在机器学习中,确定性和随机方法根据其有用性被用于不同的领域。确定性过程认为,没有随机偏差的已知平均比率适用于庞大的人口。另一方面,随机过程定义了反映潜在样本路径的按时间排序的随机变量的集合。
1、确定性和随机过程建模
无论模型被重新计算多少次,确定性建模都会为给定的一组输入产生一致的结果。在这种情况下,数学特征是已知的。它们都不是随机的,每个问题只有一组指定的值以及一个答案或解决方案。确定性模型中的未知组件在模型外部。它处理的是确定的结果,而不是随机的结果,并且不考虑错误。
相比之下,随机建模本质上是不可预测的,并且未知组件被集成到模型中。该模型会生成大量答案、估计和结果,就像将变量添加到困难的数学问题中以查看它们如何影响解决方案一样。然后在不同的设置中多次执行相同的过程。
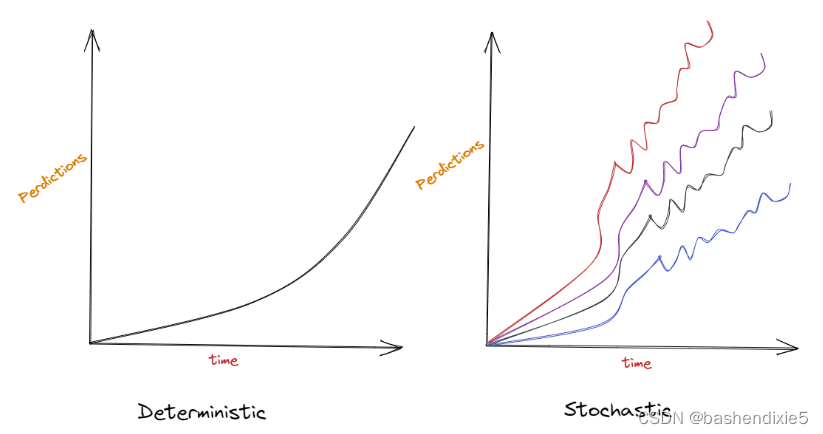
2、何时使用它们
确定性模型适用于通过状态和事件之间的已知关系精确确定结果,其中没有随机性或不确定性。
例如,如果我们知道摄入固定量的糖“y”会使人体内的脂肪增加“2 倍”。那么当“x”的值已知时,“y”总是可以准确地确定。
同样,当变量之间的关系未知或不确定时,可以使用随机建模,因为它依赖于事件概率的似然估计。
例如,保险业主要依靠随机模型来预测公司资产负债表在未来的表现。
由于确定性模型显示了结果与影响结果的因素之间的关系。对于这种模型,变量之间的关系应该是已知的或确定的。
让我们考虑构建一个可以帮助 100 米短跑运动员的机器学习器,100 米短跑中最重要的因素是时间。该模型的目标是尽量减少运动员的时间。影响时间的两个最重要的因素是速度和距离。
每个运动员跑过的距离都是一样的,对每个人来说都是不变的,唯一不同的是速度。但是可以控制变化的速度,因为影响速度的因素被称为身体的位置、飞行时间等。由于我们知道时间取决于速度和距离,这使得这个问题具有确定性。


机器学习算法的随机性在用于解决分类和回归预测建模问题的复杂和非线性方法中最为明显。这些方法在从训练数据构建模型的过程中采用随机化,导致每次对相同数据执行相同算法时拟合不同的模型。
因此,当在保持测试数据集上进行测试时,稍微修改的模型表现不同。由于这种随机行为,必须使用汇总统计数据来描述模型的性能,这些统计数据表明模型的平均或预测性能,而不是模型在任何单个训练会话中的性能。
让我们考虑一个掷骰子问题。你在赌场掷骰子。如果您掷出六或一,您将赢得现金奖励。最初,将生成一个包含掷骰结果的所有可能性的样本空间。计算任何数字被滚动的概率为“0.17”。但我们只对两个数字感兴趣,“6”和“1”。所以最终的概率是 0.33。这就是随机模型的工作方式。
让我们看看线性回归模型如何在不同场景中既作为确定性模型又作为随机模型工作。
确定性模型定义了变量之间的精确联系。在确定性场景中,线性回归具有三个组成部分。因变量“y”、自变量“x”和截距“c”。对于给定的 x,在预测 y 时没有出错的余地。这是一个方程式作为示例来复制上述解释。

上面的等式将有一个类似这样的图形,所有数据点都在一条直线上。
考虑随机误差的随机模型。存在确定性分量和随机误差分量。在这个范式中假设 y 和 x 之间的概率联系。

在上图中,可以观察到由于线性回归方程中的误差分量,数据存在随机性。
3、不同形式的随机和确定性算法
(1)主成分分析 (PCA)
PCA是一种确定性方法,因为没有要初始化的参数。在给定 n 维空间中的一组点的情况下,PCA 找到通过质心的线,点之间的距离平方和最小。确定点在该线上的投影尽可能大的线是同一件事(通过平方长度之和来衡量)。
然后,在与第一条线正交的限制下,找到通过质心的与点的距离平方和最小的线。第三个主成分,第四个,依此类推。由于所有这些过程都是简单的几何过程,因此主要组件是确定性数据函数。
(2)加权最近邻
加权最近邻方法也可以称为基本KNN,是一种确定性方法。该技术采用称为“加权函数”的统计数据。通过取距离的倒数确定权重。因为每个数据点和查询点之间的距离在每次迭代中都是相同的,所以权重将是一个确定性术语。
(3)泊松过程
Poisson 方法是一个随机过程,它显示随机数量的点或随时间发生的事件。过程中介于零和特定周期之间的点数被表征为与时间相关的泊松随机变量。该过程的索引集由非负整数组成,而状态空间由自然数组成。这种方法被称为泊松计数过程,因为它可以被认为是一种计数操作。
(4)伯努利过程
伯努利过程是一组随机分布的随机变量,每个变量的概率为 1 或 0。这个过程类似于不断掷硬币,获胜的概率为 p,值为 1。结果是概率性的,这就是该方法是随机过程的原因。
(5)随机游走
简单随机游走是使用整数作为状态空间的离散时间随机过程,它基于伯努利过程,每个伯努利变量取正值或负值。
4、确定性和随机性的优缺点
(1)优点
确定性模型具有简单的优势。
确定性更容易掌握,因此可能更适合某些情况。
随机模型提供了各种可能的结果以及每种结果的相对可能性。
随机模型使用最常见的方法来获得结果。
(2)缺点
在确定性方法中,没有累积概率导致低储备情况过度乐观。
在随机方法中,模型更复杂,也称为黑盒方法。
偏差可能隐藏在随机模型中,它侧重于极端情况。
5、确定性和随机算法的应用
确定性模型用于洪水风险分析。
图灵机中使用的确定性模型是一种能够枚举可接受字母字符串的任意子集的机器(自动机);这些字符串是递归可枚举集合的一部分。图灵机有一个无限长的磁带来执行读写操作。
随机投资模型旨在估计价格变化、资产回报率 (ROA) 和资产类别(如债券和股票)。它使用蒙特卡洛模拟,它可以根据单个股票收益的概率分布来模拟投资组合的表现。
随机建模会影响营销和观众口味和偏好的变化,以及特定电影客串的征集和科学吸引力(即,开幕周末、口碑、被调查群体中的热门知识、明星名称识别,以及社交媒体推广和广告的其他元素)。
确定性方法具有简单易懂的结构,只有在确定变量之间的关系时才能应用;另一方面,随机方法具有复杂且难以理解的结构,适用于概率的可能性。