在训练网络的时候,loss不断的增加,一直增大到nan。之前怀疑是损失函数的问题,之前使用的BCEloss,于是考虑换dice loss,运行之后发现loss还是在增加,而且增加的非常快,epoch0的第一个iteration为15,往后第三个第四个就增长到了25,30以及训练到后面几代直接就会显示损失为nan。
在之前使用dice loss就没,就没有出现这种情况,损失都是慢慢下降:

因此肯定是代码出现了问题,损失不断上升,梯度为nan,说明梯度爆炸,并且模型无法收敛,因为我是语义分割,之前一百代就可以达到0.4多,现在一百多代还是0.0001。

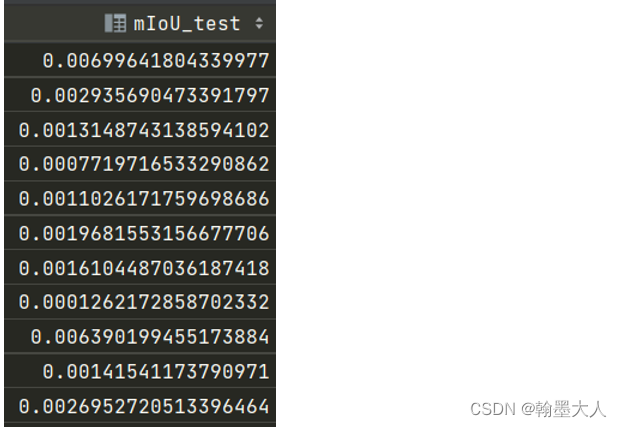
如何解决?因为我之前没有发生过梯度爆炸,模型代码也没有变,只换了个损失函数,肯定是训练的代码有问题。猜测:第一次训练结束的时候梯度没有清零,导致第二次计算时候第一次的梯度也进行累计,导致损失不断上升。
经过仔细排查发现代码的问题了:
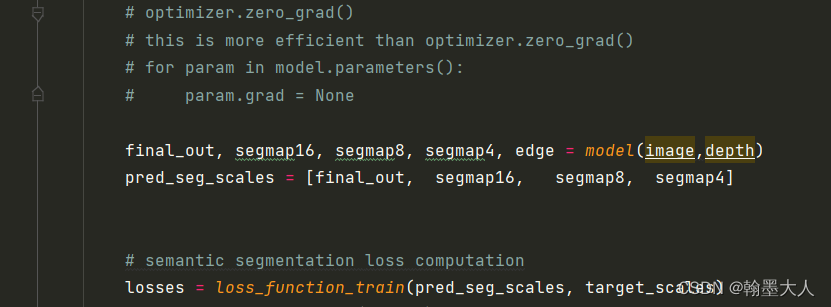
在计算损失之前不知道什么时候将如下代码注释掉了。
# for param in model.parameters():
# param.grad = None
我们知道在一个epoch中,首先要将梯度清零,接着计算损失,接着优化器更新。这句代码就是将模型中的每个参数梯度至为None,上一次梯度清空。图片参考

修改:将模型梯度清空这个"开关"打开。
for param in model.parameters():
param.grad = None
这个代码意思和下面那个一样:只需要打开一个就行。
# optimizer.zero_grad()
查看损失变换:
