1. Redis 存储
由于Redis的数据都存放在内存中,如果没有配置持久化,redis重启后数据就全丢失了,于是需要开启redis的持久化功能,将数据保存到磁盘上,当redis重启后,可以从磁盘中恢复数据。redis提供两种方式进行持久化,一种是RDB持久化(原理是将Reids在内存中的数据库记录定时dump到磁盘上的RDB持久化),另外一种是AOF持久化(原理是将Reids的操作日志以追加的方式写入文件)。
1.1 RDB
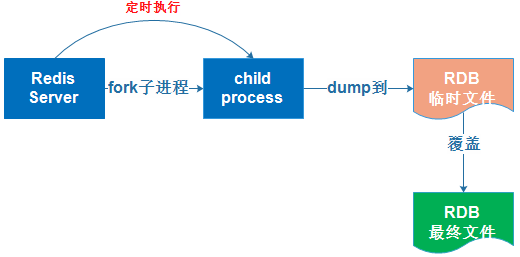
RDB持久化是指在指定的时间间隔内将内存中的数据集快照写入磁盘,实际操作过程是fork一个子进程,先将数据集写入临时文件,写入成功后,再替换之前的文件,用二进制压缩存储。
1.1.1 优势
1). 一旦采用该方式,那么你的整个Redis数据库将只包含一个文件,这对于文件备份而言是非常完美的。比如,你可能打算每个小时归档一次最近24小时的数据,同时还要每天归档一次最近30天的数据。通过这样的备份策略,一旦系统出现灾难性故障,我们可以非常容易的进行恢复。
2). 对于灾难恢复而言,RDB是非常不错的选择。因为我们可以非常轻松的将一个单独的文件压缩后再转移到其它存储介质上。
3). 性能最大化。对于Redis的服务进程而言,在开始持久化时,它唯一需要做的只是fork出子进程,之后再由子进程完成这些持久化的工作,这样就可以极大的避免服务进程执行IO操作了。
4). 相比于AOF机制,如果数据集很大,RDB的启动效率会更高。
1.1.2 劣势
1). 如果你想保证数据的高可用性,即最大限度的避免数据丢失,那么RDB将不是一个很好的选择。因为系统一旦在定时持久化之前出现宕机现象,此前没有来得及写入磁盘的数据都将丢失。
2). 由于RDB是通过fork子进程来协助完成数据持久化工作的,因此,如果当数据集较大时,可能会导致整个服务器停止服务几百毫秒,甚至是1秒钟。
1.2 AOF
AOF持久化以日志的形式记录服务器所处理的每一个写、删除操作,查询操作不会记录,以文本的方式记录,可以打开文件看到详细的操作记录。

1.2.1 优势
1). 该机制可以带来更高的数据安全性,即数据持久性。Redis中提供了3中同步策略,即每秒同步、每修改同步和不同步。事实上,每秒同步也是异步完成的,其效率也是非常高的,所差的是一旦系统出现宕机现象,那么这一秒钟之内修改的数据将会丢失。而每修改同步,我们可以将其视为同步持久化,即每次发生的数据变化都会被立即记录到磁盘中。可以预见,这种方式在效率上是最低的。至于无同步,无需多言,我想大家都能正确的理解它。
2). 由于该机制对日志文件的写入操作采用的是append模式,因此在写入过程中即使出现宕机现象,也不会破坏日志文件中已经存在的内容。然而如果我们本次操作只是写入了一半数据就出现了系统崩溃问题,不用担心,在Redis下一次启动之前,我们可以通过redis-check-aof工具来帮助我们解决数据一致性的问题。
3). 如果日志过大,Redis可以自动启用rewrite机制。即Redis以append模式不断的将修改数据写入到老的磁盘文件中,同时Redis还会创建一个新的文件用于记录此期间有哪些修改命令被执行。因此在进行rewrite切换时可以更好的保证数据安全性。
4). AOF包含一个格式清晰、易于理解的日志文件用于记录所有的修改操作。事实上,我们也可以通过该文件完成数据的重建。
1.2.2 劣势
1). 对于相同数量的数据集而言,AOF文件通常要大于RDB文件。RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快。
2). 根据同步策略的不同,AOF在运行效率上往往会慢于RDB。总之,每秒同步策略的效率是比较高的,同步禁用策略的效率和RDB一样高效。
1.3 选择策略
二者选择的标准,就是看系统是愿意牺牲一些性能,换取更高的缓存一致性(aof),还是愿意写操作频繁的时候,不启用备份来换取更高的性能,待手动运行save的时候,再做备份(rdb)。rdb这个就更有些 eventually consistent的意思了。不过生产环境其实更多都是二者结合使用的。
参考:
2. Redis 报错处理
redis使用中经常出现 Could not get a resource from the pool 异常:
redis.clients.jedis.exceptions.JedisExhaustedPoolException: Could not get a resource since the pool is exhausted] with root cause;java.util.NoSuchElementException: Unable to validate object
redis.clients.jedis.exceptions.JedisException: Could not get a resource from the pool
-
主要是连接池配置和释放连接 ,**没有及时释放连接造成的连接池内无连接可用。**但是redisDao中都添加了jedis.close()
-
目前通过重启redis并在jedis.close()后添加 jedis=null 解决。
-
连接池配置参数
-
最大连接数:MAX_ACTIVE, 支持同时在使用的最大的连接数量。设置太大可能会浪费系统性能。
-
等待可用连接的最大时间:MAX_WAIT
-
有时为了保证请求快速得到响应,保持一定的空闲连接(setMinIdle)。在连接池饱和状态,最多有(MAX_ACTIVE-MinIdle)个连接数
-
在 Redis2.4 中,最大连接数是被直接硬编码在代码里面的,而在2.6版本中这个值变成可配置的。maxclients 的默认值是 10000也就是说,redis默认最多允许10000个连接。当然这还要看硬件环境,CPU/内存情况;有再大的需求,就只能是分布式/集群了。
-
参考这个链接修改了参数:https://blog.csdn.net/jiguquan3839/article/details/90739263
-
参考:解决办法总结
LOADING Redis is loading the dataset in memory
- redis.conf中 maxmemory 调大,同时开启转换功能
maxmemory 30GB
maxmemory-policy allkeys-lru
appendonly no #关闭AOF模式,默认关闭
- redis 实例启动的时候,自动加载 aof 文件。需要确保提供的最大memory大于dump的文件,否则将导致数据无法完全加载进来。
- 如果文件超过 6G,加载需要一定时间。启动时,redis 会先监听端口,再进行 aof 数据加载,以便于客户端及时掌握redis的加载进度。 加载 aof 时,ping 命令会返回 LOADING,此时redis 不可读也不可写。 如果是主节点,主节点 loading=1, 客户端的状态 master_link_status=down; 如果是从节点, loading=1, master_link_status=err, flags=slaves。 一般 redis 驱动只有判断 flags 为 s_down o_down disconnected 这三种状态判断节点不可用。 loading 时, redis 和 sentinel 都认为此节点可正常提供服务,其实这个时候不可读也不可写。
redis.exceptions.ResponseError: MISCONF Redis is configured to save RDB snap
- 使用python往redis中导数据时出现
- 错误原因:强制把redis快照关闭了导致不能持久化的问题。
- 出现原因:
- 解决方案(未尝试,目前方法为直接重启redis):
1.通过redis-cli连接到服务器后执行以下命令:
config set stop-writes-on-bgsave-error no
2.修改redis.conf文件:vi打开redis-server配置的redis.conf文件,然后定位到stop-writes-on-bgsave-error字符串所在位置,接着把后面的yes设置为no即可。
python导入数据:redis.exceptions.ResponseError: MISCONF Redis is configured to save RDB snapshots, but it is currently not able to persist on disk. Commands that may modify the data set are disabled, because this instance is configured to report errors during writes if RDB snapshotting fails (stop-writes-on-bgsave-error option). Please check the Redis logs for details about the RDB error.
redis的log信息:# Write error saving DB on disk: No space left on device
- 硬盘存储不足,扩充硬盘
3. Redis 集群与分片
-
横向:多台主机协同提供服务,即分布式多个Redis实例协同运行。
-
纵向:一台机器上同时跑多个Redis实例(多线程配合)。
3.1 基于客户端sharding的Redis Sharding
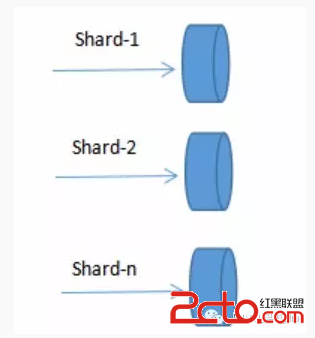
Redis Sharding可以说是Redis Cluster出来之前,业界普遍使用的多Redis实例集群方法。其主要思想是采用哈希算法将Redis数据的key进行散列,通过hash函数,特定的key会映射到特定的Redis节点上。这样,客户端就知道该向哪个Redis节点操作数据。Sharding架构如图:
庆幸的是,Java redis客户端驱动jedis,已支持Redis Sharding功能,即ShardedJedis以及结合缓存池的ShardedJedisPool。
3.2 基于服务端sharding的Redis Cluster
Redis Cluster是一种服务器Sharding技术,3.0版本开始正式提供。Redis Cluster中,Sharding采用slot(槽)的概念,一共分成16384个槽,这有点儿类似前面讲的pre sharding思路。对于每个进入Redis的键值对,根据key进行散列,分配到这16384个slot中的某一个中。使用的hash算法也比较简单,就是CRC16后16384取模。Redis集群中的每个node(节点)负责分摊这16384个slot中的一部分,也就是说,每个slot都对应一个node负责处理。当动态添加或减少node节点时,需要将16384个槽做个再分配,槽中的键值也要迁移。当然,这一过程,在目前实现中,还处于半自动状态,需要人工介入。
Redis集群,要保证16384个槽对应的node都正常工作,如果某个node发生故障,那它负责的slots也就失效,整个集群将不能工作。为了增加集群的可访问性,官方推荐的方案是将node配置成主从结构,即一个master主节点,挂n个slave从节点。这时,如果主节点失效,Redis Cluster会根据选举算法从slave节点中选择一个上升为主节点,整个集群继续对外提供服务。这非常类似前篇文章提到的Redis Sharding场景下服务器节点通过Sentinel监控架构成主从结构,只是Redis Cluster本身提供了故障转移容错的能力。
Redis Cluster的新节点识别能力、故障判断及故障转移能力是通过集群中的每个node都在和其它nodes进行通信,这被称为集群总线(cluster bus)。它们使用特殊的端口号,即对外服务端口号加10000。例如如果某个node的端口号是6379,那么它与其它nodes通信的端口号是16379。nodes之间的通信采用特殊的二进制协议。
对客户端来说,整个cluster被看做是一个整体,客户端可以连接任意一个node进行操作,就像操作单一Redis实例一样,当客户端操作的key没有分配到该node上时,就像操作单一Redis实例一样,当客户端操作的key没有分配到该node上时,Redis会返回转向指令,指向正确的node,这有点儿像浏览器页面的302 redirect跳转。
Redis Cluster是Redis 3.0以后才正式推出,时间较晚,目前能证明在大规模生产环境下成功的案例还不是很多,需要时间检验。
3.3 代理中间件实现大规模Redis集群
例如twemproxy处于客户端和服务器的中间,将客户端发来的请求,进行一定的处理后(如sharding),再转发给后端真正的Redis服务器。也就是说,客户端不直接访问Redis服务器,而是通过twemproxy代理中间件间接访问。
3.4 目前的部署
目前的redis集群通过远程redis通讯,实现数据共享。数据分布存储的实现通过人工切分分别导入。
客户端对redis数据只进行读取。
参考资料:
4. Redis 高可用性
单机模式中,只要一个服务器宕机就不可以提供服务,这样会可能造成服务效率低下,甚至出现其相对应的服务应用不可用。 因此,Redis提供了多个高可用方案:
- Redis主从复制
- Redis持久化
- 哨兵集群
- ……
参考资料:
目前部署(107):
nc -vz IP PORT
crontab 1分钟判断一次ip端口状态
5. Redis 压缩存储
5.1 直观策略
- 精简键名和键值
- 使用整型/长整型
- 共享对象
- 使用byte[] 类型存储
5.2 内部编码优化
- 根据Redis内部编码规则来节省更多的空间
Redis为每种数据类型都提供了两种内部编码方式。以散列类型为例,散列类型是通过散列表实现的,这样就可以实现O(1)时间复杂度的查找、赋值操作,然而当键中元素很少的时候,O(1)的操作并不会比O(n)有明显的性能提高,所以这种情况下Redis会采用一种更为紧凑但性能稍差(获取元素的时间复杂度为O(n))的内部编码方式。
自动转换,无法人为定义。
参考文献:
6. Redis 高并发(Redis优势)
1.Redis是基于内存的,内存的读写速度非常快;
2.Redis是单线程的,省去了很多上下文切换线程的时间;
3.Redis使用多路复用技术,可以处理并发的连接。非阻塞IO 内部实现采用epoll,采用了epoll+自己实现的简单的事件框架。epoll中的读、写、关闭、连接都转化成了事件,然后利用epoll的多路复用特性,绝不在io上浪费一点时间。
参考资料:
7. 杂七杂八
虽然在后端框架中使用Java语言,但是在日常处理中笔者还是比较喜欢使用python。我感觉这是一个不好的习惯……