摘要
由于复杂的注意力机制和模型设计,大多数现有的ViTs在现实的工业部署场景中不能像CNNs那样高效地执行,例如TensorRT和CoreML。这带来了一个明显的挑战:视觉神经网络能否设计为与CNN一样快的推理和与ViT一样强大的性能?最近很多工作试图设计CNN-Transformer混合架构来解决这个问题,但这些工作的整体性能远不能令人满意。为了结束这些,本文作者提出了在现实工业场景中有效部署的Next Generation Vision Transformer,即Next-ViT,从延迟/准确性权衡的角度来看,它在CNN和ViT中均占主导地位。在这项工作中,分别开发了Next Convolution Block(NCB)和Next Transformer Block(NTB),以通过部署友好的机制捕获局部和全局信息。然后,Next Hybrid Strategy(NHS) 旨在以高效的混合范式堆叠NCB和NTB,从而提高各种下游任务的性能。
大量实验表明,在跨各种视觉任务的延迟/准确性权衡方面,Next-ViT 显著优于现有的CNN、ViT和CNN-Transformer混合架构。在TensorRT上,Next-ViT在COCO检测上超过ResNet 5.4 mAP(从 40.4 到 45.8),在ADE20K分割上超过 8.2% mIoU(从 38.8% 到 47.0%),其推理延迟相差无几。同时,在与CSWin相当的性能,同时推理速度提高了 3.6 倍。在CoreML上,Next-ViT 在COCO检测上超过EfficientFormer 4.6 mAP(从 42.6 到 47.2),在ADE20K分割上超过 3.5% mIoU(从 45.2% 到 48.7%)。
简介
近年来 ViTs 在业界和学术界受到了越来越多的关注,并在图像分类、目标检测、语义分割等各种计算机视觉任务中取得了很大的成功。然而,从现实世界部署的角度来看,cnn仍然主导着视觉任务,因为vit通常比经典的cnn要慢得多,例如ResNets。包括多头自注意力(MHSA)机制其复杂度与Token长度呈二次关系、不可融合的LayerNorm和GELU层、复杂模型设计导致频繁的内存访问和复制等因素限制了ViTs模型的推理速度。
许多工作都在努力将 vit 从高延迟的困境中解放出来。例如,Swin 和 PVT 试图设计更有效的空间注意力机制,以缓解 MHSA 二次增加的计算复杂度。其他的工作也在考虑结合有效的卷积块和强大的Transformer Block来设计CNN-Transformer混合架构,以获得在精度和延迟之间更好的权衡。巧合的是,几乎所有现有的混合架构都在浅层阶段采用卷积块,在最后几个阶段只采用堆栈Transformer Block。
然而,作者观察到,这种混合策略可能会地导致下游任务(例如分割和检测)的性能饱和。此外,作者还发现,在现有的工作中,卷积块和Transformer Block都不能同时具有效率和性能的特征。虽然与 vit 相比,精度-延迟的权衡得到了改善,但现有的混合架构的整体性能仍远远不够令人满意。
为了解决上述问题,这项工作开发了3个重要组件来设计高效的视觉 Transformer 网络。
- 首先,介绍了 Next Convolution Block(NCB),NCB擅长使用新颖的部署友好的多头卷积注意力 (MHCA) 来捕获视觉数据中的短期依赖信息。
- 其次,构建了 Next Transformer Block(NTB),NTB 不仅是捕获长期依赖信息的专家,而且还可以作为轻量级的高低频信号混合器来增强建模能力。
- 最后,设计了 Next Hybrid Strategy (NHS),在每个阶段以一种新颖的混合范式堆叠 NCB 和 NTB,大大降低了 Transformer 块的比例,并在各种下游任务中最大程度的保留了 Vision Transformer 网络的高精度。
基于上述方法提出了用于现实工业部署场景的next generation vision Transformer(简称为Next-ViT)。在本文中,为了提供一个公平的比较,作者提供了一个观点,将特定硬件上的延迟视为直接的效率反馈。TensorRT 和 CoreML 分别代表了服务器端和移动设备的通用和易于部署的解决方案,有助于提供令人信服的面向硬件的性能指导。通过这种直接和准确的指导,重新绘制了图1中几个现有竞争模型的准确性和延迟权衡图。
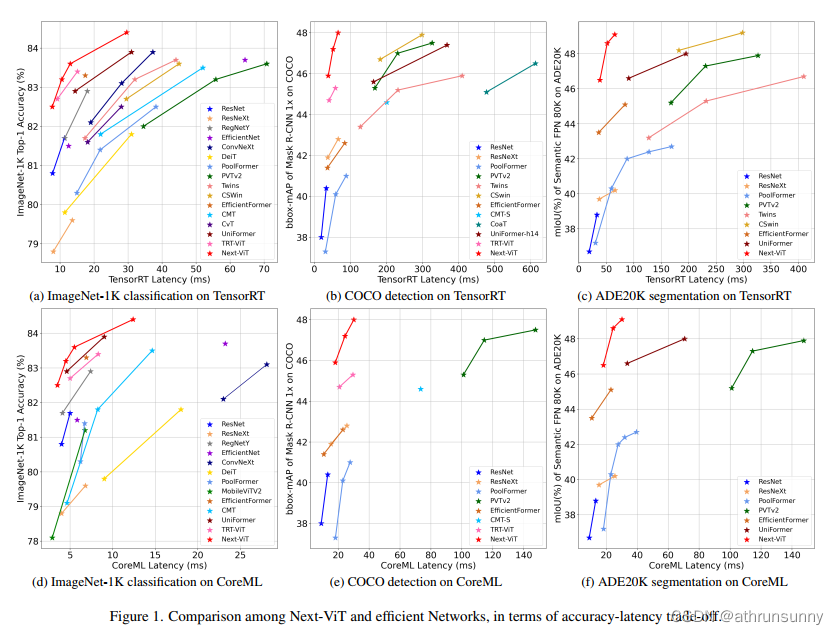
如图1(a)(d)所示,Next-ViT在ImageNet-1K分类任务上实现了最佳的延迟/准确性权衡。更重要的是,Next-ViT在下游任务上显示出了更显著的延迟/准确性权衡优势。
跳过相关工作。。。。。。
Method
3.1 Next-ViT
如图2所示。按照惯例,Next-ViT遵循分层的金字塔体系结构,在每个阶段都有一个patch embedding层和一系列的卷积或Transformer blocks。空间分辨率将逐步降低32×,而通道尺寸将在不同的阶段中扩大。
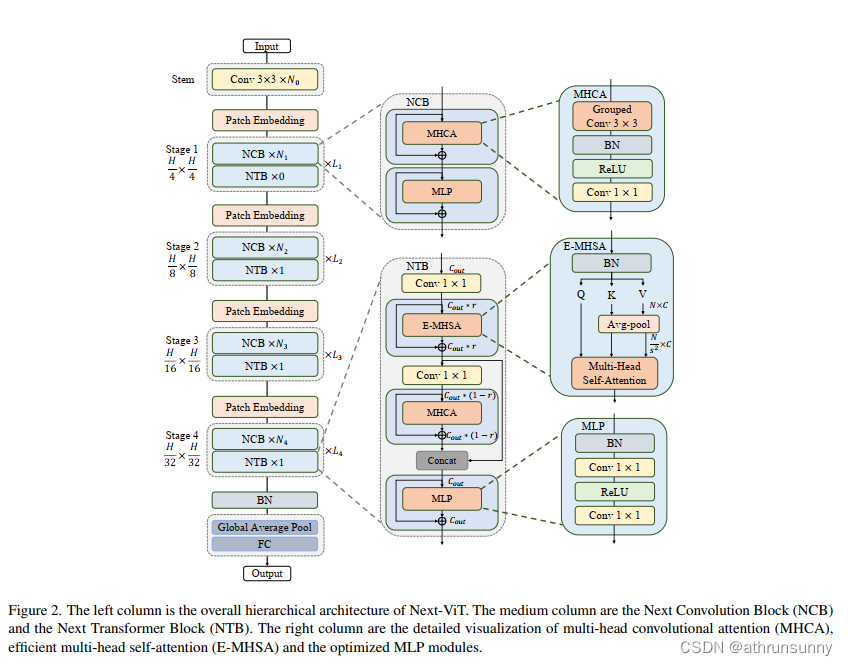
3.2 Next Convolution Block(NCB)
为了展示所提出的 NCB 的优越性,首先重新审视卷积和 Transformer blocks 的一些经典结构设计,如图 3 所示。ResNet 提出的 BottleNeck 块因其固有的归纳偏差和部署而在视觉神经网络中长期占据主导地位。大多数硬件平台的友好特性。
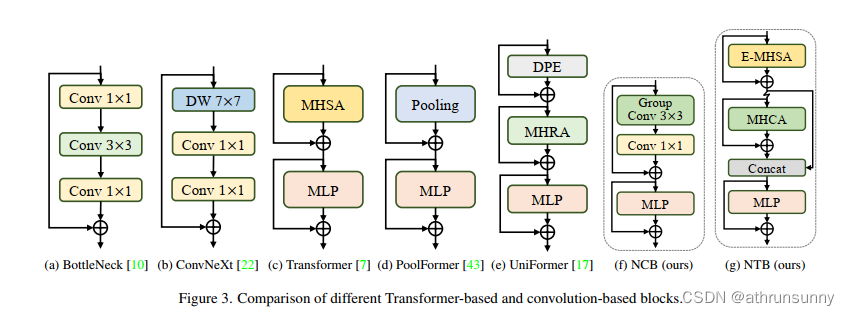
不幸的是,与 Transformer 模块相比,BottleNeck 模块的有效性并不能令人满意。ConvNeXt 模块通过模仿 Transformer 模块的设计使 BottleNeck 模块现代化。虽然 ConvNeXt 块部分提高了网络性能,但它在 TensorRT/CoreML 上的推理速度受到低效组件的严重限制,例如 7×7深度卷积、LayerNorm 和 GELU。Transformer blocks在各种视觉任务中取得了优异的成绩,其内在优势是由 MetaFormer【1】 的范式和基于注意力的token mixer模块共同赋予的。然而,Transformer blocks的推理速度比 TensorRT 和 CoreML 上的 BottleNeck 块要慢得多,因为其注意力机制复杂,这在大多数现实工业场景中是难以承受的。
为了克服上述Block的失败,作者引入了 Next Convolution Block (NCB),它在保持 BottleNeck 块的部署优势的同时获得了作为 Transformer 块的突出性能。如图 3(f) 所示,NCB 遵循 MetaFormer 的一般架构,经验证对 Transformer Block 至关重要。与此同时,一个高效的基于注意力的token mixer【1】同样重要。这里作者设计了一种新颖的多头卷积注意力(MHCA)作为具有部署友好卷积操作的高效token mixer。最后,在 MetaFormer 的范式中使用 MHCA 和 MLP 层构建 NCB。提出的 NCB 可以表述如下:

3.2.1 Multi-Head Convolutional Attention(MHCA)
为了将现有的基于注意力的token mixer从高延迟困境中解放出来,作者设计了一种新的具有高效卷积操作的注意力机制,即卷积注意力(CA),以实现快速推理速度。同时,受 MHSA 中有效多头设计的启发,这里也采用多头范式构建卷积注意力机制,该范式联合关注来自不同位置的不同表示子空间的信息,以实现有效的局部表示学习。所提出的多头卷积注意力(MHCA)的定义可概括如下:

在这里,MHCA从h个并行表示子空间中捕获信息。为了促进多个头部之间的信息交互,还为MHCA配备了一个投影层(WP)。z=[z1,z2,…,zh]表示将输入特征z在通道维度上划分为多头形式。CA是一种单头卷积注意力,可以定义为:
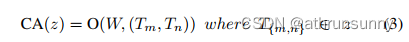
其中 Tm 和 Tn 是输入特征 z 中的相邻 Token。 0 是具有可训练参数 W 和输入 Token T{m,n} 的 内积运算。CA 能够通过迭代优化可训练参数 W来学习局部感受野中不同 Token 之间的亲和 力。
具体而言,MHCA 的实现是通过组卷积(多头卷积)和逐点卷积进行的,如图3(f)所示。在所有 MHCA 中将 head dim 统一设置为 32,以便在 TensorRT 上使用各种优化进行快速推理。此外,在 NCB 中采用了高效的 BatchNorm (BN) 和 ReLU 激活函数,而不是传统 Transformer Block 中的 LayerNorm (LN) 和 GELU,进一步加快了推理速度。消融研究中的实验结果表明,与现有块相比,NCB 具有优越性,例如 BottleNeck 块、ConvNext 块、LSA 块等。
3.3 Next Transformer Block (NTB)
虽然通过NCB已经有效地学习了局部表示,但全局信息的捕获迫切需要解决。Transformer Block具有较强的捕获低频信号的能力,从而提供全局信息(例如全局形状和结构)。然而,相关研究观察到,Transformer Block可能会在一定程度上恶化高频信息,如局部纹理信息。不同频率段的信号在人类视觉系统中是不可缺少的,并将以某种特定的方式融合,提取更基本和明显的特征。
基于这些观察结果,作者开发了Next Transformer Block(NTB)来捕获轻量级机制中的多频信号。此外,NTB 作为一种有效的多频信号混频器,进一步提高了整体建模能力。如图2所示,NTB首先采用高效的多头自注意力(E-MHSA)捕获低频信号,可以描述为:
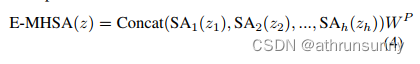
其中,表示将输入特征z在通道维数上划分为多头形式。SA是一种空间缩减自注意力算子,其灵感来自于线性SRA,其表现为:

其中,注意力表示一个标准的注意力计算方法。是一种具有Stride的Avg-pool操作,用于在注意力操作前对空间维度进行降采样,以降低计算成本。具体来说,作者观察到E-MHSA模块的时间消耗也很大程度地受到其通道数量的影响。因此,NTB在E-MHSA模块之前使用点卷积进行通道降维,以进一步加速推理。引入了一个收缩比r来减少通道。作者还在E-MHSA模块中使用BN来实现非常高效的部署。
此外,NTB还配备了一个MHCA模块,与E-MHSA模块合作,以捕获多频信号。之后,来自E-MHSA和MHCA的输出特征被连接起来,以混合高低频信息。最后,最后借用MLP层来提取更基本和明显的特征。简单地说,NTB的实现可以表述如下:

此外, NTB 统一采用 BN 和 ReLU 作为有效范数和激活层, 而不是 LN 和 GELU。 与传统的 Transformer 模块相比, NTB 能够在轻量级机制中捕获和混合多频信息, 极大地提 升模型性能。
3.4 Next Hybrid Strategy (NHS)
最近的一些工作已经付出了巨大的努力,以结合CNN和 Transformer 的有效部署。如图4(b)(c)所示,几乎所有它们在浅阶段都单调地采用卷积块,在最后一两个阶段只堆栈Transformer Block,在分类任务中得到了有效的效果。
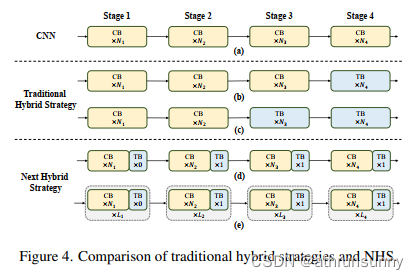
不幸的是,作者观察到,这些传统的混合策略在下游任务(如分割和检测)上可以轻松地达到性能饱和。原因是,分类任务只使用最后一阶段的输出来进行预测,而下游任务(如分割和检测)通常依赖于每个阶段的特征来获得更好的结果。然而,传统的混合策略只是在最后几个阶段堆叠Transformer Block。因此,浅层阶段无法捕获全局信息,例如物体的全局形状和结构,这对分割和检测任务至关重要。
为了克服现有混合策略的失败,作者提出了一种新的混合策略 (NHS),它创造性地将卷积块 (NCB) 和Transformer Block (NTB) 与 (N+1)* L 混合范式堆叠在一起。NHS在控制 Transformer Block的比例的情况下,显著提升下游任务中的模型性能,以实现高效部署。
首先,为了赋予浅层捕获全局信息的能力,作者提出了一种新颖的(NCB×N+NTB×1)模式混合策略,在每个阶段依次堆叠N个NCB和一个NTB,如图所示4(d)。具体来说, Transformer Block (NTB) 放置在每个阶段的末尾,这使模型能够学习浅层中的全局表示。作者进行了一系列实验来验证所提出的混合策略的优越性。不同混合策略的性能如表1所示。C表示在一个阶段均匀堆叠卷积块(NCB),T表示与 Transformer Block(NTB)一致地构建一个阶段。
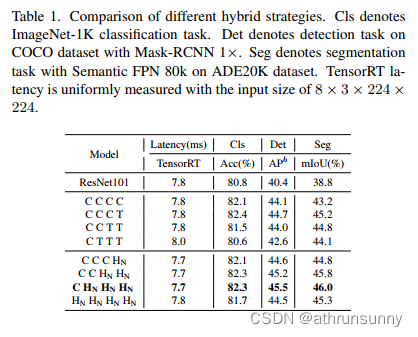
特别地, HN 表示在相应阶段以 (NCB×N+NTB×1) 模式堆叠 NCB 和 NTB。表 1 中的所有型号 都配备了4个阶段。例如, CCCC 表示在所有 4 个阶段中始终使用卷积块。为了公平比较, 在相 似的 TensorRT 延迟下构建所有模型。第 4 节介绍了更多实现细节。如表 1 所示, 与下游任务中的现有方法相比, 所提出的混合策略显着提高了模型性能。 CHNHNHN 达到最佳综合性能。例如, CHNHNHN 在检测中超过 CCCT0.8mAP, 在分割中超过 0.9%mIoU 。此外, HNHNHNHN 的结果表明, 将 Transformer Block 放置在第1阶段会恶化模型的延迟-准确性权衡。
通过增加第3阶段作为 ResNet 的块数进一步验证了CHNHNHN在大型模型上的一般有效性。表2前3行的实验结果表明,大模型的性能难以提升并逐渐达到饱和。这种现象表明,通过扩大 (NCB × N + NTB × 1) 模式的 N 来扩大模型大小,即简单地添加更多的卷积块并不是最佳选择。这也意味着(NCB × N + NTB × 1)模式中的 N 值可能会严重影响模型性能。

因此,作者通过广泛的实验探索 N 的值对模型性能的影响。如表 2(中)所示,在第3阶段构建了具有不同 N 配置的模型。为了建立具有相似延迟的模型以进行公平比较,在 N 的值较小时堆叠 L 组 (NCB × N + NTB × 1) 模式。令人惊讶的是,作者发现 (NCB × N + NTB × 1) × L 模式中的堆栈 NCB 和 NTB 与 (NCB × N + NTB × 1) 模式相比获得了更好的模型性能。
它表示以适当的方式(NCB × N + NTB × 1)重复组合低频信号提取器和高频信号提取器会带来更高质量的表示学习。如表 2 所示,第3阶段 N = 4 的模型实现了性能和延迟之间的最佳折衷。通过在第3阶段扩大 (NCB × 4 + NTB × 1) × L 模式的 L 来进一步构建更大的模型。
如表2(下)所示,Base(L = 4)和Large(L = 6)模型的性能相对于小模型有显著提升,验证了所提出的(NCB × N + NTB × 1)的一般有效性 × L 模式。使用 N = 4 作为本文其余部分的基本配置。
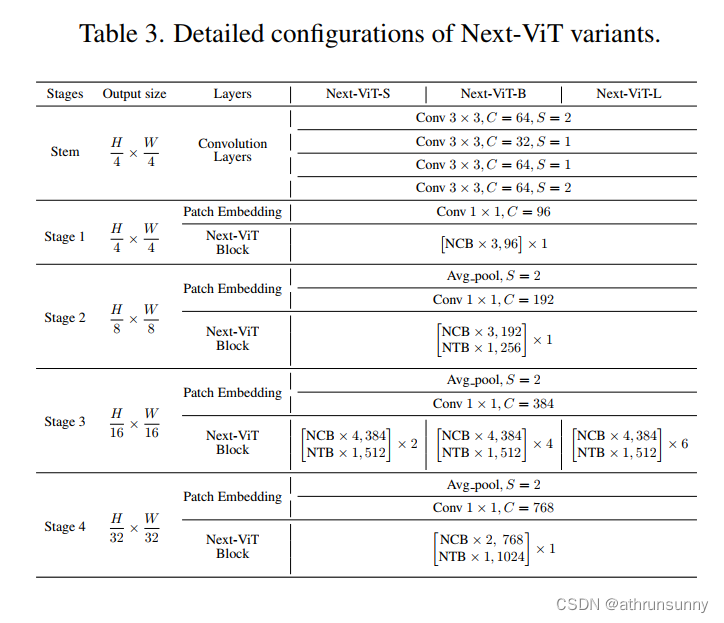
3.5 Next-ViT Architectures
为了与其他 SOTA 网络进行公平比较,我们提出了三个典型的变体,即 Next-ViT-S/B/L。架构规范如表 3 所示,其中 C 表示阶段的输出通道,S 表示卷积或 Avg 池中的步幅。此外,NTB中E-MHSA和MHCA的信道比例r设置为0.75,E-MHSA中不同阶段的空间缩减率s为[8,4,2,1]。每个 MLP 层的扩展比设置为 2,E-MHSA 和 MHCA 中的 head dim 设置为 32。对于归一化和激活函数,NCB 和 NTB 块都使用 BatchNorm 和 ReLU。
【1】MetaFormer范式和token mixer
通过下图即可很好的理解这两个概念
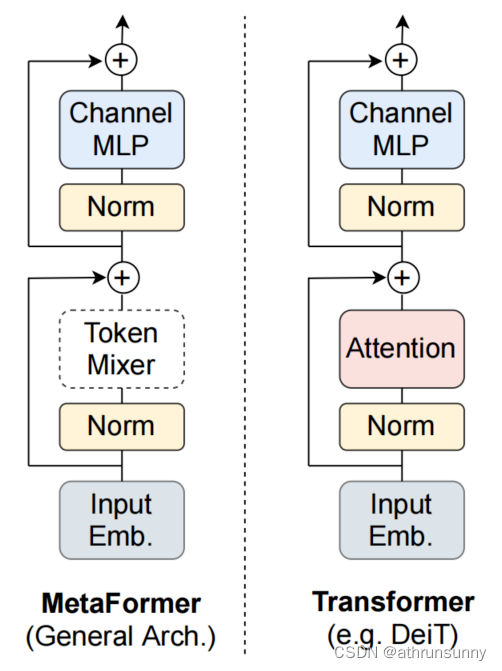
通过不指定token mixer,将MetaFormer作为从Transformer中抽象出来的通用架构。当使用注意力/空间MLP作为token mixer时,MetaFormer被实例化为Transformer/MLP-like的模型。token mixer就是在token之间混合信息的注意力模块。