对比学习历程总结
前面讲过MOCO ,对Contrast Learning有个简单的介绍
https://blog.csdn.net/m0_51421744/article/details/128435863?spm=1001.2014.3001.5502
目录
CPC
生成式模型

算法流程
- 首先以音频信号为例,进行输入
- 然后进行gar这种自回归模型(比如RNN\LSTM)
- 得到的CT:也就是
context representations上下文的一个表示 - 如果这个表示足够好,那他就可以预测下一个信号,进行信号生成
对比学习
和谁对比的学?输入经过编码器后的输出就是正样本即图中的Ct(融合了过去的信息),那负样本就很多了,比如任意时刻的输入经过编码后的值都可以是负样本(随机采样得到)
CMC
目的就是为了学习到一种关键特征,能够表示多视角的交互信息

对比学习
显然算法通过一个物体的同视角(深度图、灰度图、RGB图像等等)得到的特征距离尽可能的近,不同的物体之间的视角距离拉远实现对比学习。
用一个图片一个视角的多模态的多种形式的图片作为一组正样本,换到另外一个视角就是负样本了。但是这种多模态就会导致你可能需要多个编码器,而使用transformer去实现多个数据的编码,就不用针对某个数据做特有的改变,所以说transformer为什么越来越流行了。
简单总结
从CPC和CMC可以看出,对比学习通过不同的代理任务的实现。也就是说正负样本搞好之后,之后的工作就大差不差。
MOCO & SIMCLR
SIMCLR

算法流程
- 图片经过数据增强作为两个分支的两个输入
- 经过encoder编码器编码
- 再经过projector非线性降维
- 计算相似度
- 反向传播更新两个encoder
两个encoder的结构是完全一致的

对比学习
显然,一个图片的不同数据增强为正样本对,其他所有不同的图片以及他们的数据增强后的图片,都作为负样本对进行学习。
MOCO

算法流程
- 图片经过不同的数据增强作为输入,momentum encoder包含一个batch size的数据作为输入(只有一个正样本)
- 经过编码器编码
- 计算相似度,计算损失(一个队列大小的数据作为负样本)
- 梯度回传更新encoder,encoder更新momentum encoder
- 更新队列,一个batch size大小的数据进入队列,队列中最早的batch size数据出队
对比学习
MOCO解决了memory bank(将所有图片的特征存起来)存在的容量限制问题,也实现momentum encoder保证了负样本之间的一致性。后面还有MOCOv2、MOCOv3。骨干网络换一换,比如MOCOv3:MOCOv2 + 骨干网络转换成vit。
简单总结
SimcCLR之所以能够很直白的利用两个一样的encoder直接去train,是因为他用了很大很大的batch,我们都知道对比学习很重要的一个因素是负样本的数目,只有足够的特征,才有可能学习到那些真正区分开物体的特征,避免机器走捷径。MOCO正好解决了大batch带来的算力问题,提出队列和momentum encoder,将字典的大小和batch size彻底分离开。
SWAV
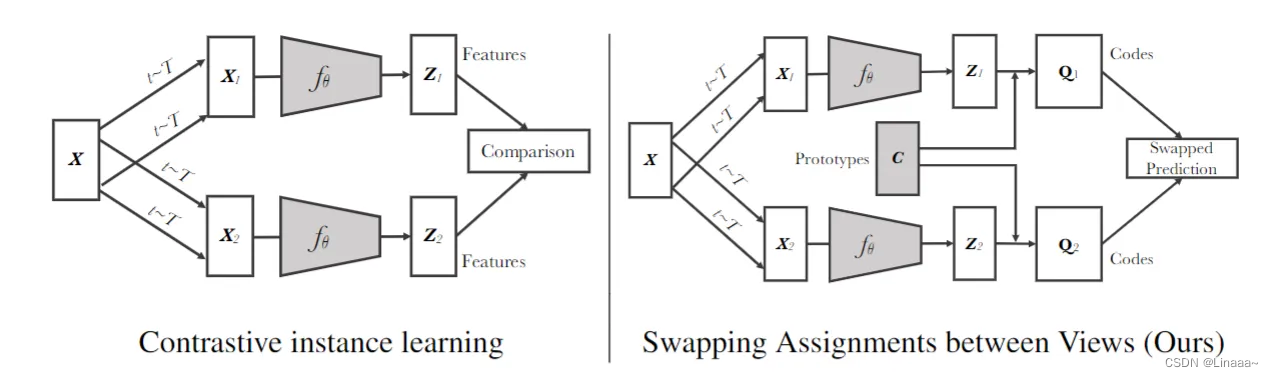
给定同样一张图片,如果去生成不同的视角,希望用这一个视角的特征得到另外一个视角的特征:把对比学习和之前的聚类方法融合在一起
算法流程
因为他的pretext task不是个体判别,而是一张图片的不同视角通过聚类属于同一个原型的概率更大。所以从图中可以看出,SWAV和一般的对比学习结构(MOCO、SIMCLR等等)不同点,在于加入K个原型(prototype)。
K个原型代表K个类别,每个输入通过encode、projector后需要计算得到它属于哪个原型的概率最大,目标是让正样本对属于同一个原型。
很容易想到所有图片都被分类到一个原型上(short cut),所以SWAV通过计算一个最优分配概率q(code),按照最优运输的思想,在满足类间平衡约束的情况下,将batch中样本按照q分配到k个类中,使得与原型相似(內积大)的样本尽量被分到一起。
对比学习
使用了不一样的代理任务,通过聚类的方式,让正样本对距离拉近,通过最优分配概率避免机器走捷径。
相似的算法还有PCL,使用了EM算法的思路:
- 先走E步:momentum encoder从所有样本中提取表征,并对表征做k-means聚类,得到每个样本所属类别、以及聚类中心
- 再走M步:从数据集中采样若干个batch,然后分别通过encoder和momentum encoder获得表征,计算聚类对比loss,梯度更新encoder
BYOL
将配对的问题换成一个预测的问题,和SWAV很像。SWAV是把配对的问题换成一个预测的问题,但是还是借助了聚类中心来进行预测。

算法流程
从图中可以看到:
- 通过数据增强后输入
- encoder得到特征
- projector进行非线性降维(从SimCLR开始有的,加上效果会更好或者是能train?)
- encoder得到输出进行预测,预测的是什么?
用一个视角的特征取预测另外一个视角的特征 - 预测得到的和下面原本的输出计算loss
- 反向传播更新encoder,图中也可以看到下分支是由上分支负责更新的
对比学习
这是个很神奇的算法,没有负样本的事了已经。因为说是对比学习,但是根据之前MOCO、SimClR需要大量的负样本去学习本质特征这种概念,觉得不可能train的起来,但是就是取得了很好的效果。后面有关BN泄露了负样本的信息(均值和方差的计算,从另一个方面提供了负样本的信息),也被反驳。因为不用BN,改用Group Norm和Weight standardization参数初始化方式也能取得很好的效果。
SimSam孪生网络

算法流程
很简单的一个结构,左右的结构是一样的encoder。比BYOL更厉害,它连动量编码器都不用,也就是说不用负样本、不用动量编码器,两个分支的encoder共享参数,但是一个分支不进行梯度回传,目标函数就是一张图片的两个视图相似度最大。
损失函数是两个数据增强后的图片,一个作为x1,一个作为x2,计算一个损失,然后交换线路走,又一个损失。总损失函数是两个损失函数(对称loss)均值。
总结
总的来说,对比学习从最初提出不同的pretext task(CMC,CPC);正负样本对比学习:到后面基于个体判别的SimCLR、MOCO;再到聚类的SWAV、PCL;再到不要负样本的BYOL、SimSam。可以看到基本就是目标函数的改变、数据的改变这两个方面入手。