DataFrame常用基础操作
新建
import pandas as pd
import numpy as np
df=pd.DataFrame(np.random.randn(4,4),index=list('ABCD'),columns=list('ABCD'))
查看数据
head、tail函数
data.head() #查看前5条数据
data.head(3) #查看前3条数据
data.tail() #查看后5条数据
通过索引查看
区别是loc是根据行名,iloc是根据数字索引(也就是行号)。
iloc
基于整数位置(从轴的0到长度-1)的索引,但也可以与布尔数组一起使用。
详见Python pandas.DataFrame.iloc函数方法的使用
loc()
>>> df = pd.DataFrame([[1, 2], [4, 5], [7, 8]],
... index=['cobra', 'viper', 'sidewinder'],
... columns=['max_speed', 'shield'])
>>> df
max_speed shield
cobra 1 2
viper 4 5
sidewinder 7 8
Single label. Note this returns the row as a Series.
>>> df.loc['viper']
max_speed 4
shield 5
Name: viper, dtype: int64
List of labels. Note using [[]] returns a DataFrame.
>>> df.loc[['viper', 'sidewinder']]
max_speed shield
viper 4 5
sidewinder 7 8
Single label for row and column
>>> df.loc['cobra', 'shield']
2
参考: pandas官方文档
查看某列数据
data["列名"] #series类型
提取多列、多行数据
提取多列数据
1)利用loc
例如提取data数据集中’net_age’,‘user_lvl’, ‘l2m_comm_days’,'cust_type’这几列数据
data_new=data.loc[:,['net_age','user_lvl', 'l2m_comm_days','cust_type']]
2)列名提取
df = pd.DataFrame(columns=["usage","time,date","clock_time","hour,minute"])
temp_data = df[["date","hour","usage"]] #将df的"date","hour","usage"三列赋值给temp_data,注意中间是个列表,不然会报错
提取多行数据
例如提取某个大数据集的前100行:
train_data_small = data[:100]
查看某列中某个值
data["列名"][行索引号] #类型为datetime.date类,行索引号必须为0、1、2这样的数值,不能为行名
查看某列不重复的值:unique()
date_array = df["date"].unique()
unique()返回某列不重复的值,返回值是array类型。
查看某列不重复值及出现次数:value_counts()
value_counts()不仅可以查看某列的不重复值具体是哪些,还可以计算出每个不同值在该列中具体出现多少次。
value_counts()是Series拥有的方法,一般在DataFrame中使用时,需要指定对哪一列或行使用。
例如:
data["FLAG"].value_counts()
输出:
0 128729
1 1033
统计FLAG列不重复数:该列‘0’值有128729个,‘1’值有1033个
查看数据大小
data.shape #返回数据行数和列数
查看列名
data.columns #输出data1的所有列名
查看数据统计信息
data.describe(include="all").T
查看数据是否有重复
data.duplicated()
添加
添加一行数据
df1 = pd.DataFrame([['Snow','M',22],['Tyrion','M',32],['Sansa','F',18],'Arya','F',14]], columns=['name','gender','age'])
new=pd.DataFrame({'name':'lisa',
'gender':'F',
'age':19},
index=[1]) # 自定义索引为:1 ,这里也可以不设置index
print(new)
print("-------在原数据框df1最后一行新增一行,用append方法------------")
df1=df1.append(new,ignore_index=True) # ignore_index=True,表示不按原来的索引,从0开始自动递增
print(df1)
添加一列数据
df["a"] = [0]*len(df)
给df新增一列“a”,初始化为0.
指定位置插入空列
df = pd.DataFrame(np.random.randn(4, 4), index=list('ABCD'), columns=list('ABCD'))
col_name = df.columns.tolist()
col_name.insert(col_name.index('B'), 'x') # 在 B 列前面插入x列,值为NAN
df = df.reindex(columns=col_name)
print(df)
指定位置插入另一个df某列
df1.insert(col_name.index('B'), 'X', df2['D']) # B列前插入df2的“D”列,并起名为X
df1['性别1'] = df2['D'] # 追加一列
Pandas的DataFrame教程——指定位置增加删除一行一列
添加多个空列
old_column_list = df.columns.tolist()
new_column_list = []
new_column_list.extend(old_column_list)
add_list = ["1","2","3"]
new_column_list.extend(add_list)
df = df.reindex(columns=new_column_list) # 扩展数据集列,此时数值都为nan
df = df.fillna(0) # 所有扩展的列置为0
python-将多个空列添加到pandas DataFrame
修改
改变某一列的位置
如:先删除gender列,然后在原表data中第0列插入被删掉的列。
data.insert(0, '性别', data.pop('gender')) #pop返回删除的列,插入到第0列,并取新名为'性别'
重置索引
print(df.reset_index())
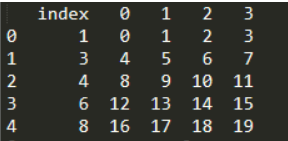
此时df获得了新的index列,而原来的index变成了数据列,保留了下来。
如果我们不想保留原来的index,直接使用重置后的索引,那么可以使用参数drop=True,默认值是False
print(df.reset_index(drop=True))
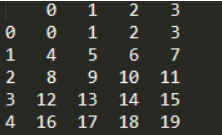
参考:pandas重置DataFrame或Series的索引index
删除
删除重复信息
data.drop_duplicates()
删除行(列)
drop()
删除行或列,默认删除行,删除列需要加axis = 1
格式:
df.drop(要删除的列名列表,axis=1,inplace=True) #inplace=True 在原数据上进行删除,否则原数据集没有改变,生成一个新的删除了数据的数据集
例子:
X=data.drop(["FLAG","ID_NO"],axis=1) #删除FLAG和ID_NO列
df.drop(['Unnamed: 0'],axis=1) #删除'Unnamed: 0'列
条件删除
df.drop(df[df.score < 50].index, inplace=True)
多条件情况:
可以使用操作符: | 只需其中一个成立, & 同时成立, ~ 表示取反,它们要用括号括起来。
例如删除列“score<50 和>20的所有行
df = df.drop(df[(df.score < 50) & (df.score > 20)].index)
[译]如何根据条件从pandas DataFrame中删除不需要的行?
删除nan值
df.dropna()# 删除原数据中的nan值,如果要在原数据中直接删除,加inplace=True
Dataframe高级技巧
多个dataframe合并
test_data = pd.concat((test_data, label), axis = 1)
axis = 1:按列合并
axis = 0:按行合并
Pandas中DataFrame数据合并、连接(concat、merge、join)
按照某列合并两个df
result=pd.merge(df_score,df_class,on='name') # 按照名字合并分数和班级
左连接
result = pd.merge(left, right, how='left', on=['key1', 'key2'])
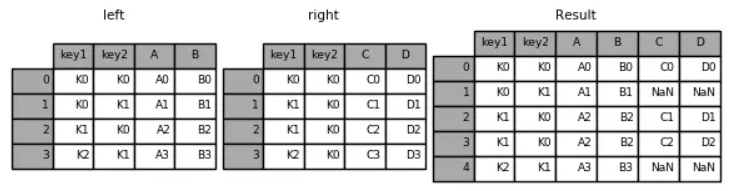
pandas之dataframe去掉冗余行以及左连接合并dataframe
排序、分类计数
sort_values:按照某个字段排序,默认升序
df.sort_values("score",inplace=True)
df.sort_values("score", ascending=False,inplace=True) # 降序
df按照score这个字段排序,inplace默认为False,表示原来的pd顺序没变,只是返回值是排序的。
sort_values后索引号是乱序的了,需要重置下索引:
df = df.reset_index(drop=True)
pandas数据排序(series排序 & DataFrame排序)
value_counts():对Series里面的每个值进行计数并且排序
现有一个DataFrame

如果我们想知道,每个区域出现了多少次,可以简单如下:
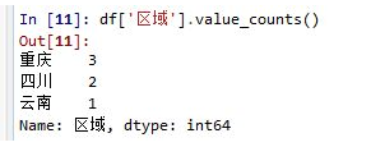
每个区域都被计数,并且默认从最高到最低做降序排列。
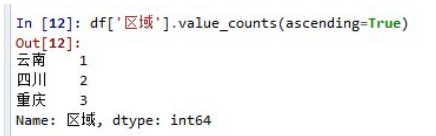
如果想用升序排列,可以加参数ascending=True:
如果想得出计数占比,可以加参数normalize=True:
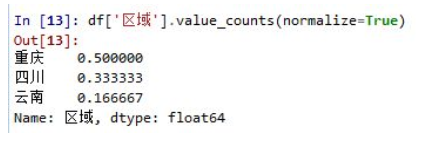
空值是默认剔除掉的。value_counts()返回的结果是一个Series数组,可以跟别的数组进行运算。
value_count()跟透视表里(pandas或者excel)的计数很相似,都是返回一组唯一值,并进行计数。这样能快速找出重复出现的值。
分类汇总
df.groupby('MAC')['域名'].count() #按照'MAC'列分组,对域名列计数
data.groupby('设备IP')['设备名'].nunique() #按照'设备IP'列分组,统计'设备名'列不重复的个数
输出如下:
设备IP
1*.1*.19*.10* 1
1*.1*.19*.11* 1
1*.1*.19*.11* 1
1*.1*.19*.12* 1
其他常用函数:mean,std, median, min, max
pandas实现分类汇总,查找不重复的一 一对应数据
多级分组
df.groupby(['MAC', '审计时间_date', '审计时间_hour','域名','标题','域名含义']).count()
#依次按照['MAC', '审计时间_date', '审计时间_hour','域名','标题','域名含义'列进行分组,然后对剩余的列计数
输出如下:

agg
pandas——很全的groupby、agg,对表格数据分组与统计
筛选
条件筛选
找出df中A列值为100的所有数据
df[df.A==100]
或:df[df[A]==100]
这里也可以是小于(<)、大于(>)、小于等于(<=)、大于等于(>=)、不等于(!=)等情况。
找出df中A列值为100、200、300的所有数据
num = [100, 200, 300]
df[df.A.isin(num)] #筛选出A列值在num列表的数据
找出df中A列值为100且B列值为‘a’的所有数据
df[(df.A==100)&(df.B=='a')]
找出df中A列值为100或B列值为‘b’的所有数据
df[(df.A==100)|(df.B=='b')]
获取条件筛选匹配值的行索引
df.index[df['BoolCol']].tolist() # 返回满足条件的行的索引值
Python Pandas 获取列匹配特定值的行的索引问题
参考:利用pandas进行条件筛选和组合筛选
按行筛选
data = pd.read_csv(r'2019-06-22.txt',header=None,sep=',')
data=data[data[6] == '132.77.1.1'] #筛选出第6列所有IP地址等于'132.77.1.1'的行
df=df[df['设备名']== 'BJKDWYWLJK33'] #筛选'设备名'列中设备名为'BJKDWYWLJK33'的列
按内容筛选
df = df[df['flag'].str.contains("1")] #筛选出flag列包含‘1’的行,赋值给df
查看数据类型
print(type(df.groupby("date")['usage'].max())) #最后发现groupby后的结果是series类型的
批量操作:apply()函数
def convertRate(row):
if pd.isnull(row):
return 1.0
elif ':' in str(row):
rows = row.split(':')
return 1.0 - float(rows[1])/float(rows[0])
else:
return float(row)
#以上是要对每个数据进行的操作
def processData(df):
df['discount_rate'] = df['Discount_rate'].apply(convertRate)
#对‘Discount_rate’数组中的每一个数据进行convertRate函数的操作,返回的也是一列数组。
参考:https://blog.csdn.net/qq_39348113/article/details/82602259
批量操作:DataFrame的apply()方法和applymap()方法,以及python内置函数map()
我们经常会对DataFrame对象中的某些行或列,或者对DataFrame对象中的所有元素进行某种运算或操作,我们无需利用低效笨拙的循环,DataFrame给我们分别提供了相应的直接而简单的方法,apply()和applymap()。其中apply()方法是针对某些行或列进行操作的,而applymap()方法则是针对所有元素进行操作的。
参考:pandas中DataFrame的apply()方法和applymap()方法,以及python内置函数map()
Series类型常用操作
由索引和值组成,类似字典结构。
#初始化 Series 对象。其 data 和 index 参数,可以分别接收一个数组。
#index 参数如果不赋值,则会默认为数字索引,从0开始。
ss1 = pd.Series(['Cat', 'Dog', np.nan, 'Mouse'], index=['A', 'B', 'C', 'D'])
获取内容
类型为 <class ‘numpy.ndarray’>。
print(ss1.values) # ['Cat' 'Dog' nan 'Mouse']
print(type(ss1.values)) # <class 'numpy.ndarray'>
获取索引
类型为 <class ‘pandas.core.indexes.base.Index’>。
print(ss1.index) # Index(['A', 'B', 'C', 'D'], dtype='object')
print(type(ss1.index)) # <class 'pandas.core.indexes.base.Index'>
参考:Pandas 中 对Series 对象的创建、访问内容及索引、赋值方法的示例说明
根据值获取索引
series1[series1.values == 1].index
索引类型转列表:
#将ss1.index转化为list类型
list(ss1.index)
若series有多级索引,获取索引方法如下:
day_max = data.groupby(['date', 'hour'])["usage"].max()
day_max是series类型,结构如下:
date hour
2019-04-06 0 57
1 52
2 49
23 35
2019-04-07 0 36
1 28
2 35
输出索引:
print(day_max.index)
结果如下:
MultiIndex(levels=[[2019-04-06, 2019-04-07]],
labels=[[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ]],
names=['date', 'hour'])
此时若想获取其一级索引和二级索引的值,可用如下方式:
print("day_max.index.levels:\n", day_max.index.levels)
print("day_max.index.labels:\n", day_max.index.labels)
再例如
有如下结构‘
min_19 mean_19 max_20 min_20 mean_20 max_21 min_21
date
2019-06-11 8.0 13.416667 12.0 5.0 9.416667 24.0 5.0
2019-06-12 20.0 26.500000 26.0 18.0 20.083333 37.0 18.0
2019-06-13 NaN NaN NaN NaN NaN 26.0 10.0
2019-06-14 11.0 16.500000 24.0 8.0 17.333333 32.0 10.0
输出索引:
print("feature_1.index:\n",feature_1.index)
输出:
feature_1.index:
Index([2019-06-11, 2019-06-12, 2019-06-13, 2019-06-14, 2019-06-15, 2019-06-16,
2019-06-17, 2019-06-18, 2019-06-19, 2019-06-20, 2019-06-21, 2019-06-22],
dtype='object', name='date')
赋值给其他df
feature_1["date"] = feature_1.index
#或:feature_1["date"] = feature_1.date
填充Series缺失值:
cities={'Beijing':55000,'Shanghai':60000,'shenzhen':50000,'Hangzhou':20000,'Guangzhou':45000,'Suzhou':None}
apts=pd.Series(cities,name='income')
apts[apts.isnull()]=apts.mean() #将缺失位置赋值为中值
将series负值统一置0,正数不变
ss1 = pd.Series([0, -8, 7, -2], index=['A', 'B', 'C', 'D'])
输出ss1如下:
A 0
B -8
C 7
D -2
将所有负数变为0:
ss1[ss1.values<0]=0
输出ss1:
A 0
B 0
C 7
D 0
求Series平均值等统计值
avg_A = round(class_score[class_score['class'] == 'A']['score'].mean(), 2) #计算 A班的平均分
其他统计值参考:Pandas的Series统计函数
读写csv、txt、excel文件
读取csv文件
若文本中的分割符既有空格又有制表符(‘/t’),sep参数可用‘/s+’,匹配任何空格。
"""
import pandas as pd
dataset1 =pd.read_csv('data.csv',sep='\s+')
读取txt文件
若文本中的分割符既有空格又有制表符(‘/t’),sep参数可用‘/s+’,匹配任何空格。
import pandas as pd
data =pd.read_table('Z:/test.txt',header=None,encoding='gb2312',sep=',',index_col=0)
#如果在windows系统中读取时,提示找不到要读的文件,可在路径前加上r
data = pd.read_csv(r'2019-06-22.txt',header=None,sep=',')
sep=’,’:用逗号来分隔每行的数据
index_col=0:设置第1列数据作为index

使用pandas读取excel
写入CSV
df.to_csv('./ip_test.csv', index=False, header=None) # df是dataframe类型
#index=False,表示不写入行索引,否则最左边会多一列序号列
#header=None,表示不写入列名,默认写入列名
写入excel:
result.to_excel('.\Result1.xlsx') # result是dataframe类型
根据始末时间生成时间段
pd.date_range(start, end, freq) 生成一个时间段
freq参数由英文(M D H Min 。。。)、英文数字结合。D表示一天,M表示一月如20D表示20天,5M表示5个月。
#生成20171011-20171030
pd.date_range('20171011', '20171030',freq='5D')
DatetimeIndex(['2017-10-11', '2017-10-16', '2017-10-21', '2017-10-26'], dtype='datetime64[ns]', freq='5D')