Class Attention Map Distillation for Efficient Semantic Segmentation
最近因为想用CAM来做一个弱监督的分割,因此看了这篇论文
摘要
- 采用显著图(saliency map)方法从卷积神经网络中提取有用的蒸馏知识
- 通过制作特定类的注意图,然后强迫学生网络模拟产生这些注意
- 一种利用特定类注意图进行注意力转移的新方法
- 介绍了该方法能够成功地从两个网络的中间层提取知识的原因
引言
Saliency Maps
- 可解释性在机器学习模型中被认为是重要的,因为人类需要并想知道算法是如何做出决策的。
- 显著性图是一种了解cnn工作原理的方法。它们经常处理来自隐藏层的一个或一组神经元,在输入空间中创建一个注意力地图。
- 激活最大化是最早通过优化输入空间来最大化隐藏神经元的可视化工作。
- 引入Deconvnet层来近似网络层的逆。
- 对输入空间进行优化,尽可能地删除输入图像中的信息,同时保留模型的决策。就可解释性而言,这种方法似乎是最清晰的,但它比其他方法慢。
- 提出获取神经元相对于输入层的梯度,并用ReLu激活函数在网络中可视化它们的作品。这将导致高分辨率的显著性图,但它们不是分类的。
- 引入了类激活映射(CAMs),它工作在分类网络上,执行全局平均池化,然后在最后的卷积层之后再执行线性层。这样,每个输出类的线性层的权重可以用作最后一个卷积特征映射的通道求和的权重。结果的分辨率较低,但具有阶级歧视性
- 获得所需层的梯度,然后将其作为权重,在特征图上进行加权和。这导致了CAM的一个有价值的泛化,它可以生成特定于类的注意图,而不管网络的体系结构如何。
Knowledge Distillation
学生网络使用教师的预测作为软标签(与零和一个硬标签的基本真理相比)。软标签包含关于问题结构和类别之间关系的有用信息,并为训练学生提供有用的信息。教师和学生框架被广泛用于帮助培养紧密型学生。在许多其他场景中,它也很有用。例如,这里列出了一些最著名的相关工作:
- 用一个浅层老师模型来训练一个深但薄的学生模型(需要好好理解)
- 使用教师标记未标记的数据,并使用额外的标记数据来训练学生
- 使用蒸馏来教一个已经训练好的网络对额外的类进行分类,而不会损失旧类的性能
- 训练一群学生,在训练阶段互相传递信息
- 以这样一种方式训练一系列相同的网络,使每个网络从之前训练的网络中提取,从而提高性能
- 结合多个不同标签领域的专家分类器,得到一个与每个领域的所有专家一样好的模型
大多数讨论的方法都是为图像分类而设计的,但也将其方法应用于物体检测。
有用老师的预测而不是基本事实来训练学生。它带来了更好的结果,因为老师的输出是一个更容易学习的分布。
使用了在ImageNet上冻结和预训练网络的特征图(真实数据)和使用合成数据进行训练的学生网络之间的蒸馏。
关于损失:
- 引入了学生和老师之间的一致性损失,使他们的分割边界相似。将学生输出概率与教师输出概率之差的L2范数作为另一种损失。
- 成对损失定义为师生网络亲和矩阵元素之间的均方距离(亲和矩阵包含每对编码像素的特征之间的内积)。
- 第二种损失被称为整体蒸馏,它使用判别器卷积网络,使用对抗性学习来制作学生的特征图,与老师的相似。
- 使用亲和损失几乎与成对损失相同,除了他们在计算亲和矩阵之前为教师网络的最后一个卷积层训练了一个自动编码器。还使用学生的最后一个卷积特征和老师的编码特征之间的直接L2范数距离作为额外损失。
本文方法
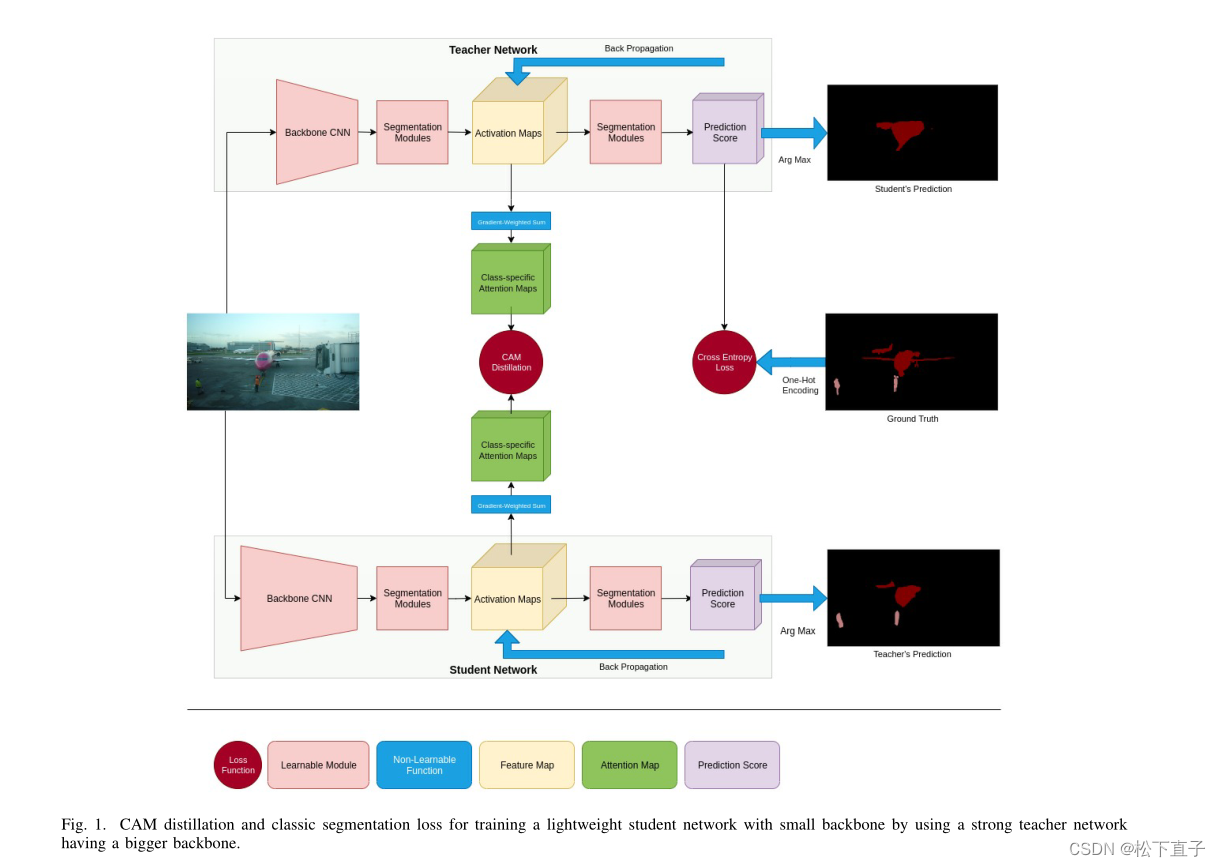
- 每个特征映射中分类特定的注意力映射
- 类注意力映射(CAM)蒸馏: 从每个特征映射中创建几个注意力映射,每个注意力映射对应于模型可预测的特定类
- CAM和GAM的区别:CAM来自多个特征图,GAM每个特征映射都映射到一个注意矩阵
- A为中间层特征图,i代表层数,k代表深度
GAM
GAM注意力矩阵如下:
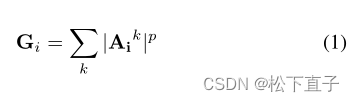
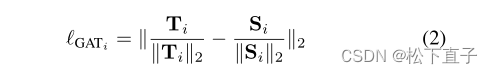
T代表教师网络生成的特征图,S代表学生网络生成的特征图
总共的损失:

CAM
L代表没有标准化的分割输出
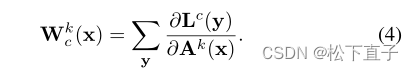
CAM注意力矩阵定义:
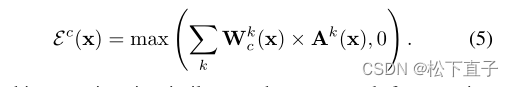
CAM的损失函数
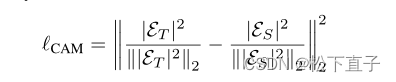
总共的损失:

计算凸轮损失函数需要选择部分反向传播特性映射为每个类的老师和学生网络,这就增加了训练时间相对于GAM蒸馏方法。
另一方面,CAM矩阵中的信息似乎比GAM矩阵更独立于体系结构,因为它们是使用一种旨在为人类创建显著性图的方法创建的。
CAMs最好从网络中间层的特征映射中创建。原因在于,尽管图像分类网络,没有池或向卷积操作的最后一层现代语义分割网络,这导致接受域是有限的。
总结讨论
- 生成显著图的主要方法之一被用来提取具有不同架构的两个网络之间的知识
- 可以成功地提高学生网络的性能。更深层次的网络包含更抽象的信息。
- 在一个极端的例子中,规范化预测层被训练为拥有关于问题结构的纯信息,并尽可能地忘记对象实例的细节。即使是两个相同的网络架构也可能在训练阶段找到两个不同的局部最优值,并且随着表示层深度的增加,每个输入具有远表示的机会也会减少。这一事实吸引了研究人员发明方法,可以从两个网络的更深和接近最后的特征图中提取信息。所提出的方法解决了这个问题,采用中间特征映射,并将其转换为有意义的表示,洗掉限制性细节为了提炼和掌握有用的信息,可以指导学生在优化空间。
- 很多方法都试图将网络的表示空间映射回输入空间或人类能够理解的空间。这个领域可能有很好的知识蒸馏潜力。