1 前言
本期内容,笔者想解析一下自然语言处理(NLP)中非常有名的基于变换器的双向编码器表示技术(即Bidirectional Encoder Representations from Transformers,BERT)。
想当年(2019年),BETR的出现也是横扫了自然语言处理领域多项任务,甚至压住了ChatGPT的早期版本(OpenAI GPT )。
这里需要注意,BERT并不是一类模型的缩写,笔者认为其更像是指代一套框架,核心在于其自监督训练策略。
再看本文之前,我强烈推荐大家去看一下台大李宏毅老师的深度学习课程。具体链接如下:
“https://www.bilibili.com/video/BV1m3411p7wD?p=48&vd_source=beab624366b929b20152279cfa775ff6
本文也将使用李老师的课程截图进行讲解(没办法,他讲的太好了)。
2 BERT解析
2.1 简介
BERT,全称叫做Bidirectional Encoder Representations from Transformers。从其名称可以看出,该模型是基于Transformer的。更具体地,BERT的网络结构其实就是Transformer的编码器,其输入一段序列(如文字序列),输出一段等长的序列。
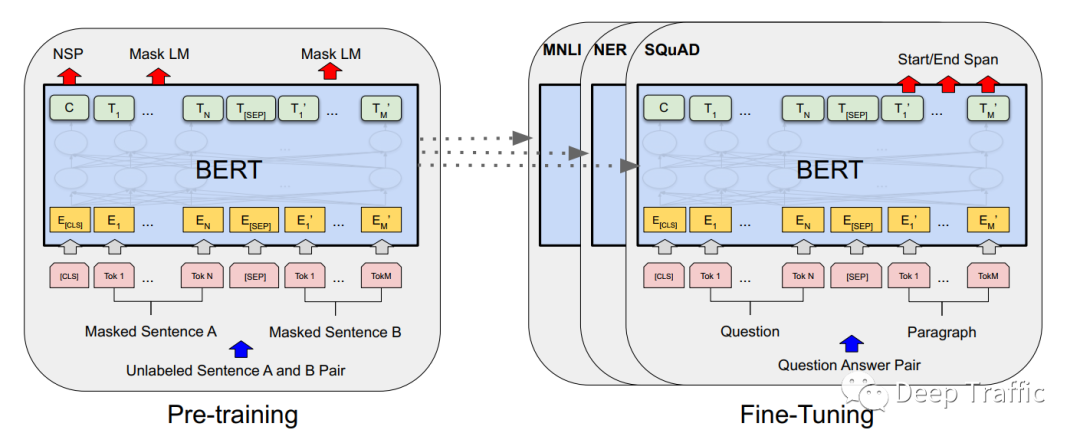
如下图1所示,训练时BERT先是基于大量未标注的语料库进行自监督学习(预训练),然后基于标注良好的数据集(特定的NLP任务,如情感分类等)进行模型微调。这种“预训练+微调“使得模型在各个NLP任务的效果大幅提升,其收敛速度也快了很多。
2.2 自监督预训练
介绍BERT之前,需要和大家简单了解一下何为自监督学习。我们知道,Transformer的优势在于并行和表征能力强,但缺点就是需要大量标注数据进行训练。
为了解决标注数据的数据量问题,近些年关于无监督和自监督的研究开始变得火起来了 。从某种程度上来说,自监督也可以视为无监督,因为自监督的监督信号来源于数据本身的内容,而不是人工标注。
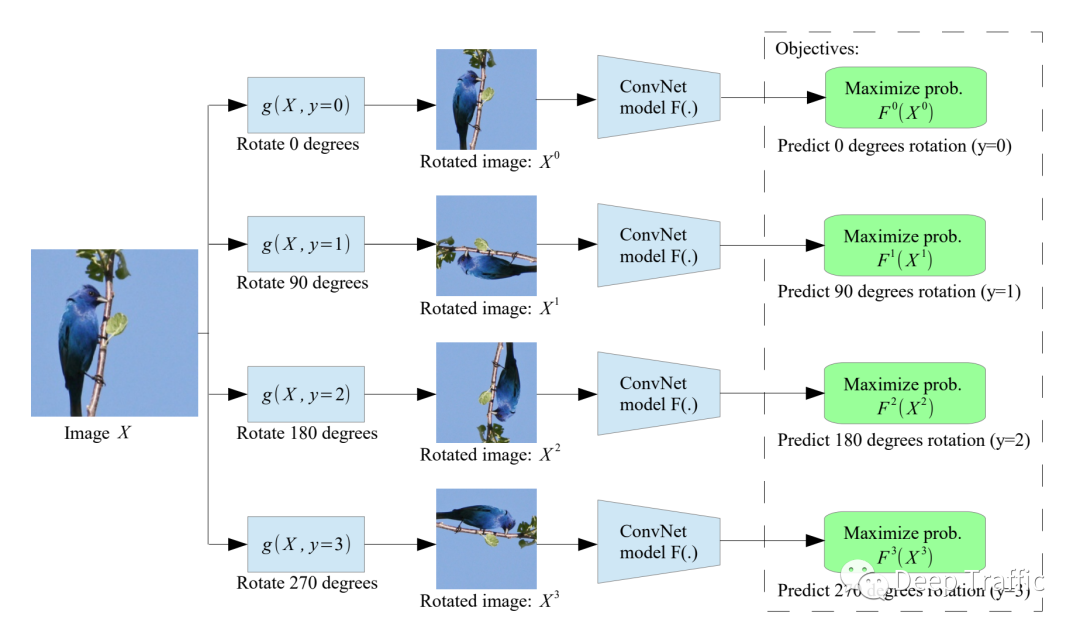
这里举个视觉领域常见的自监督学习例子,如下图2所示。为了监督模型学习到合适的图像特征,一些研究将图像进行旋转(如旋转90度)喂给视觉模型(比如CNN),监督信息就是旋转角度。在这种情况下,模型接受一张图像(可能被旋转了)为输入,预测该图像的旋转角度。以这种方式,模型无需人工费时费力的标注信息,也能学到较好的图像表征。
那么,Transformer能否也利用自监督学习从大量未标注的语料库里面进行学习呢?
答案是显然的。本文要介绍的BERT,其核心就是一种自监督训练策略。具体地,该训练策略主要包含两个策略:
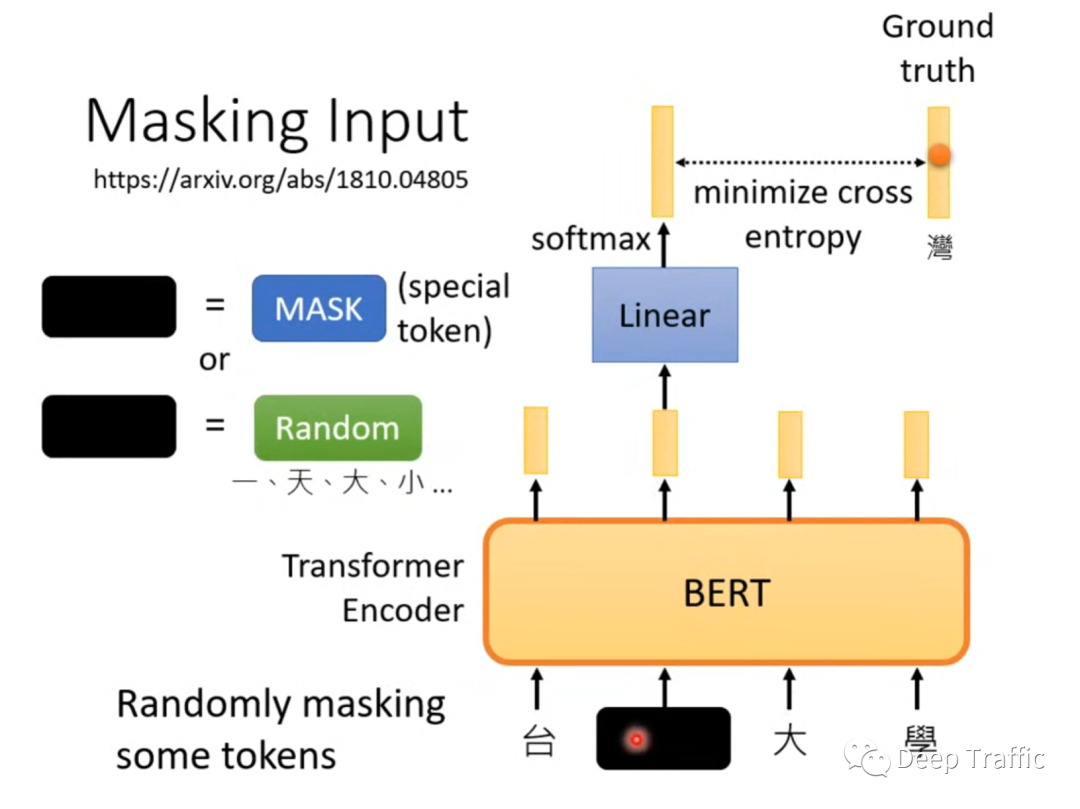
一是“猜词”训练。也就是随机将输入序列的一些词汇进行遮挡或者随机换成其他词(遮挡也是替换成特殊字符<mask>),然后让模型去猜被遮挡的词是什么,如下图3所示。
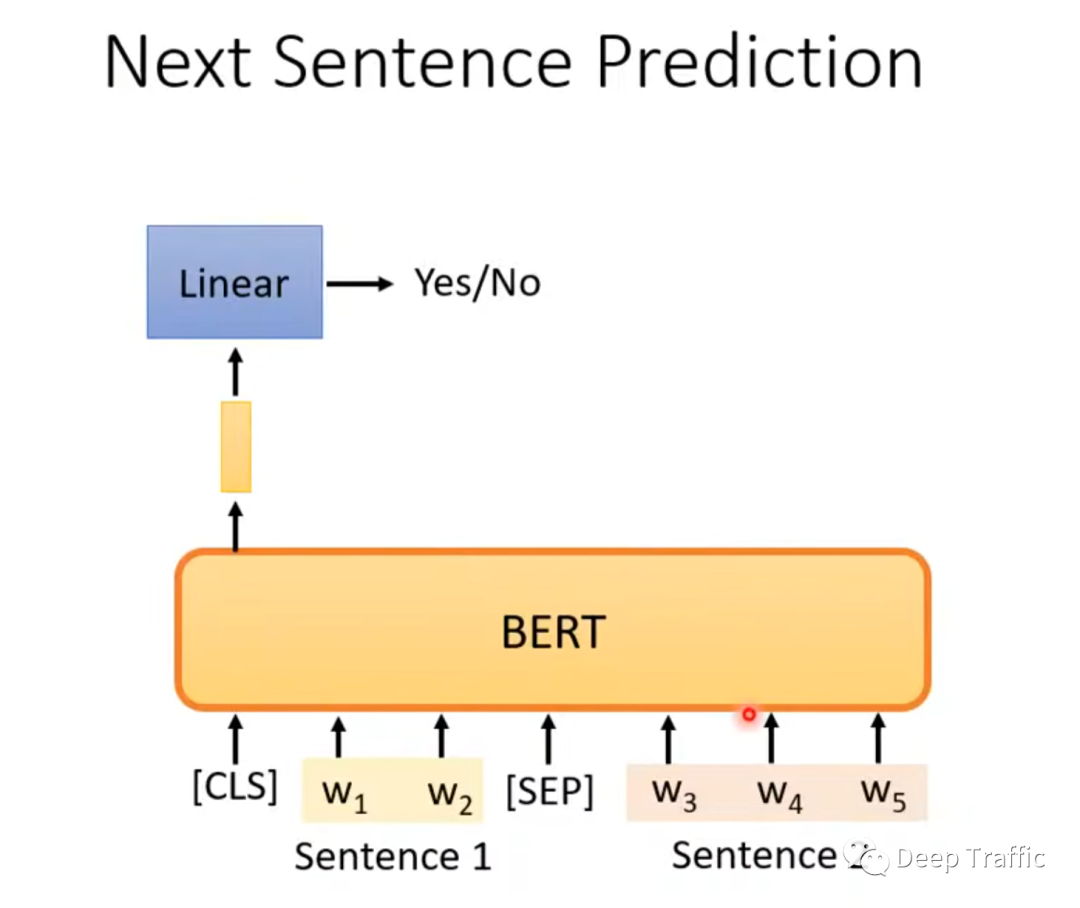
二是“判断句子是否连续”。也就是随机从语料库中抽两个句子,然后将两个句子用特殊符号(<sep>)分隔开,并且在两个句子前面加个特殊符号(<cls>)。然后取特殊符号<cls>处对应的输出特征,用以二分类任务输入(判断句子连续或不连续),如下图4所示。后续研究表明,这个训练策略效果不明显。按李宏毅老师的意思是,这个训练任务太简单了,模型学不到什么东西。
2.3 微调
经过上面的自监督训练后,模型事实上只学会了两个任务,即“猜词”和“判断两个句子是否连续”。如果要实现诸如语句情感分类、词性标注、自然语言推理、问答等任务,那么还需要对预训练的BERT进行微调。具体微调方式因任务的差异而不同,这里以4个任务为例。
(1)语句情感分类
语句情感分类任务中,网络模型以一段文字为输入,推理该文字背后所附带的情绪是什么。最常见的,比如商品的好评和差评分类。那么,如何使用预训练好的BERT来实现语句的情感分类呢?
如图5所示,先利用BERT来提取文字的语义特征,然后将特殊符号(<cls>)处对应的特征输入至全连接层,输出类别概率。需要注意的是,这里的BERT的初始化权重为预训练BERT模型的权重,而全连接层的权重随机初始化。
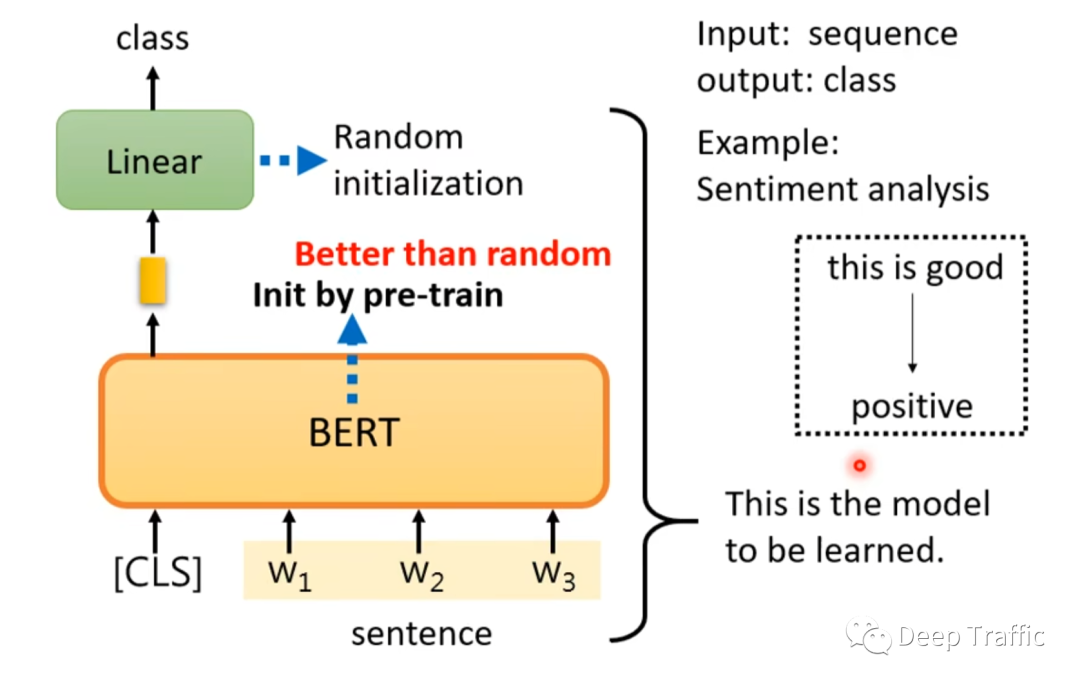
就类似于图像分类领域中使用基于ImageNet预训练的权重初始化CNN模型,然后随机初始化最后用于分类的全连接层,能够达到模型快速收敛的效果。
(2)词性标注
所谓词性标注任务,是将一段自然语言文本中的每个单词标注为其相应的词性,如名词、动词、形容词等。它是自然语言处理的基础任务之一,对于许多其他任务,如命名实体识别、句法分析等都有重要的作用。这样的话,输入模型一段文本序列,将获得一段等长的输出序列。
这种等长的Sequence2Sequence在BERT中是如何实现的呢?
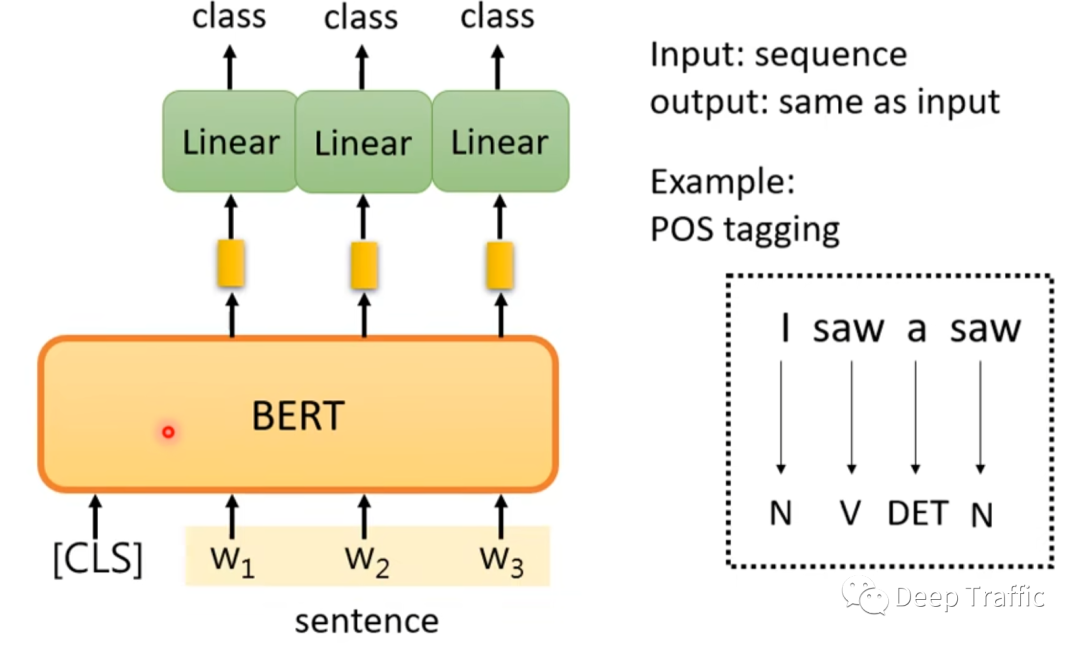
如图6所示,Transformer特点是输入序列和输出序列是等长的,那么只需要取BERT中输入序列对应位置的特征,然后利用全连接层将这些特征映射为相应的词性类别概率即可。这里和语句情感分类任务一样,BERT的初始化权重为预训练BERT模型的权重,而全连接层的权重随机初始化。
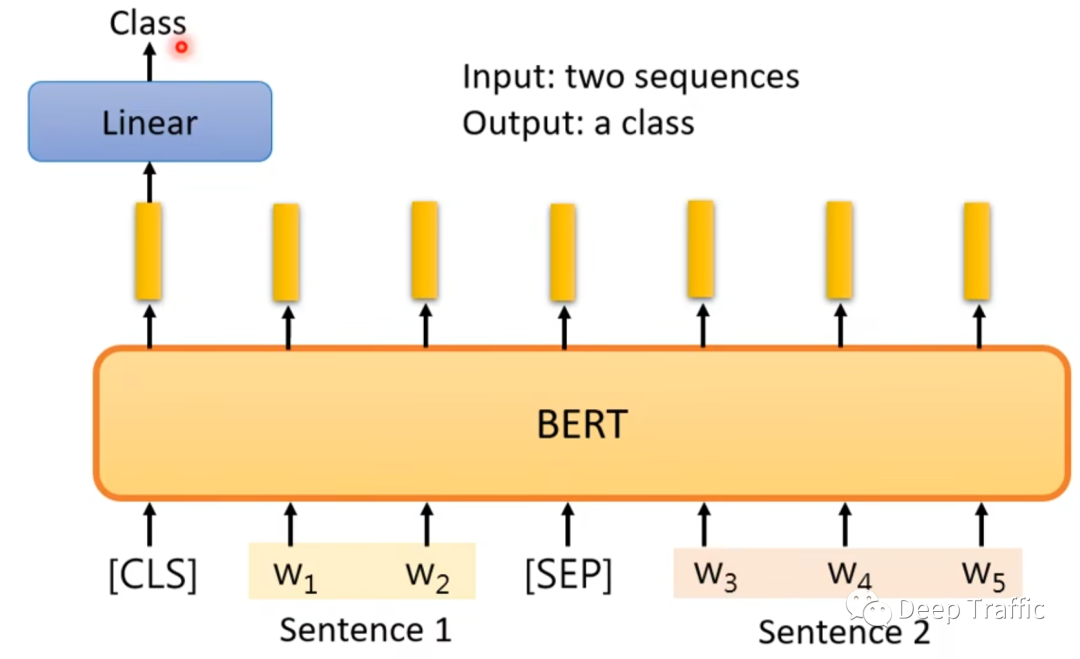
(3)自然语义推理
所谓自然语义推理,就是利用语言模型来判断句子间的关系,这种关系是以类别形式呈现。
例如,如图7所示,给定两个句子,一个句子是前提(premise),一个句子是假设(hypothesis),将这两个句子同时输入到模型中,判断这两个句子的关系,是矛盾、蕴涵还是中性的。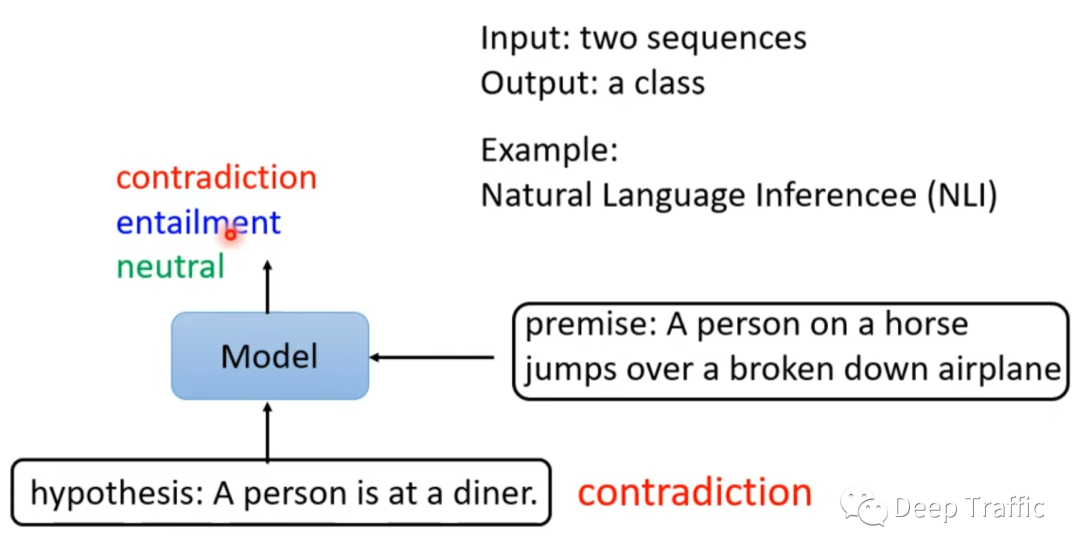
那么这种情况在BERT中是如何实现的呢?
如图8所示,作者将两个句子之间用特殊符号(<sep>)隔开,在句子之前嵌入一个特殊符号(<cls>)。之后,将该句子喂给BERT模型,然后取BERT中特殊符号(<cls>)处对应的特征,将其输入至全连接层后,输出预测的类别概率。相同地,BERT的初始化权重为预训练BERT模型的权重,而全连接层的权重随机初始化。
上面这个微调方式与预训练中“判断两个句子是否连续”的方法如出一辙。
(4)问答
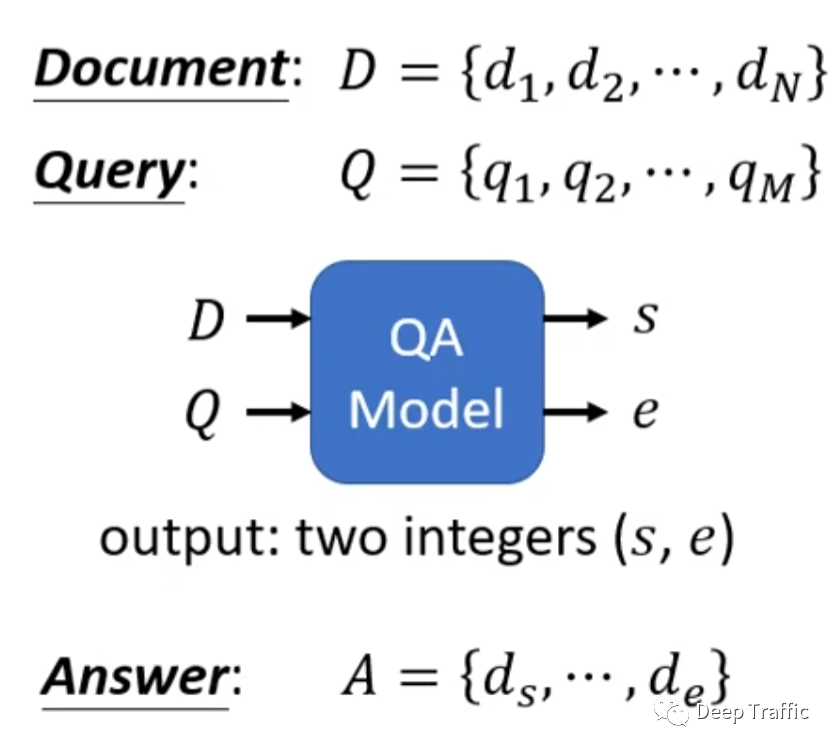
最后,聊一个稍微难一点的任务,即问答。所谓问答,就是给定一个文档(稍微长一些的文字序列),给定一个问题(稍微短一些的文字序列),然后在文档中找到能够回应这个问题的答案。需要注意的是,这个答案是可以直接在文档中找到的。
那么这个任务可以视为根据文档和问题,在文档中找到答案的起止位置,如图9所示。
该问题在BERT中的实现方法如下图10和11所示。
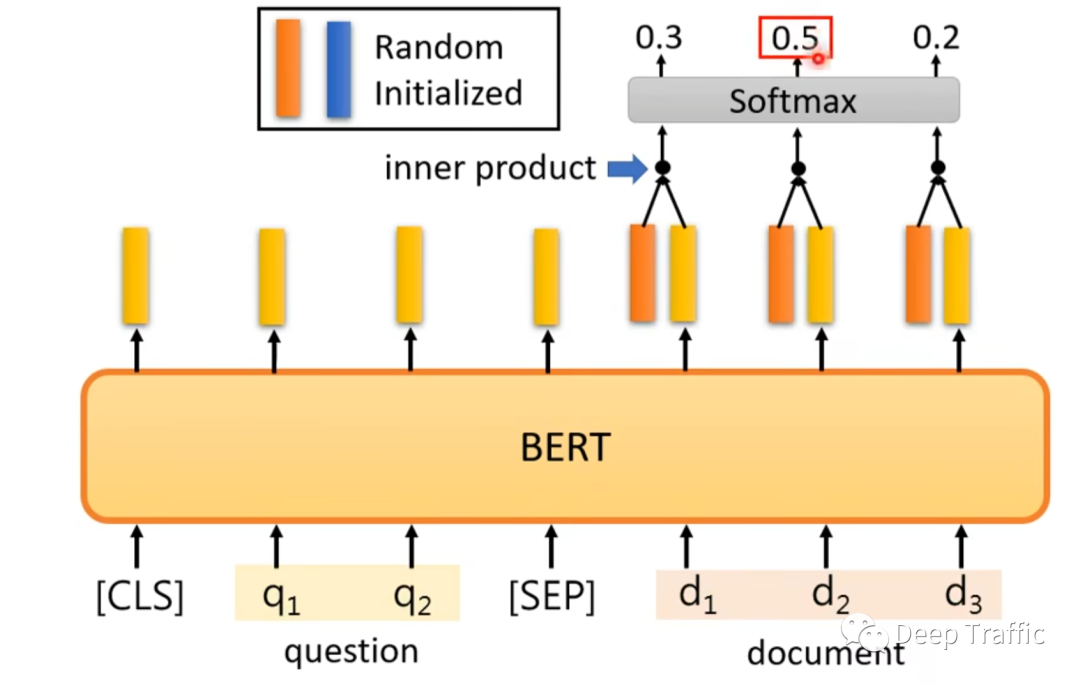
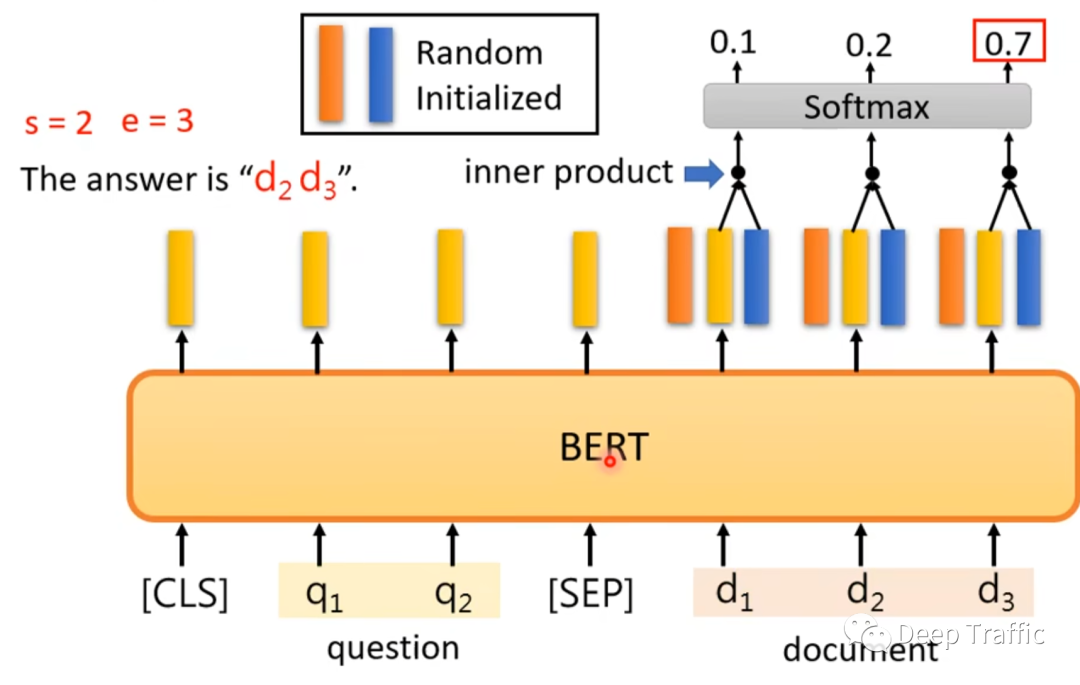
仍然是以两个句子(问题在前,文档在后)为输入,其中两个句子之间用特殊符号(<sep>)隔开,在句子之前嵌入一个特殊符号(<cls>)。
利用两个随机初始化的向量(不妨记做起始向量和终止向量)分别对文档()通过BERT后输出的各个特征进行内积,然后利用softmax分别输出起止位置的概率分布,如图10和11所示。
这里大家可能会有一个疑问,也就是为什么这么粗暴的向量设置也能使得模型训练起来?
事实上,只要起始向量和终止向量随机初始化后保持固定不变。那么在微调过程中,模型会逐渐知道随机初始化的起始向量会专注于寻找答案的左边界,而终止向量会专注于寻找答案的右边界。
至此,关于BERT在不同NLP任务上的微调过程就基本解析完毕了。
2.4 Python代码
上面简单讲完BERT的预训练和微调后,相信大家应该有了初步的印象。这里我们提供一些代码+相应的注释,让大家对BERT的实现流程更熟悉,具体代码的链接为:
“https://github.com/codertimo/BERT-pytorch
这里我们自顶而下看一下BERT的预训练过程。
class BERTTrainer:
"""
BERTTrainer make the pretrained BERT model with two LM training method.
1. Masked Language Model : 3.3.1 Task #1: Masked LM
2. Next Sentence prediction : 3.3.2 Task #2: Next Sentence Prediction
please check the details on README.md with simple example.
"""
def __init__(self, bert: BERT, vocab_size: int,
train_dataloader: DataLoader, test_dataloader: DataLoader = None,
lr: float = 1e-4, betas=(0.9, 0.999), weight_decay: float = 0.01, warmup_steps=10000,
with_cuda: bool = True, cuda_devices=None, log_freq: int = 10):
# Setup cuda device for BERT training, argument -c, --cuda should be true
cuda_condition = torch.cuda.is_available() and with_cuda
self.device = torch.device("cuda:0" if cuda_condition else "cpu")
# This BERT model will be saved every epoch
self.bert = bert
# Initialize the BERT Language Model, with BERT model
self.model = BERTLM(bert, vocab_size).to(self.device)
# Distributed GPU training if CUDA can detect more than 1 GPU
if with_cuda and torch.cuda.device_count() > 1:
print("Using %d GPUS for BERT" % torch.cuda.device_count())
self.model = nn.DataParallel(self.model, device_ids=cuda_devices)
# Setting the train and test data loader
self.train_data = train_dataloader
self.test_data = test_dataloader
# Setting the Adam optimizer with hyper-param
self.optim = Adam(self.model.parameters(), lr=lr, betas=betas, weight_decay=weight_decay)
self.optim_schedule = ScheduledOptim(self.optim, self.bert.hidden, n_warmup_steps=warmup_steps)
# Using Negative Log Likelihood Loss function for predicting the masked_token
self.criterion = nn.NLLLoss(ignore_index=0)
self.log_freq = log_freq
print("Total Parameters:", sum([p.nelement() for p in self.model.parameters()]))
def train(self, epoch):
self.iteration(epoch, self.train_data)
def test(self, epoch):
self.iteration(epoch, self.test_data, train=False)
def iteration(self, epoch, data_loader, train=True):
"""
loop over the data_loader for training or testing
if on train status, backward operation is activated
and also auto save the model every peoch
:param epoch: current epoch index
:param data_loader: torch.utils.data.DataLoader for iteration
:param train: boolean value of is train or test
:return: None
"""
str_code = "train" if train else "test"
# Setting the tqdm progress bar
data_iter = tqdm.tqdm(enumerate(data_loader),
desc="EP_%s:%d" % (str_code, epoch),
total=len(data_loader),
bar_format="{l_bar}{r_bar}")
avg_loss = 0.0
total_correct = 0
total_element = 0
for i, data in data_iter:
# 0. batch_data will be sent into the device(GPU or cpu)
data = {key: value.to(self.device) for key, value in data.items()}
# 1. forward the next_sentence_prediction and masked_lm model
next_sent_output, mask_lm_output = self.model.forward(data["bert_input"], data["segment_label"])
# 2-1. NLL(negative log likelihood) loss of is_next classification result
next_loss = self.criterion(next_sent_output, data["is_next"])
# 2-2. NLLLoss of predicting masked token word
mask_loss = self.criterion(mask_lm_output.transpose(1, 2), data["bert_label"])
# 2-3. Adding next_loss and mask_loss : 3.4 Pre-training Procedure
loss = next_loss + mask_loss
# 3. backward and optimization only in train
if train:
self.optim_schedule.zero_grad()
loss.backward()
self.optim_schedule.step_and_update_lr()
# next sentence prediction accuracy
correct = next_sent_output.argmax(dim=-1).eq(data["is_next"]).sum().item()
avg_loss += loss.item()
total_correct += correct
total_element += data["is_next"].nelement()
post_fix = {
"epoch": epoch,
"iter": i,
"avg_loss": avg_loss / (i + 1),
"avg_acc": total_correct / total_element * 100,
"loss": loss.item()
}
if i % self.log_freq == 0:
data_iter.write(str(post_fix))
print("EP%d_%s, avg_loss=" % (epoch, str_code), avg_loss / len(data_iter), "total_acc=",
total_correct * 100.0 / total_element)上述代码的核心在iteration函数中,可见BERT的训练受到两个损失函数(即next_loss 和mask_loss)的监督。这两个损失函数分别来自两个不同的任务,即前面提到的“判断两个句子是否连续”以及“猜词”。
接着,我们来通过代码看一下这个BERT的网络结果长啥样,如下:
class BERT(nn.Module):
"""
BERT model : Bidirectional Encoder Representations from Transformers.
"""
def __init__(self, vocab_size, hidden=768, n_layers=12, attn_heads=12, dropout=0.1):
"""
:param vocab_size: vocab_size of total words
:param hidden: BERT model hidden size
:param n_layers: numbers of Transformer blocks(layers)
:param attn_heads: number of attention heads
:param dropout: dropout rate
"""
super().__init__()
self.hidden = hidden
self.n_layers = n_layers
self.attn_heads = attn_heads
# paper noted they used 4*hidden_size for ff_network_hidden_size
self.feed_forward_hidden = hidden * 4
# embedding for BERT, sum of positional, segment, token embeddings
self.embedding = BERTEmbedding(vocab_size=vocab_size, embed_size=hidden)
# multi-layers transformer blocks, deep network
self.transformer_blocks = nn.ModuleList(
[TransformerBlock(hidden, attn_heads, hidden * 4, dropout) for _ in range(n_layers)])
def forward(self, x, segment_info):
# attention masking for padded token
# torch.ByteTensor([batch_size, 1, seq_len, seq_len)
mask = (x > 0).unsqueeze(1).repeat(1, x.size(1), 1).unsqueeze(1)
# embedding the indexed sequence to sequence of vectors
x = self.embedding(x, segment_info)
# running over multiple transformer blocks
for transformer in self.transformer_blocks:
x = transformer.forward(x, mask)
return x这么一看,这好像就是Transformer的编码器部分。不同的是,在forward函数这里计算了一下mask。看这个mask的定义,应该是大于0的地方为mask。我们在数据集的定义中找到如下代码:
def random_word(self, sentence):
tokens = sentence.split()
output_label = []
for i, token in enumerate(tokens):
prob = random.random()
if prob < 0.15:
prob /= 0.15
# 80% randomly change token to mask token
if prob < 0.8:
tokens[i] = self.vocab.mask_index
# 10% randomly change token to random token
elif prob < 0.9:
tokens[i] = random.randrange(len(self.vocab))
# 10% randomly change token to current token
else:
tokens[i] = self.vocab.stoi.get(token, self.vocab.unk_index)
output_label.append(self.vocab.stoi.get(token, self.vocab.unk_index))
else:
tokens[i] = self.vocab.stoi.get(token, self.vocab.unk_index)
output_label.append(0)
return tokens, output_label从上述代码中可见,作者设置了随机比例来将输入句子中的一部分词替换成特殊符号<mask>,也设置了一定的随机比例将一部分词随机替换成其他词汇。这些被替换的词汇所对应的位置被设定为大于0的整数,而未被替换的位置,设置为0。
这样一看,前面BERT的forward函数的第一行代码,即:
mask = (x > 0).unsqueeze(1).repeat(1, x.size(1), 1).unsqueeze(1)就非常容易理解了。更多的细节建议大家将上述链接代码下载后自行查看。
3 总结
写到这里,关于BERT的基本流程和网络结构都讲解完毕了。如果大家熟悉Transformer的话,应该会觉得BERT其实比较容易理解。当然,如果大家觉得看起来比较吃力的话,这里非常建议大家可以自学/温习一下Transformer后再来看一遍!
推荐阅读:
我的2022届互联网校招分享
我的2021总结
浅谈算法岗和开发岗的区别
互联网校招研发薪资汇总
2022届互联网求职现状,金9银10快变成铜9铁10!!
公众号:AI蜗牛车
保持谦逊、保持自律、保持进步
发送【蜗牛】获取一份《手把手AI项目》(AI蜗牛车著)
发送【1222】获取一份不错的leetcode刷题笔记
发送【AI四大名著】获取四本经典AI电子书