论文信息
number headings: auto, first-level 2, max 4, _.1.1
name_en: LLaMA: Open and Efficient Foundation Language Models
name_ch: LLaMA: 开放高效的基础语言模型
paper_addr: https://arxiv.org/abs/2302.13971
doi: https://doi.org/10.48550/arXiv.2302.13971
date_read: 2023-03-25
date_publish: 2023-02-27
tags: [‘深度学习’,‘自然语言处理’]
author: Hugo Touvron, Meta AI
citation: 7
code: https://github.com/facebookresearch/llama
1 读后感
开源项目,以小取胜。使用更多token训练,更少的模型参数。其小模型可以运行在单GPU环境下,65B大模型可与PaLM模型效果竞争;主要技术包含:调整了模型结构,加速了训练和推理。
2 摘要
论文展示了仅使用公开可用的数据集来训练最先进的模型,而无需诉诸专有和不可访问的数据集。模型从7B-65B参数,使用T级别token训练。LLaMA-13B模型效果超越了GPT-3(175B)模型。LLaMA-65B模型可与当前最好模型竞争。
3 介绍
大模型在Few Shot上表现好,主要归功于大模型的参数量。本文至力于找到合适的数据量和参数量,以实现快速推理。
4 方法
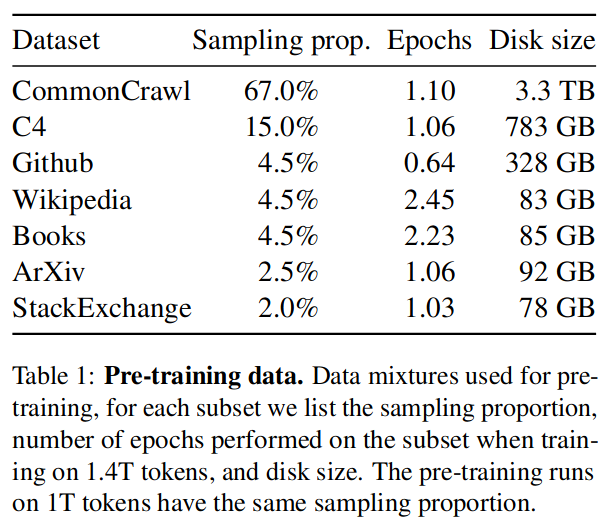
4.1 预测训练数据
4.2 模型结构
模型基于Transformer结构,与其它框架主要有以下差别(基本都是2019-2021年,其它模型用过的技术):
- 预归一化:
使用RMSNorm对每个 transformer 子层的输入进行归一化,而不是对输出进行归一化,以提升稳定性。 - SwiGLU激活函数:
使用SwiGLU代替ReLU激活函数。 - 位置嵌入:
在网络的每一层,删除了绝对位置嵌入,添加旋转位置嵌入。
4.3 优化
模型规模如下:

4.4 高效实施
使用因果多头注意力算子的高效实现,减少了内存使用和计算。为进一步提高训练效率,减少了在带有检查点的反向传播过程中重新计算的激活量(替代了Pytorch autograd)。通过使用模型和序列并行性减少模型的内存使用。此外,还尽可能多地重叠激活计算和 GPU 之间的网络通信。
在训练 65B 参数模型时,代码在具有 80GB RAM 的 2048 A100 GPU。对包含 1.4T 令牌的数据集进行训练大约需要 21 天。
5 主实验
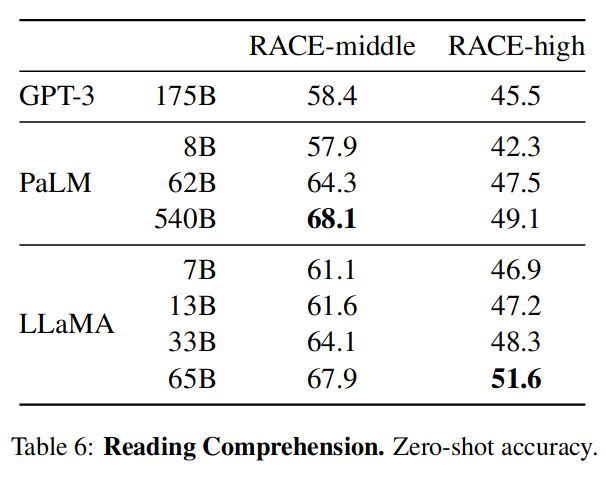
针对Zero-shot和Few-shot任务评测,以下是对阅读理解的评测,可以看到大模型和小模型对这类问题处理差别不大:
对下述功能进行了评测,不在此抓图说明,结果就是其65B模型和PalM540模型效果差不多,很多评测效果还更好。
- 标准常识推理 (8个)
- 闭卷答疑(2个)
- 阅读理解(1个)
- 数学推理(2个)谷歌的Minerva模型针对数学训练,效果更好
- 代码生成(2个)
- 大规模多任务语言理解。由多项选择题组成,涵盖各个知识领域,包括人文、STEM 和社会科学。在此评测中PaLM明显更好,可能因为训练它的语料更多。
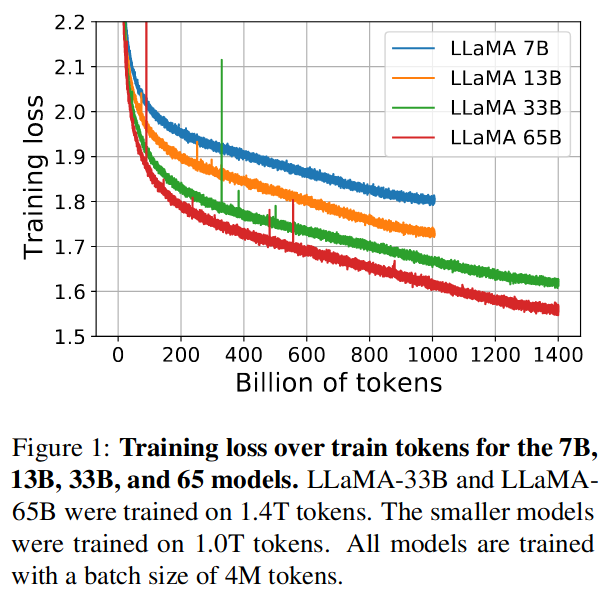
可以看到token越多,训练效果越好:
6 指令微调
通过精调训练了一个引导模型 LLaMA-I,对于MMLU(57种主题的多选题)评测数据对比结果如下:
