前言
如果你对这篇文章感兴趣,可以点击「【访客必读 - 指引页】一文囊括主页内所有高质量博客」,查看完整博客分类与对应链接。
本文为「对比学习论文综述」的笔记,其中将对比学习分为了以下四个发展阶段:
- 百花齐放
- CV 双雄
- 不用负样本
- Transformer
其中涉及到的一些方法,具体关系如下:
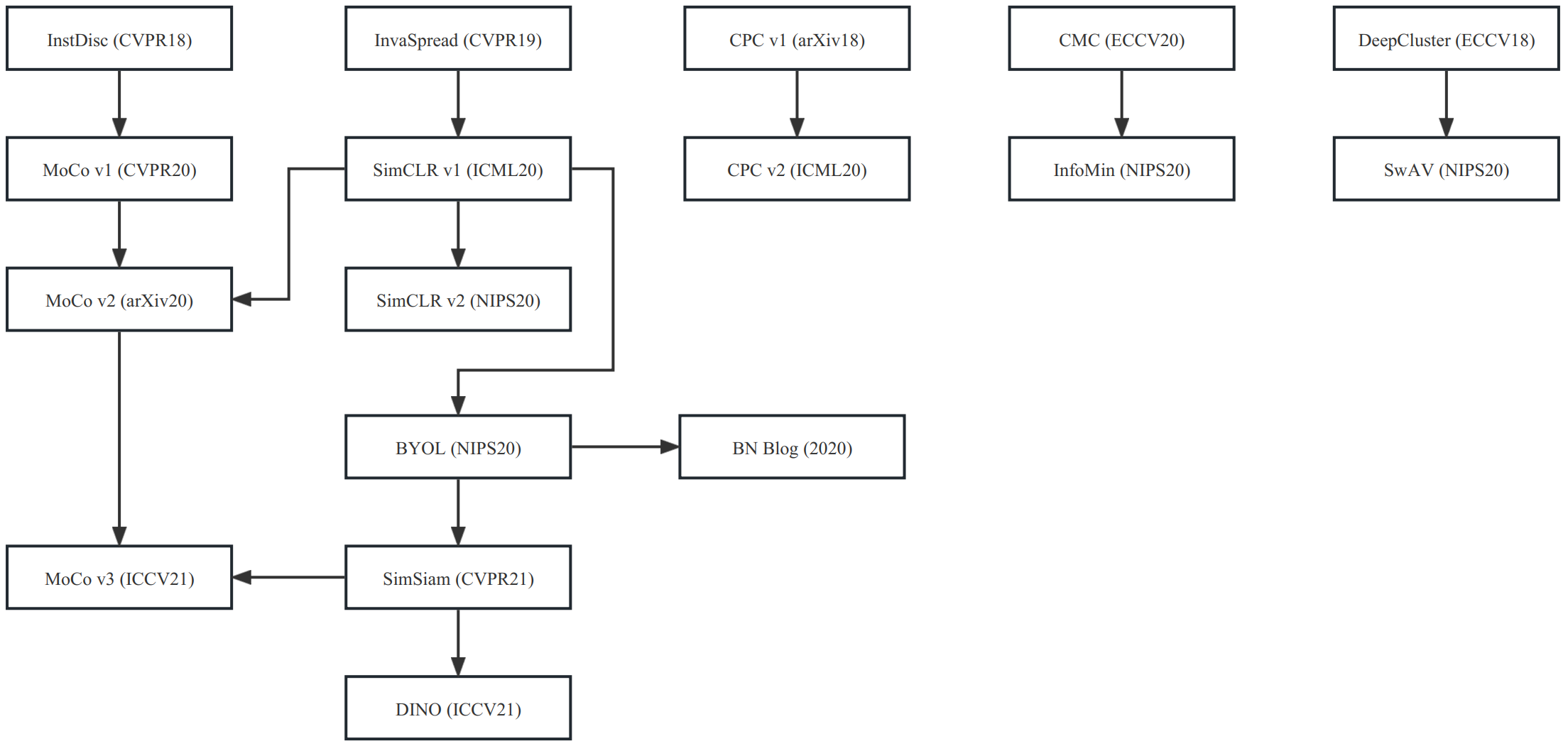
百花齐放
InstDisc (cvpr18)
- 把每一个个体当作一个类别,学一种特征将每一张图片都区分开,进而引入个体判别这一代理任务
- 正样本即图片本身(可能数据增强),负样本即其它所有图片
- 大量负样本都存在 Memory Bank(ImageNet 中为 128w),因此特征数不能过高(128 维)
- 每次一个正样本,对应采样的 4096 个负样本,使用 NCE loss 计算损失;随后将这个 mini-batch 中样本的新表示,拿去更新 Memory Bank 中的结果
InvaSpread (cvpr19)
- 从同一个 minibatch 中抽取正负样本,属于端到端的学习
- 使用同一个编码器,且不需要存储大量的负样本
CPC (arxiv18)
- 一个编码器 + 自回归模型
- 用预测的代理任务来做对比学习,提出 InfoNCE Loss
CMC (eccv20)
- 同一张图片的多个模态为正样本,其余为负样本
- 不同模态使用不同的编码器
- 证明了对比学习的灵活性
CV 双雄
这段时期主要是「MoCo 系列模型」与「SimCLR 系列模型」在轮番较量。
MoCo (cvpr20)
- 队列(取代 Memory Bank)与动量编码器(动量地更新编码器,而不是更新特征)
- 使用 InfoNCE 作为目标函数,并第一次使用无监督方法比有监督表现地更好
- Insight
- 负样本最好足够多,即字典足够多
- 负样本来自的编码器,尽量保持一致,即字典中的特征应保持一致
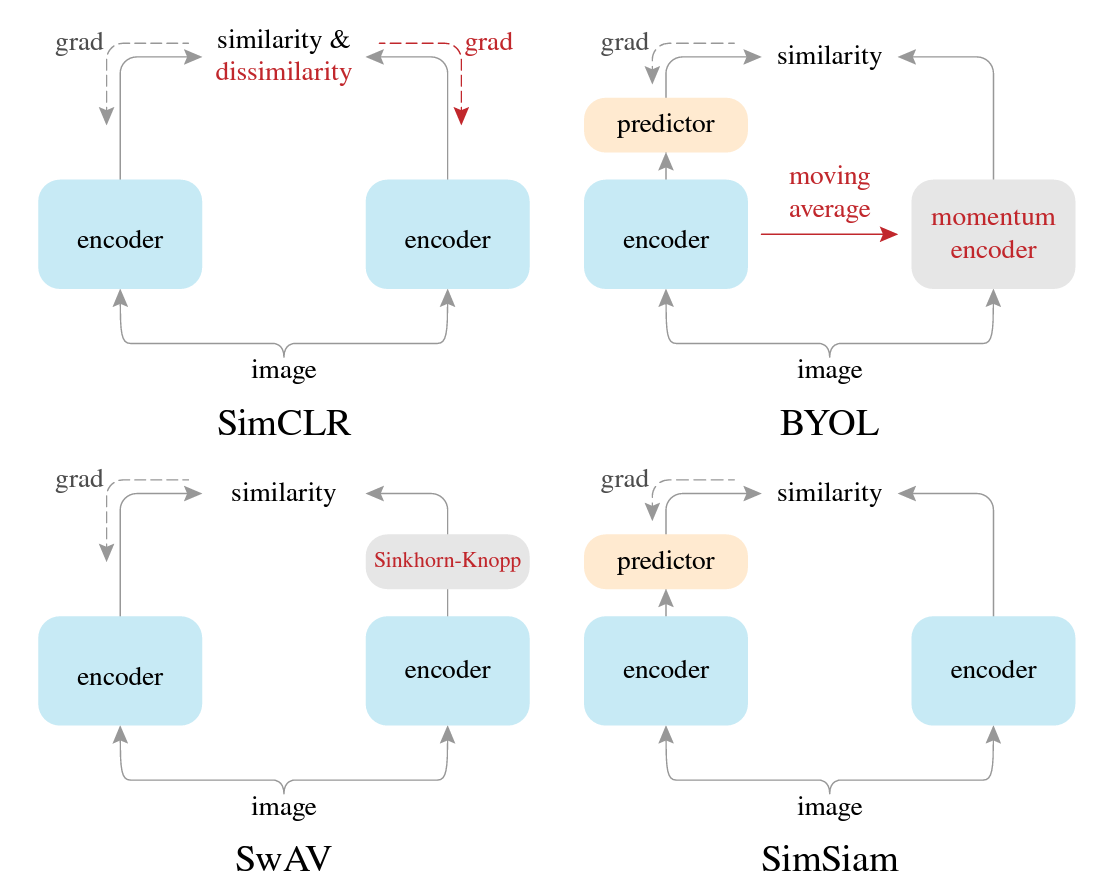
SimCLR (icml20)
- 正负样本来自同一个 minibatch,每个样本会进行数据增广
- 得到表示后,会再过一个 g (MLP + ReLU) 降维得到 z,随后在 z 上训练 h;但在下游任务上,会丢弃 g,只使用 h
- 与 InvaSpread 区别
- 更多的数据增广方式
- 更大的 batch size
- 增加了 g 模块
MoCo v2 (arxiv20)
- 将 SimCLR 中的 g 和数据增广,借鉴到了 MoCo 中
- MLP、aug+、cosine learning rate schedule、more epochs
SimCLR v2 (nips20)
- 用更大的模型,无监督对比学习效果更好
- 将之前一层的 MLP (fc+relu) 换成两层的 MLP,即加深了 projection head
- 使用动量编码器
SwAV (nips20)
- 拿到负样本聚类得到的矩阵,将其作为映射矩阵 C,随后代理任务为,两个正样本 z1、z2,经过映射矩阵 C 得到的 Q1、Q2,应尽可能相似
- trick:数据增广时,采用多尺度去裁剪图片 (multi crop)
不用负样本
BYOL (nips20)
- Model collapse: 即一旦只有正样本,模型会学到 trival solution,即所有输入都对应相同输出
- 编码器 1 为希望学到的编码器,编码器 2 为动量编码器,两个正样本经过编码器 1、2 分别得到 z1、z2,随后 z1 再过一层 MLP 得到 q1,此时用 q1 来预测 z2 进而来更新网络(使用 MSE Loss)。最后在下游任务上,使用编码器 1 进行特征表示
- BYOL 为什么不会坍塌:如果去除 BYOL 中 MLP 里的 BN,学习就会坍塌,但加上就不会
- 一种解释角度:BN 即使用 minibatch 的均值和方差,因此 BN 会导致数据泄露,即 BYOL 实际上是和 “平均图片” 去比,可以认为是一种隐式的负样本
- BYOL 后续进一步回应(大量消融实验):BN 能够使模型训练更加稳定,就算不用 BN,换成 Group Normalization 或者比较好的初始化,BYOL 依然可以学得比较好
SimSiam (cvpr21)
- 特点:不需要负样本、大 batch size、动量编码器
- 方法:将 BYOL 中的动量编码器变成了一个可以更新的编码器
- 解释:stop gradient 使得模型的更新交替进行,类似 EM 的思想
Transformer
MoCo v3 (iccv21)
- 在 MoCo v2 基础上,引入了 SimSiam 中 predictor 以及两边一起更新的 EM 思想,并将 backbone 从 ResNet 换成了 Vision Transformer
- 出现的问题:大 batch size 时,训练波动很大,导致最终结果也不太好
- 解决方式:在训练时,冻住 patch projection layer,即使用 random patch projection layer
DINO (iccv21)
- 整体与 MoCo v3 非常像,主要不同在于算 loss 时,用了一下 centering 的 trick