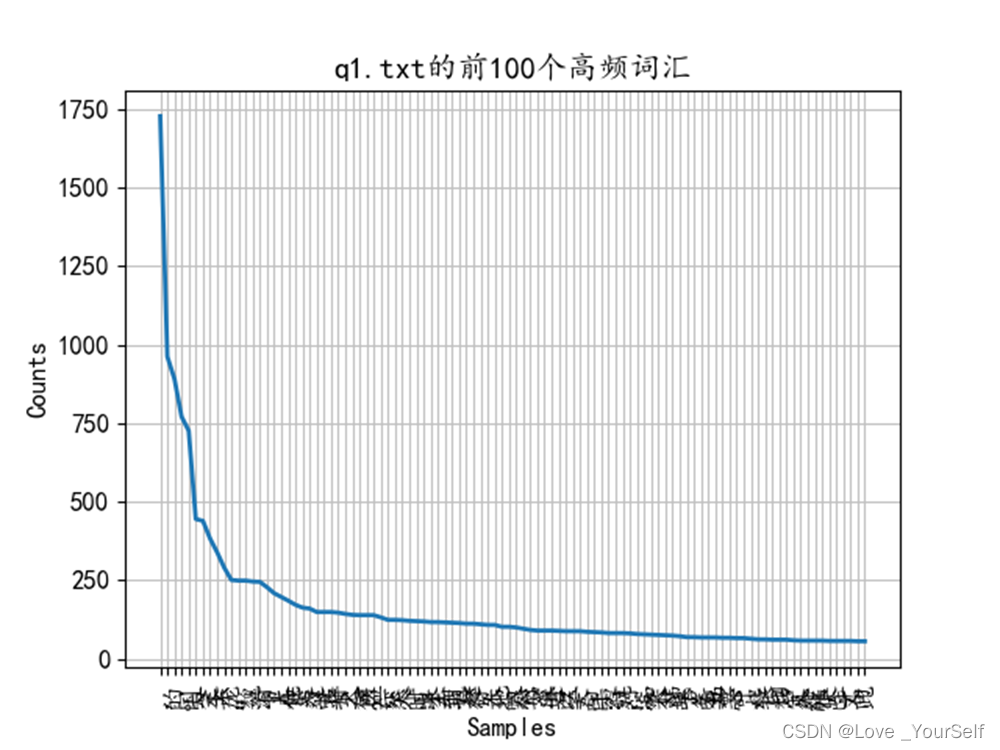
使用plot函数绘制词频出现的次数,通过下图可以分析出每个文件中词频的大致分布,大部分词频分布在那个曲线的出现弧度的部分,横坐标表示词的序列,纵坐标表示词频
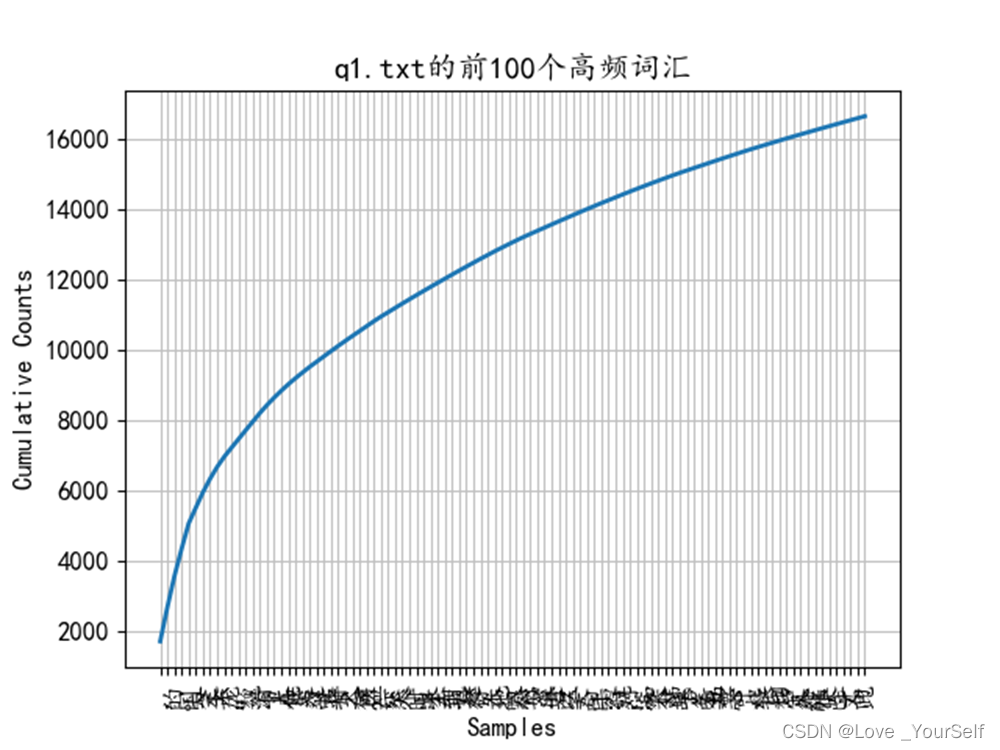
下图显示文本中所有字符相加之后的分布,也就是累积分布,可以根据这个图像看出大致的高频词汇占总共字符的一个比例
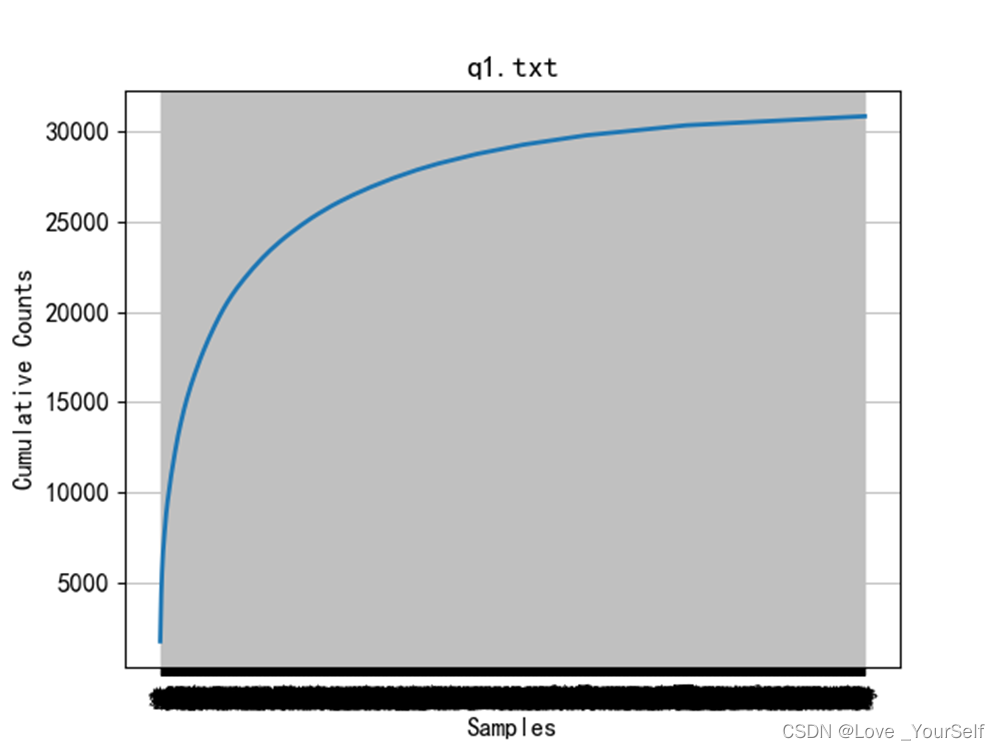
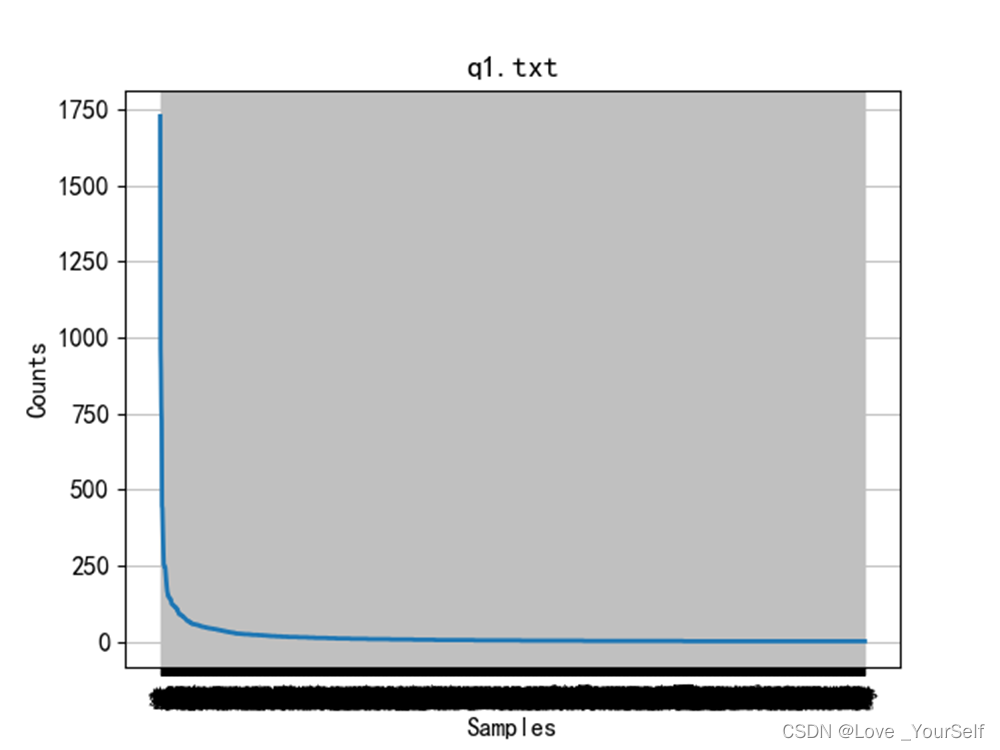
下面两张图像显示前1000个高频词汇的分布情况,图像显示前1000个能大致包含绝大多数文本内容。首先要获取前1000个高频词汇,这里使用的是字符串的更替函数,因为前面介绍的pformat函数可以返回一个代表文本词频分布的一个字符串,这个字符串很像字典形式,所以可以根据字符串的操作,转化为字典形式的字符串,然后再将其转化为字典,然后再进行显示,可以得到前1000个高频词汇的分布
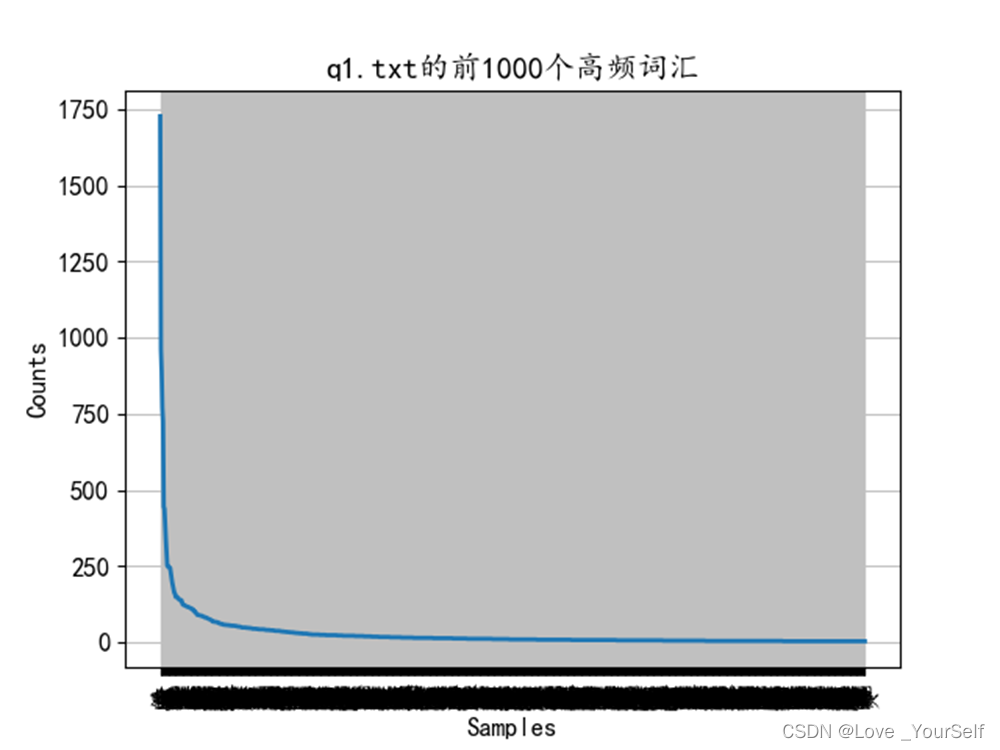
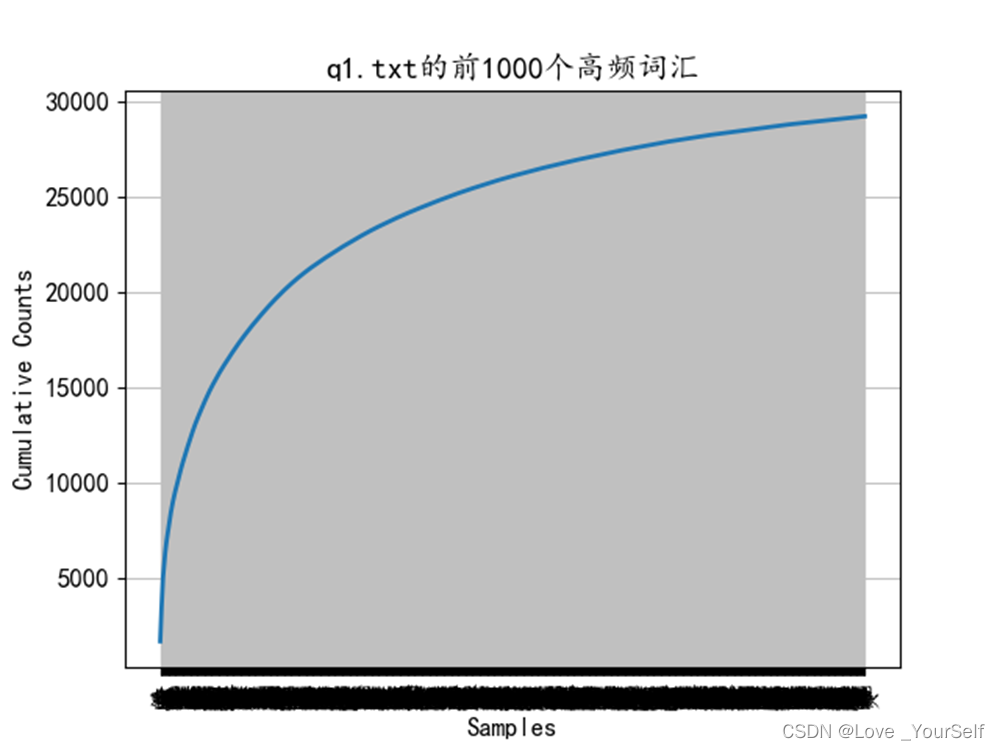
下面两张图像显示前100个高频词汇的分布情况,前100个高频词汇个数有一万六千多,q1文本的总字数为三万多,所以前100个高频词汇能大致包含50%文本内容