系统环境
- JetPack4.3
如果需要此镜像的同学可以在Jetson 下载中心下载即可。
安装PaddlePaddle
有两种方式,因为nano官方有已经编译好的python3.6的whl,所以我们直接下载就好,不用编译。
直接下载官方编译好的Jetson all预测库
下载地址
下载
选择python3.6版本的下载即可。

2.安装依赖项
安装pip3并升级:
sudo apt-get install python3-pip
pip3 install --upgrade pip
换源,修改 ~/.pip/pip.config:
mkdir ~/.pip
vim ~/.pip/pip.conf
添加内容如下:
[global]
index-url = https://pypi.tuna.tsinghua.edu.cn/simple
[install]
trusted-host = https://pypi.tuna.tsinghua.edu.cn
这里必须安装1.18.3版本的numpy,否则后边会报错。
pip3 install numpy==1.18.3
3.安装whl
将下载好的whl文件传送到板子上上,然后安装whl:
pip3 install paddlepaddle_gpu-2.0.0-cp36-cp36m-linux_aarch64.whl
安装成功截图:

4.测试
打开python3:
import paddle
paddle.fluid.install_check.run_check()
报warning忽略即可,不影响使用。

测试Paddle Inference
环境准备
拉取Paddle-Inference-Demo:
git clone https://github.com/PaddlePaddle/Paddle-Inference-Demo.git
拉取比较慢的话可以在gitee上建个仓库下载,我建的仓库:https://gitee.com/irvingao/Paddle-Inference-Demo.git。
测试跑通GPU预测模型
给可执行权限:
cd Paddle-Inference-Demo/python
chmod +x run_demo.sh
然后打开Run_demo.sh,删掉x86那个demo,把ELMO改成ELMo

需要注意的是,需要将所有子文件夹中的run.sh最后的python修改为python3:
./run_demo.sh
也可以选择运行单个模型的run.sh。

如果能全部跑下来没问题就说明部署成功啦。将自己的模型直接在AGX上跑即可~
报错解决
core dumped
原因是因为JetPack4.3自带的numpy版本不对,numpy版本应为1.18.3。
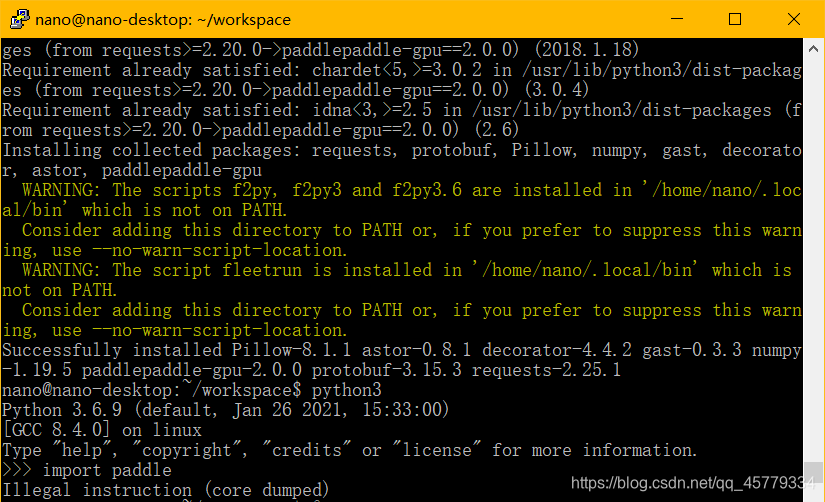
解决方法:
pip3 uninstall numpy
python3 -m pip install numpy==1.18.3 -i https://mirror.baidu.com/pypi/simple