整体项目介绍:
https://blog.csdn.net/wenjieyatou/article/details/80190886
优惠券项目一介绍:https://blog.csdn.net/wenjieyatou/article/details/80191083
优惠券项目二介绍:
https://blog.csdn.net/wenjieyatou/article/details/80203860
下面是优惠券项目三介绍:
分支1.3
目的:通过程序代码和优化数据库来提高性能具体方案:
1:以前获取券组下所有的优惠券修改为获取100条(经测试统计得出发送50张券消耗时间是106s,每次获取优惠券大约耗时是2s多,整体性能提升近3倍)
/**
* 获取券组下优惠券
* @param vendorId
* @param actNo
* @param groupNo
* @param type
* @return
*/
private List<Coupon> getCoupons(Long vendorId,String actNo,String groupNo,int type) {
Coupon coupon = new Coupon();
coupon.setVendorId(vendorId);
coupon.setActNo(actNo);
coupon.setSubgroupCode(groupNo);
coupon.setState(type);
coupon.setPageIndex(0);
//限制获取数量为100。
coupon.setPageSize(100);
String key = String.format("%s_%s_%s", vendorId, actNo, groupNo);
List<Coupon> coupons = new ArrayList<>();
if (couponMap.get(key) != null) {
coupons = (List<Coupon>) couponMap.get(key);
}
if (couponMap.get(key) == null) {
coupons = couponDao.getCouponListByPage(coupon);
if (CollectionUtils.isNotEmpty(coupons)) {
couponMap.put(key, coupons);
}
}
return coupons;
}
2:优化sql,加入组合索引(统计得出发送50张优惠券消耗总时间是2.5s,每次获取优惠券大约耗时是0.015s,整体的性能提升了近42倍)
组合优化参考:https://blog.csdn.net/u013628152/article/details/51550923
再谈SQL优化:组合索引
对于任何DBMS,索引都是进行优化的最主要的因素。对于少量的数据,没有合适的索引影响不是很大,但是,当随着数据量的增加,性能会急剧下降。
如果对多列进行索引(组合索引),列的顺序非常重要,MySQL仅能对索引最左边的前缀进行有效的查找。例如:
假设存在组合索引(c1,c2),查询语句select * from t1 where c1=1 and c2=2能够使用该索引。查询语句select * from t1 where c1=1也能够使用该索引。但是,查询语句select * from t1 where c2=2不能够使用该索引,因为没有组合索引的引导列,即,要想使用c2列进行查找,必需出现c1等于某值。
举例说明:
创建两张表book(图书表)和bookclass(图书分类表)
select b.ISBN FROM book b where b.CATEGORY_ID = 1;
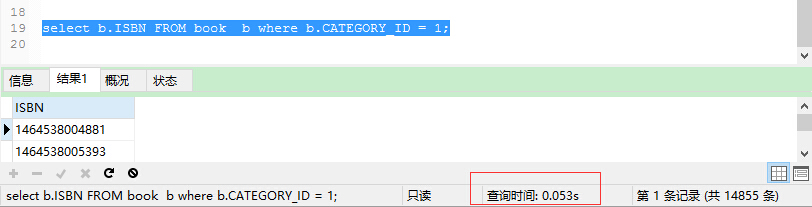
使用explain来分析一下该SQL:
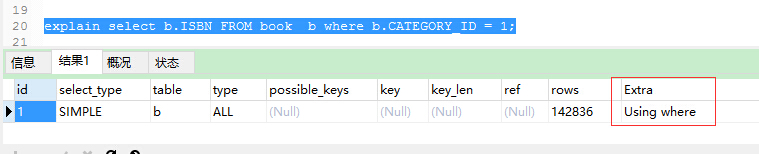
explain显示了mysql如何使用索引来处理select语句以及连接表。可以帮助选择更好的索引和写出更优化的查询语句。
ALL 对于每个来自于先前的表的行组合,进行完整的表扫描。如果表是第一个没标记const的表,这通常不好,并且通常在它情况下很差。通常可以增加更多的索引而不要使用ALL,使得行能基于前面的表中的常数值或列值被检索出。
创建组合索引:
create index index_isbn on book (CATEGORY_ID,ISBN) ;
再次执行SQL,发现时间缩短到0.009s
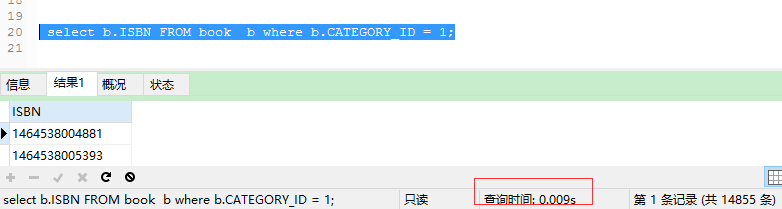
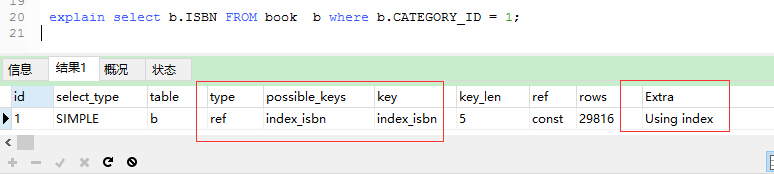
ref 对于每个来自于前面的表的行组合,所有有匹配索引值的行将从这张表中读取。如果联接只使用键的最左边的前缀,或如果键不是UNIQUE或PRIMARY KEY(换句话说,如果联接不能基于关键字选择单个行的话),则使用ref。如果使用的键仅仅匹配少量行,该联接类型是不错的。
3:加入本地缓存(如果一次性获取的优惠券先放入map中,那么下次如果还有就不需要从库中获取优惠券。统计发现:10件商品,每件商品发50张优惠券
不加本地缓存效率耗时是7.5s,加入本地缓存后耗时约5.5s,整体性能提升了2s)
这个做法主要是在类里面定义一个map,第一次访问数据库后将数据存在map中,后面再有请求时可以先在map中取,map中没有的话再访问数据库,之后将新访问的数据存在map中。考虑并发问题,可以使用concurrenthashmap。
这种添加本地缓存比较适用于单服务器部署,在集群情况下是不太好。另一种做法是使用redis构成分布式缓存。
private Map couponMap = new ConcurrentHashMap();
List<Coupon> coupons = new ArrayList<>();
if (couponMap.get(key) != null) {
coupons = (List<Coupon>) couponMap.get(key);
}
if (couponMap.get(key) == null) {
coupons = couponDao.getCouponListByPage(coupon);
if (CollectionUtils.isNotEmpty(coupons)) {
couponMap.put(key, coupons);
}
}
4:对于发券采用批量更新来替代for循环(由上面的约5.5s性能提升为大约4.8s)
意思就是执行一次数据库连接 sql的编译。避免了每次都重新请求数据库,每次重新编译sql。