目录
摘要
由于图结构数据的丰富关系信息,基于图的欺诈检测方法最近引起了广泛关注,这可能有利于欺诈者的检测。然而,当节点的标签分布严重倾斜时,基于 GNN 的算法可能表现不佳,并且在金融欺诈等敏感领域很常见。为了解决基于图的欺诈检测的类不平衡问题,我们提出了一种Pick and Choose G raph Neural N etwork(简称PC-GNN)用于图上的不平衡监督学习。
首先,使用设计的标签平衡采样器挑选节点和边,以构建用于小批量训练的子图。
接下来,对于子图中的每个节点,邻居候选者由建议的邻域采样器选择。最后,聚合来自所选邻居和不同关系的信息以获得目标节点的最终表示。对基准和现实世界中基于图的欺诈检测任务的实验表明,PC-GNN 显然优于最先进的基线。
引言
欺诈检测是一项重要任务,在安全 [29]、金融 [22、39、49]、医疗保健 [17] 和审查管理 [10、26、34] 等领域有许多高影响力的应用。尽管在过去几年中开发了许多技术来检测多维点集合中的欺诈者,但随着图数据变得无处不在,基于图的欺诈检测 [1,3,33] 最近受到关注。从本质上讲,基于图的欺诈检测的基本假设是用户和欺诈者在购买产品或发表评论时具有丰富的行为交互,并且这种交互可以表示为类图数据,从而呈现有效的多方面信息用于欺诈检测。
然而,在欺诈检测任务中,欺诈者的数量可能远少于良性欺诈者的数量。例如,在 Yelp.com 的真实评论数据集 YelpChi [34] 中,14.5% 的评论是垃圾评论,而其他评论则被视为推荐评论。在阿里巴巴集团的真实金融数据集[49]中,只有0.5%的用户是无法偿还从金融平台借来的信用债务的违约者。因此,基于图的欺诈检测算法经常遇到类别不平衡问题,并且表现不佳,尤其是对于少数但更重要的类别,即欺诈者。
近年来,致力于解决传统的基于特征的监督学习环境中的类别不平衡问题的研究工作主要分为两个方向,即重新采样和重新加权方法。重采样方法通过对少数类 [5, 24] 过度采样或对多数类 [32] 采样不足来平衡示例的数量。重新加权方法通过对成本敏感的调整 [4、9、19、21] 或基于元学习的方法 [14、35、37] 为不同的类别甚至不同的样本分配不同的权重。
虽然传统特征空间中的类不平衡监督学习得到了很好的研究,但专门研究类不平衡问题的图神经网络算法尚未得到充分探索。 DR-GCN [36] 是解决图类不平衡问题的先驱。该方法提出了一个类条件对抗正则化器和一个潜在分布对齐正则化器,但不能扩展到大图。
我们强调了在设计用于基于图的欺诈检测的类不平衡图神经网络时来自两个方面的三大挑战。
从应用程序方面来看,欺诈者可能会伪造噪声信息以使其难以被识别,例如伪装 [10]。由此带来的第一个挑战是链路信息冗余。例如,对于垃圾邮件发送者,他们会使用良性帐户来发布他们的垃圾评论,这样垃圾评论和良性用户之间就会有很多联系,而垃圾邮件发送者会隐藏在良性用户中。许多基于特征或基于标签的相似性将无法识别这种嘈杂的邻居,因为欺诈者可能与良性邻居的欧几里得距离很近,但他们的标签会不同。伪装带来的第二个挑战是欺诈者缺乏必要的链接信息。例如,在金融环境中,欺诈者会避免相互交易以避免一起被发现。如图 1 所示,左欺诈中心节点与右中心节点具有相似的交易模式,因此右欺诈节点的特征对于识别左欺诈节点至关重要。但是,两个节点之间没有链接,这会降低基于 GNN 的方法的性能。
从算法方面来看,挑战来自于 GNNs[11、16、38、43、44] 的消息聚合,这可能导致少数类的特征被稀释的结果。回想一下,图神经网络的关键设计在于邻域聚合,但在不平衡的设置中,中心节点的大多数邻居可能属于多数类。例如,如图 1 所示,六个邻居中只有一个与左中心节点属于同一欺诈类别。结果,欺诈邻居的特征很容易被忽略,预测很容易被大多数良性特征所支配。
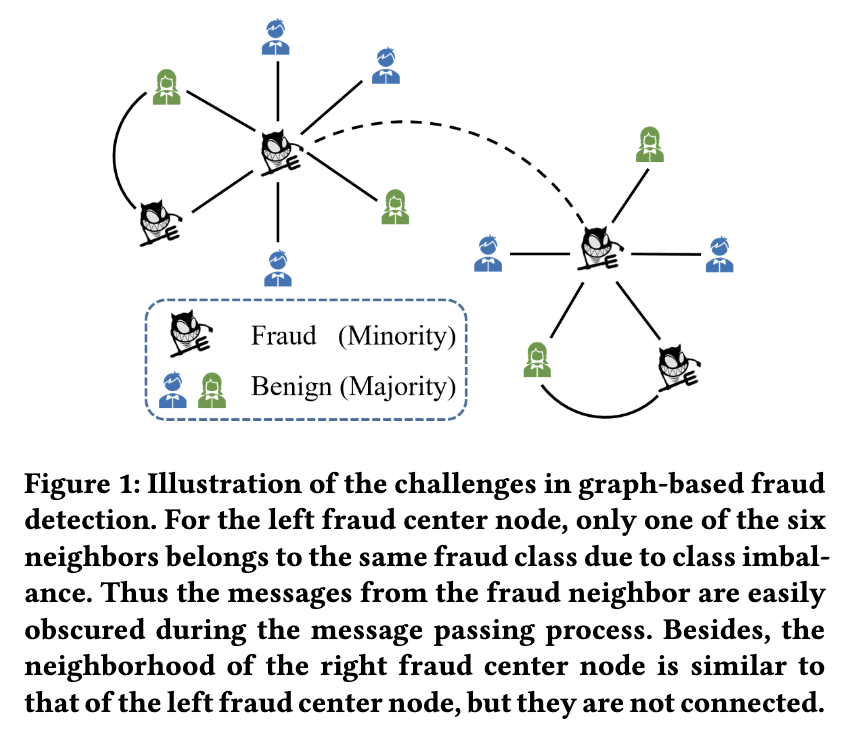
(图 1:基于图形的欺诈检测中挑战的图示。对于左侧欺诈中心节点,由于类别不平衡,六个邻居中只有一个属于同一欺诈类别。因此,来自欺诈邻居的消息在消息传递过程中很容易被掩盖。此外,右欺诈中心节点的邻域与左欺诈中心节点的邻域相似,但它们不相连。)
为了应对上述挑战,在本文中,我们提出了一种基于 GNN 的不平衡学习方法,用于基于图的欺诈检测。对于算法方面的挑战,我们设计了一个标签平衡的采样器来选择要训练的节点和边。分配给每个节点的概率与其标签频率成反比,因此少数类的节点更有可能被选中。因此,所选取节点的诱导子图将具有平衡的标签分布。
针对应用端的挑战,我们提出了一种邻域采样器来选择具有可学习参数化距离函数的邻域。
对于欺诈目标节点,可以通过选择距离目标较远的邻居并将其从邻居集中删除来过滤冗余链接。并且将通过选择欺诈类的相似节点并将它们视为邻居来创建有利于欺诈预测的必要链接。
我们将图采样和邻居选择的上述两个阶段集成到通用 GNN 框架中,并将我们的模型命名为 Pick and Choose Graph Neural Network (PC-GNN)。我们的贡献可以列示如下。
我们将基于图的欺诈检测问题表述为不平衡节点分类任务,并提出了一种基于 GNN 的不平衡学习方法来解决图上的类不平衡问题。
我们设计了一个标签平衡采样器来选择节点和边进行子图训练,并设计了一个邻域采样器来选择邻居来对少数类的邻域进行过采样,并对多数类的邻域进行欠采样。
对两个公共基准数据集和两个真实世界的数据集进行了广泛的实验,以验证所提出框架的有效性。
本文的其余部分组织如下。第 2 节介绍了本文的定义和问题陈述。第 3 节详细介绍了所提出的 PC-GNN 框架,第 4 节说明了实验。第 5 节调查文献中的相关研究,第 6 节总结本文。
2 定义和问题陈述
2.1 定义
定义 2.1(不平衡比率)。给定一组标签 C,C1 和 C2 表示 C 中的两个类。C1 和 C2 的不平衡比率定义为 IR = | C1 | / | C2 | .因此,IR 位于 [0, +∞) 范围内。如果 IR > 1,则 C1 称为多数类,C2 称为少数类。特别地,如果 IR = 1,则 C 是平衡的。
定义 2.2(多关系不平衡图)。给定图 G = (V, E, A, X, C),V = {v1, . . . ,vN }是一组节点,E = {E1, . . . ,ER }为R关系的边集,A = {A1, . . . , AR } 是一组对应的R关系邻接矩阵。对于每个节点 vi ∈ V,xi ∈ X 是一个 d 维特征向量,ci ∈ C 是一个标量标签,i = 1, . . . ,N. X 和 C 分别是节点特征和标签的集合。如果 C 中两个类的不平衡率远大于 1,我们称 G 为多关系不平衡图。
2.2 问题陈述
定义 2.3(基于图形的欺诈检测)。基于图的欺诈检测问题定义在多关系不平衡图 G = (V, E, A, X, C) 上,已在定义 2.2 中制定。 V中的每个节点都在C中被标记为欺诈或良性。基于图的欺诈检测是在多关系不平衡图G上找到与其他良性节点有显着差异的欺诈节点,可以表示为G 上的不平衡节点分类问题。
3 方法
在本节中,我们介绍了提出的 PC-GNN 框架。首先,我们给出整个框架的概述。然后,我们分别在 3.2 节和 3.3 节中详细介绍了挑选过程和选择过程。接下来,我们将在 3.4 节中解释如何聚合来自不同邻居和关系的信息.
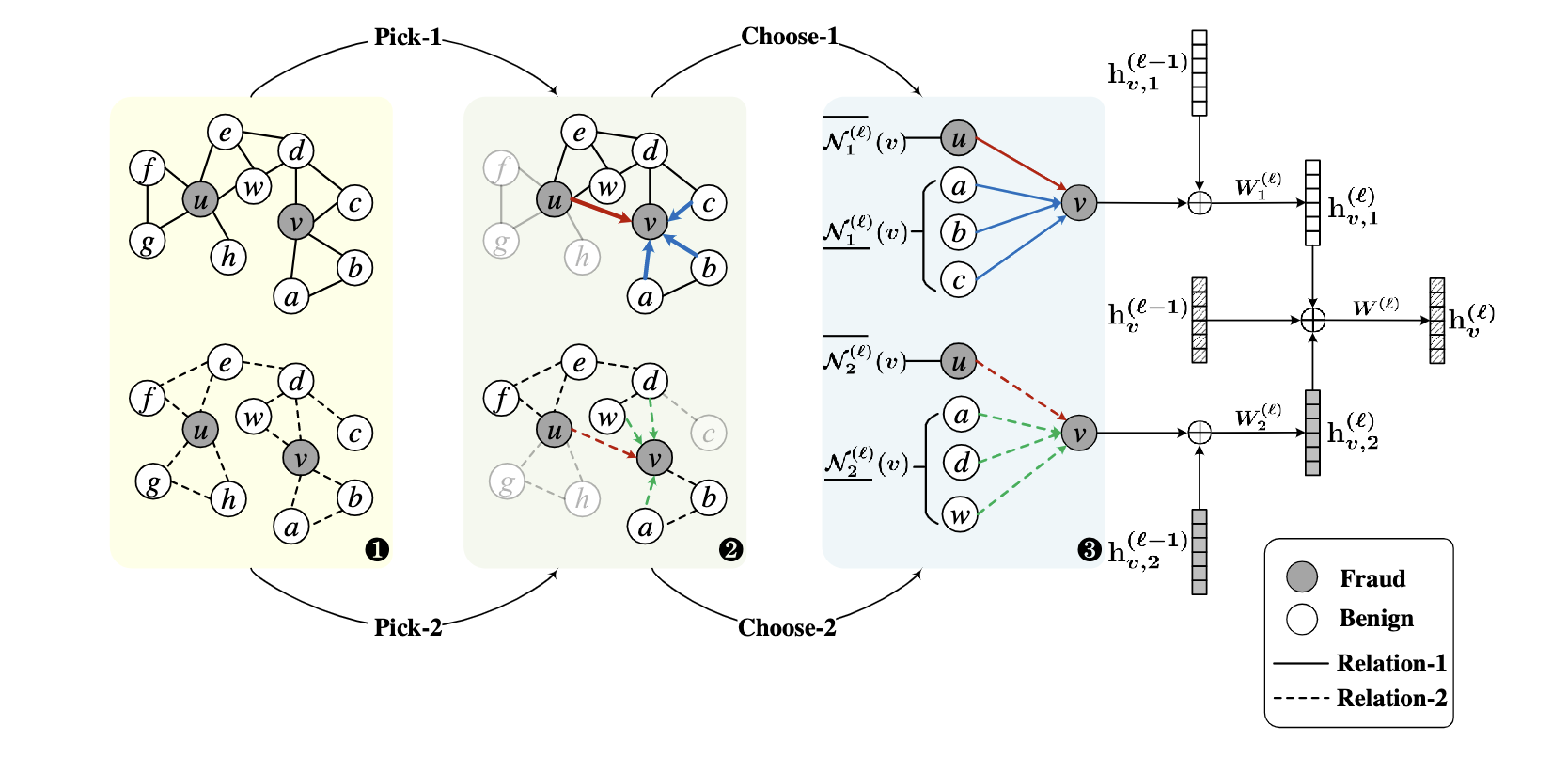
(图 2:该图在示例图上展示了所提出的 PC-GNN 框架的第 ℓ 层。 ❶ 显示包含 11 个节点的示例图。实线和虚线表示这些节点之间的两种关系。灰色节点是欺诈节点,白色节点是良性节点。从 ❶ 到 ❷,使用标签平衡采样器选择节点和边的子集来构建用于小批量训练的子图。 ❷ 说明了由拾取节点诱导的子图,其中未采样的节点和边被模糊。从 ❷ 到 ❸,邻居由邻域采样器选择。对于❷中的欺诈节点v,邻域被![]() 过采样,与v相似但不直接相连。同时,v的原始邻居集被欠采样
过采样,与v相似但不直接相连。同时,v的原始邻居集被欠采样![]() ,其中学习距离函数下的不同节点被移除。在不同的关系下,如 ❸ 所示,为 v 选择的邻居可能不同,例如
,其中学习距离函数下的不同节点被移除。在不同的关系下,如 ❸ 所示,为 v 选择的邻居可能不同,例如 ![]() 不同于
不同于 ![]() 。最后,聚合所有的邻居信息,并将来自不同关系的嵌入连接起来,得到 v 在层 ℓ 的最终表示,在图中表示为
。最后,聚合所有的邻居信息,并将来自不同关系的嵌入连接起来,得到 v 在层 ℓ 的最终表示,在图中表示为 ![]() 。)
。)
3.1 概述
我们在图 2 的示例图上说明了所提出框架的管道。要获得目标实体的表示,主要有三个步骤:挑选、选择和聚合。在选择步骤中,我们设计了一个标签平衡采样器来选择节点和边进行子图训练。接下来,在选择步骤中,我们设计了一个邻域采样器,对少数类的邻居进行过采样,对多数类的邻居进行欠采样。最后,在聚合步骤中,我们聚合来自采样邻居和不同关系的信息。
3.2选择: 标签平衡采样器
我们设计了一个标签平衡图采样器来选择节点和边来构建子图。关键思想在于将标签分布信息纳入采样过程。对于节点采样器,少数类的采样概率高于多数类。
形式上,G = (V, E, A, X, C) 是一个多关系不平衡图,![]() 是所有关系的邻接矩阵之和,
是所有关系的邻接矩阵之和,![]() 是归一化的邻接矩阵,其中 D 是以每个节点的度作为其元素的对角矩阵。对于节点 v ∈ V,其采样概率定义为等式(1).
是归一化的邻接矩阵,其中 D 是以每个节点的度作为其元素的对角矩阵。对于节点 v ∈ V,其采样概率定义为等式(1).

其中 ^A(:,v) 是归一化邻接矩阵 ^A 中 v 的列,LF(C(v)) 表示类 C(v) 的标签频率。选取的节点集标记为 Vp ,Gp = (Vp , Ep , Ap , Xp , Cp ) 是由 Vp 及其单跳邻居导出的子图。
3.3选择: 邻域采样器
在选择步骤之后,对导出的子图 Gp 进行以下步骤。为了符号清晰,我们在以下部分中省略了下标 p,即我们将 Ap 中的邻接矩阵表示为 ,将 Ep 中的边表示为
![]() 。节点 v 在每个关系 Er 下的邻居都收集在集合
。节点 v 在每个关系 Er 下的邻居都收集在集合 ![]() 中,如等式(2) 显示。
中,如等式(2) 显示。
![]()
正如第 1 节中所讨论的,采用方程式 (2) 这样的邻居定义是不合适的。在不平衡图中,因为 Nr (v) 可能包含伪装的邻居或缺少对预测至关重要的必要节点。为了缓解这个问题,我们应该对多数类的邻域进行欠采样以过滤掉那些嘈杂的邻居,并对少数类的邻域进行过采样以添加有用的边。
实际上,我们在多数类邻域的定义中添加一个约束,以过滤那些在一定距离函数下远离目标节点的邻居。节点 v 的欠采样邻居集由 Nr (v) 表示,如等式 (3) 表明,显然![]() 。
。
![]()
3.3.1 距离函数。
距离函数 D(·,·) 取决于潜在空间中的特定度量。潜在空间中广泛使用的距离函数是特征的欧氏距离,即 D(v, u) = ∥xv − xu ∥,其中 xv ∈ Rd 表示节点 v 的特征。但是,这个距离函数不灵活在欺诈检测中,因为它不考虑标签信息。因此,受 LAGCN[6] 的启发,我们采用了结合潜在嵌入和真实标签信息的参数化距离函数,定义如下:
![]()
其中 ![]() 是一个全连接层,基于学习到的嵌入
是一个全连接层,基于学习到的嵌入 ![]() 预测欺诈概率节点 v 在关系 Er 和
预测欺诈概率节点 v 在关系 Er 和 ![]() 层是距离函数的权重矩阵。距离定义为 v 和 u 的预测概率之差。
层是距离函数的权重矩阵。距离定义为 v 和 u 的预测概率之差。
3.3.2邻域抽样。
因此,欠抽样的邻域被重写为方程(5)。
![]()
此外,v的邻域(属于少数类)可以被图上远离v但与v有一定相似性的节点过采样,可以表示为![]() 和制定为方程式(6)
和制定为方程式(6)
![]()
综上所述,对于多数类的目标节点v,v的邻域欠采样 ![]() ;对于少数类的目标节点v, v的邻域被过采样
;对于少数类的目标节点v, v的邻域被过采样![]()
3.3.3 学习。
由于距离函数的参数化,邻域采样器是可学习的。距离函数的参数包括 ![]() 的权重,即
的权重,即 ![]() ,它用交叉熵损失优化为等式 (7).
,它用交叉熵损失优化为等式 (7).

3.4 聚合:消息传递架构
在选择步骤之后,![]() 在关系 Er 下收集少数类的过采样邻域或多数类的欠采样邻域。基于消息传递的图神经网络旨在聚合来自所有邻居和关系的信息。令
在关系 Er 下收集少数类的过采样邻域或多数类的欠采样邻域。基于消息传递的图神经网络旨在聚合来自所有邻居和关系的信息。令 ![]() 表示节点 v 在关系 Er 下ℓ 层的表示,其中 v ∈ V, r = 1, . . . , R, ℓ = 1, . . . , L 和 L 是层数。
表示节点 v 在关系 Er 下ℓ 层的表示,其中 v ∈ V, r = 1, . . . , R, ℓ = 1, . . . , L 和 L 是层数。
聚合步骤进一步分为两个步骤。首先,在每个关系下,如Eq.(8)所示,对所选邻居的所有信息进行聚合,其中AGG(r)r为关系Er下的层r的平均聚合器函数,⊕表示连接操作,![]() 为权矩阵。
为权矩阵。
![]()
然后,我们需要将每个 ![]() 与前一层
与前一层 ![]() 的表示相结合,以获得第 ℓ 层中的
的表示相结合,以获得第 ℓ 层中的 ![]() ,如等式 (9)所示。
,如等式 (9)所示。 ![]() 为权重矩阵。
为权重矩阵。
![]()
3.5 训练
在聚合步骤之后,MLP 分类器与图形神经网络一起训练,以最小化交叉熵损失。
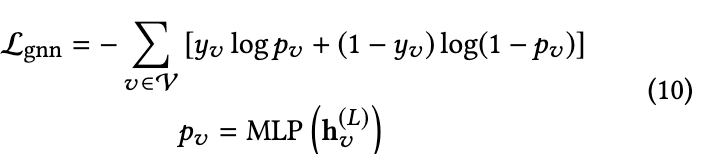
总损失函数公式为 (11),其中 α 是平衡参数。
![]()
算法 1 总结了整体训练算法。给定多关系不平衡图 G 和训练节点集 Vtrain,我们首先根据等式中的采样概率从 Vtrain 中选取节点。 (1) 用于训练(第 3 行)。这些节点被分成大小为 Nbatch 的小批量(第 6 行)。对于每个批次的每个子图中的节点,根据其标签频率对其邻居进行过采样或欠采样(第 9 行)。然后聚合来自所选邻居的消息(第 10 行),并连接不同关系的表示(第 11 行)。
4 实验
在本节中,我们研究了所提出的 PC-GNN 模型在两种基于图的欺诈检测任务(即意见欺诈检测和金融欺诈检测)上的有效性,目的是回答以下研究问题。
• RQ1:PC-GNN 是否优于基于图的异常检测的最先进方法?
• RQ2:关键组成部分如何有利于预测?
• RQ3:不同训练参数的表现如何?
• RQ4:如果将提议的模块应用于其他GNN 模型,是否会带来性能提升?