基于Transformer的预训练模型汇总
1. ERNIE: Enhanced Language Representation with Informative Entities(THU)
特点:学习到了语料库之间得到语义联系,融合知识图谱到BERT中,本文解决了两个问题,structured knowledge encoding 和 Heterogeneous Information Fusion(如何融合语言的预训练向量空间和知识表征的向量空间)
因此,本文提出了同时在大规模语料库和知识图谱上预训练语言模型
- 信息抽取+编码知识信息:识别文本中的实体,并将实体与KG中的实体对齐(用knowledge embedding方法),得到的entity embedding作为ERNIE的输入,这样ERNIE将知识模块的实体表征正和岛予以模块的隐藏层中。
- 语言模型训练,使用了MLM+NSP+随机mask实体的方法
模型结构:

如图所示,其中T-encoder用来提取输入端的基础词法信息,这部分与BERT一样,把从embedding层输入的文本送到Transformer中做特征提取。K-enocder是本文的创新点,用来将外部的指示图信息融入。其中外部信息包括T-encoder的结果和TransE计算出的知识嵌入。
2. ERNIE: Enhanced Representation through Knowledge Integration (ERNIE2.0)
本文中正式引入了continual learning以达成多任务模型,为了解决多种任务,作者新增了task embedding。模型结构如下:
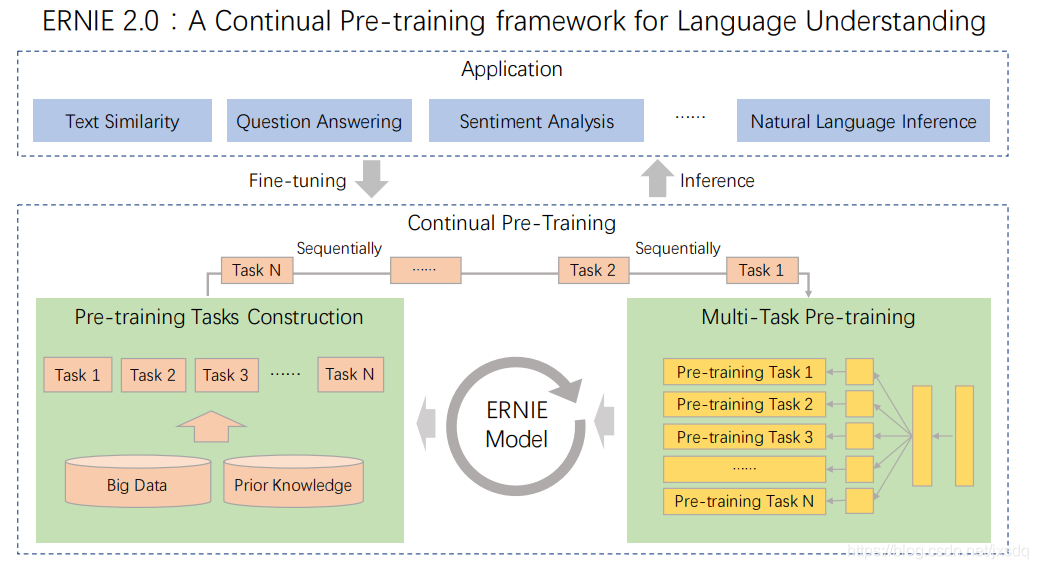
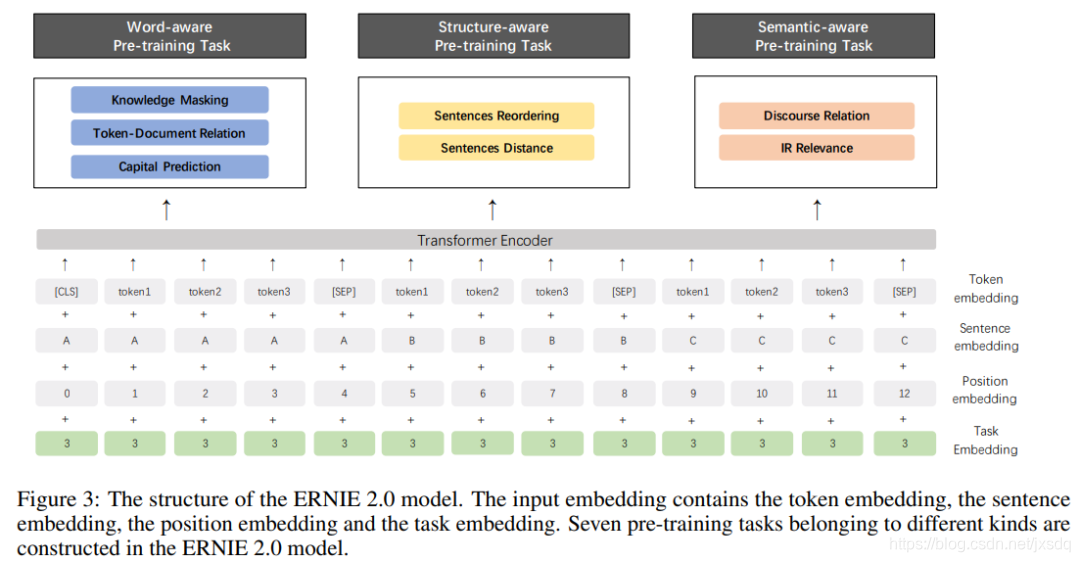
如图所示,任务被分成了三类:
- Word-aware Pre-training Tasks:其中包括knowledge masking task(常规mask),Capitalization prediction task(预测大写),Token-Document relation prediction task(预测某一个段落的token是否出现在同一篇文档的另外段落中)。
- Structure-aware Pre-training Tasks:包括Sentence Reordering Task(把一段话分割成多个片段进行重排顺序),Sentence distance task(预测句子之间的距离,三分类任务)
- Semantic-aware Pre-training Tasks:包括Disclosure relation task(预测句子间的语义关系),IR relevance task(信息解锁文本的相关性)
3. ERNIE-Tiny
作为轻量版的预训练模型,Tiny的体积要比base小很多,运行速度也比ERNIE-base快了4.3倍。Tiny使用了更浅的模型,更大的hidden-size,使用了subword代替char(增大了词粒度,缩小了文本长度),同时也使用了知识蒸馏的方法(tiny为学生模型,base为老师模型)。
Tiny中的知识蒸馏:
关于如何缩小体积很大的预训练模型,一般有以下几种方法:
- 知识蒸馏Distillation:通过将大模型的知识提取,转移导入到小模型中的过程。使用大模型作为老师模型,通过输入训练数据到老师模型,用以训练学生模型,使学生模型达到相似效果。
- 量化Quantization:将高精度的模型使用低精度表示,使模型变小
- 剪枝Pruning:减掉对结果无用的部分模型,精细化模型。剪枝的具体操作是将剪掉的部分模型参数设置为0.分为权重剪枝,神经元剪枝,权重矩阵剪枝。
4.Cross-lingual Language Model Pretraining
对于BERT的改进可以大体分为两个方向:第一个是纵向,即去研究bert模型结构或者算法优化等方面的问题,致力于提出一种比bert效果更好更轻量级的模型;第二个方向是横向,即在bert的基础上稍作修改去探索那些vanilla bert还没有触及的领域。直观上来看第二个方向明显会比第一个方向简单,关键是出效果更快。本文就属于第二类。
本文使用了跨语言的语言模型XLM,使用了两种预训练方法:
- 基于单语语料的无监督学习
- 基于跨语言的平行语料库的有监督学习
其在几个多语任务上比如XNLI和机器翻译都拉高了SOTA。那么我们就来看看具体的模型,整体框架和BERT是非常类似,修改了几个预训练目标。
- Shared sub-word vocabulary:目前的词向量基本都是在单语言语料集中训练得到的,所以其embedding不能涵盖跨语言的语义信息。为了更好地将多语言的信息融合在一个共享的词表中,作者在文本预处理上使用了字节对编码算法(「Byte Pair Encoding (BPE)」),大致思想就是利用单个未使用的符号迭代地替换给定数据集中最频繁的符号对(原始字节)。这样处理后的词表就对语言的种类不敏感了,更多关注的是语言的组织结构。
- Masked Language modeling (MLM)
- Causal Language Modeling (CLM)
- Translation Language Modeling (TLM):是本文的核心,用有监督的跨语言并行数据训练模型
5. Massively Multilingual Sentence Embeddings for Zero-Shot Cross-Lingual Transfer and Beyond
提出了LASER,使用单个模型解决多语言问题,模型结构:
6. MASS: Masked Sequence to Sequence Pre-training for Language Generation
问题:传统的BERT不能解决NLG生成问题。
不同于BERT仅使用Transformer的encoder,作者提出联合训练Transformer的encoder和decoder来解决这个问题。其中encoder训练使用了MLM,decoder的训练输入为与encoder一样的句子,但是做相反的masking。
7.Unified Language Model Pre-training for Natural Language Understanding and Generation(Microsoft/2019)
同样是为了解决NLG问题,UNILM这个模型直接解决掉NLU和NLG两方面的问题,是典型的的多任务模型。
预训练模型的目标函数有三种:
- 单向语言模型,如ELMo,GPT
- 双向语言模型,如BERT
- SeqSeq模型
这三个函数使用一组Transformer进行训练,参数共享。
目标函数示意:

模型输入为一串序列(或一对序列,依照目标函数的格式),在embedding部分与一般的BERT是一样的,分成token/position/segment embedding.
mask部分使用了self attention,即为对不同的模型使用不同的mask方法,目的是同意语言模型。本文中共有三种mask形式。依照三种目标函数定义:
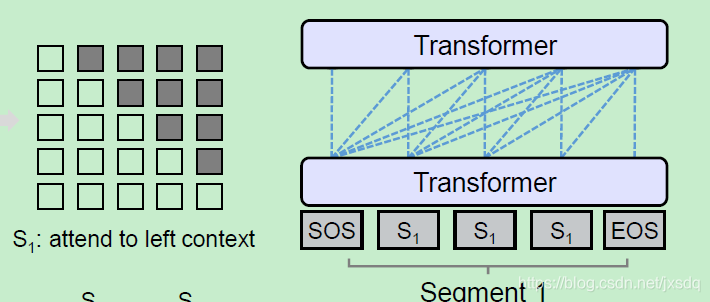
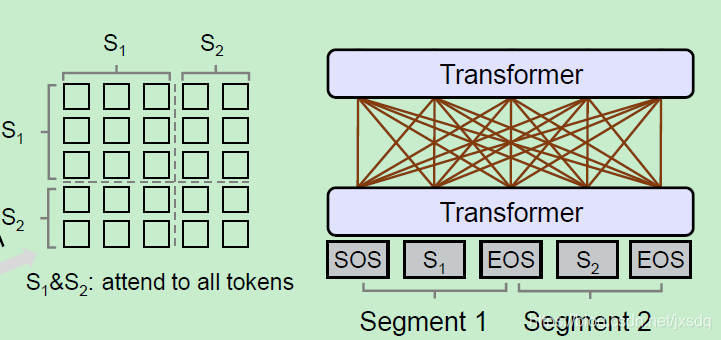

8.结论
- 模型和数据都很大,但是最终出来的效果是美的,争取往小而美的方向发展;
- 相比于BERT仅仅关注在encoder上,LASER的工作则是考虑了encoder-decoder的联合训练。从LASER模型框架上也可以看出其无法提取word级别的特征,擅长于跨语言任务;
- 对于XLM和MASS都是涉及跨语言模型,补充了BERT在NLG任务上的不足。模型层面而言XLM没有使用传统的encoder-decoder框架,属于比较讨巧的方式;
- UNILM可以同时处理NLU和NLG任务,在GLUE上首次不加外部数据打赢了BERT。后续的改进可以考虑加入跨语言任务的预训练,比如XLM和MASS做的工作。
Ref:
ERNIE: Enhanced Language Representation with Informative Entities(THU/ACL2019)
ERNIE2.0: A Continual Pre-training Framework for Language Understanding
ERNIE-tiny
Cross-lingual Language Model Pretraining
XLM – Enhancing BERT for Cross-lingual Language Model
Massively Multilingual Sentence Embeddings for Zero-Shot Cross-Lingual Transfer and Beyond
MASS: Masked Sequence to Sequence Pre-training for Language Generation
Unified Language Model Pre-training for Natural Language Understanding and Generation(Microsoft/2019)
芝麻街跨界NLP | 预训练模型专辑(二)
芝麻街跨界NLP,没有一个ERNIE是无辜的