一:2D目标检测——问题探讨
当前目标检测已经有许多经典框架,大致可以分为三大类:Dense method、Dense-to-Sparse method和Sparse method,在Sparse R-CNN提出前,其实没有任何一个模型是真正的Sparse method,下面我来进行简单利弊分析:
-
Dense method
到底什么是Dense,其实就是大量的prior candidates。对于yolo系列,设定了Dense个prior anchors。对于FCOS ,设定了Dense个prior reference points。这些one-stage模型以大量的先验candidates为基础,进行后面的offsets和cls_pred学习。优点很明显——快,但缺点同样很多,具体如下:一:大量hand-designed object candidates 对于yolo,需要事先设定anchor的个数、大小、长宽比,这些超参数的人为设定不仅麻烦,更使得网络对这些超参数敏感, 不利于网络的检测效果。 二:many-to-one label assignment 同样用yolo举例,在网络训练过程中,需要对大量的anchor进行label分配,不仅麻烦,而且使得网络 sensitive to heuristic assign rules,换句话说就是靠直观感受去分配样本标签, 比如依靠iou阈值设定, 似乎理所当然,但实际上无形中破坏了end-to-end的涵义。这些对网络都是不利的。 三:依赖post-processing 这种pipelines往往会预测出不少冗余、重叠、相似的检测框,所以需要进行NMS等后处理,大大影响效率和检测效果。 -
Dense-to-Sparse method
比较典型的网络就是Faster R-CNN等two-stage网络了,它们利用SS、RPN等方法从Dense candidates中选择出a sparse set of candidates,虽然提高了准确度,但是上诉的几个问题依然存在,并且训练策略麻烦、推理速度慢。 -
Sparse method
其实在Sparse R-CNN之前,传统DETR率先使用的Sparse思想,用a sparse set of queries,来访问global( Dense ) keys,也因此严格意义上,传统DETR更似Dense-to-Sparse method。后面Deformable DETR的提出,算是真正的Sparse method。那么Sparse method到底强在哪儿呢?如下:一:真正的end-to-end 只需要随即初始化N个candidates(DETR中是query,Sparse R-CNN是N对proposal box和proposal feature), 在训练中进行学习。而不再需要人为设定scale、ratio等超参数,意味着实现了真正“自由”的检测,这才是end-to-end 的精髓所在。不仅摆脱了头疼的hand-designed过程,更是大大提高了检测效果。 二:不再需要post-processing 因为candidates少而精,而且由于算法本身的精妙(后面会讲),预测结果不会存在冗余、相近的情况,自然不需要 NMS这种后处理操作,大大提高了检测效率。
二:Sparse细节探讨
在我看来,Sparse R-CNN的核心思路和DETR有异曲同工之妙,这是由Sparse思想决定的。那Sparse method的核心思想到底是什么呢?N set of candidates是如何学习更新的呢?
前方核能:
这里我就拿DETR进行讲解,首先query_embed其实就是coarse positions,等于N个query先在src上框出N个大致范围。接着通过tgt(起初是0,代表的是许多latent信息,在传统的DETR中代表的是每个query负责的内容、它们负责的内容和附近的一些feature的关系以及boxes的位置信息,很混乱)+ query_pos(在传统DETR中是query和query间的一个彼此位置信息,其实也可以理解为boxes的初始基准位置,是query_embed决定的,需要先给每个query一个大致的boxes位置,这样才方便后面学习到每个query负责的大致内容、基准boxes需要调节的模糊方向)查询feature map上的keys,来更新牛*的tgt。
传统的DETR在cross-attention时,没有考虑到q_content和q_pos应该分开查询,所以后面就有了conditional DETR的提出,将解耦后的q_content和q_pos拼接而不是直接相加,这样tgt就只包含content信息,而拼接的query_sine_embed并依据output微调后,就代表的boxes信息。两者解耦开始查询,大大提高了收敛速度和准确度。
在DAB-DETR后,就开始初始化reference_points(x, y, w, h),而不是初始化query_embed,更加光明正大的显式体现了DETR实质上就是基于初始化boxes进行的一系列操作。 每个query基于初始化的boxes,来生成query彼此的q_pos关系,并生成query_sine_embed(就是boxes的信息),后面将三者融合后,生成q来查询key,这样得到包含大量内容信息的output,利用它再更新reference_points,再重新生成全新的query_pos和query_sine_embed。可见,一切始于boxes!!!
三:Sparse R-CNN讲解
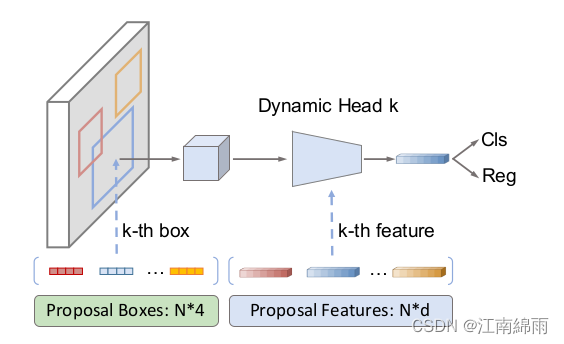
Sparse R-CNN中的核心就是先初始化了N组4维proposal boxes和256维proposal features。其实它们分别对应了DETR中的reference_points和tgt即q_content。
两者都是随即初始化的,源码中对proposal boxes的初始化是正好覆盖全部的src,当然论文中提到就算换成其他初始化方法,也有一定的鲁棒性,性能没什么影响。
重点是Dynamic Head,传入该模块前先对proposal features进行了self.attention。对N组proposal boxes分配到对应的feature level上,然后ROIAligen,得到7✖7的256维向量,也就是(B,100, 49,256)。然后利用(B, 100, 256)的proposal feature生成两个params矩阵(B, 100, 256, 64)和(B, 100, 64, 256),对proposal features依次乘上,生成全新的(B, 100, 49, 256),然后flatten(1)并输入进Linear层转化为256维度,也就是(B, 100, 256)。
其实有种cross-attention的感觉,或者更像是SAM-DETR或者Deformable DETR中的采样思想。但是不同的是,这里没有简单的将boxes内采样特征随便分配个weights就融合,而是经过了上面的两个filter,这样做可以对特征进行筛选。比较类似于AdaMixer中的ACM和ADM的融合特征方式,当然,还是有不太相同的,只是着力点一样,都是对已采样特征的更好的融合策略。
有了全新的(B, 100, 256)后,做一些residual、FFN等常规操作后,生成全新的proposal features,里面融合了大量latent信息。
全新的proposal features再经过cls层和bbox层,生成bboxes_deltas和class_logits,将bboxes_deltas加到原boxes上,生成全新的boxes输入进下一轮,并将它们存入intermediate列表中。
最后就是匈牙利匹配,对匹配上的query的预测结果进行set_loss计算,反向传递完成参数更新。
总体而言,和DETR的思路大同小异,只不过是CNN方式的实现。但是有个不同点,就是作者测试,Dynamic Head用query的方式,需要加入query_pos信息,否则效果很差。但是CNN的方式不需要以来pos信息 ,效果也很好。
时间有限,留个-----------------------------------------------------源码坑-------------------------------------------------------------------,需要源码讲解的小伙伴,可以评论区留言~
至此我对Sparse R-CNN中重点流程与细节进行了深度讲解,同时对当下主流2D检测模型进行了利弊分析。希望对大家有所帮助,有不懂的地方或者建议,欢迎大家在下方留言评论。
我是努力在CV泥潭中摸爬滚打的江南咸鱼,我们一起努力,不留遗憾!