前言
关于爬虫技术,我前段时间就想写一篇博客分享一下自己写基于python语言的爬虫经历,python语言写爬虫程序有天然的优势,因为python有许多关于爬取网页信息的第三方库,如果用python写爬虫程序会非常方便,下面就分享一下我做的一个用于爬取豆瓣电影top250榜单信息的python爬虫
我目前写过两个爬虫程序,一个是爬取中国大学排名网站的信息,另外一个就是今天我要介绍的豆瓣电影爬虫。所以目前我所掌握的关于爬虫的知识并不是太全面,只了解了一下python爬虫基础知识。目前我用过requests库,Beautifulsoup库,还有lxml库,这三个库对于初学python爬虫的朋友来说非常重要也非常常用,如果只是爬取简单静态网页信息,用这些库就完全足以。而对于一下大型的网站或者实时更新的数据爬取,则需要学习更加强大的爬虫库或者爬虫框架,比如Scrapy,Crawley等等,这里不再深入,有需求的朋友可以网上参考资料学习。
豆瓣电影top250榜单信息爬取
获取网页URL信息
url="https://movie.douban.com/top250?start=&filter="
kv={
'user-agent':'Mozilla/5.0'}
r=requests.get(url,headers=kv)
r.raise_for_status()
r.encoding = r.apparent_encoding #转化编码
demo=r.text
这里我们获取网页信息一般都采用requests库,requests库提供了get()函数可以获取相应URL网页信息,但是网页的编码可能并不是我们看得懂的编码方式,比如大多数支持UTF-8编码,所以我们需要转化编码形式,可以通过requests库支持的函数进行转化,这样我们就可以直观地看到网页的所有信息,如下图(部分信息截图):
信息筛选提取
这里运用的是Beautifulsoup(美味汤)库进行信息提取,美味汤的宗旨就是煮一锅汤,然后往里面加调料,这样就成了我们想要的美味汤。其实信息提取的方法还有很多,就像上面说的lxml库中XPath方法也是很好的提取信息方式,我第一次写豆瓣爬虫的时候就是用的lxml库的XPath提取信息,但是由于提取的信息是一种特殊的数据类型,而非字符串类型,后期数据规范化处理麻烦,所以我这次就用了最主流的Beautifulsoup库,它里面也提供了许多信息提取函数,非常方便,当然,如果有能力的朋友还可以用正则表达式对更复杂的数据进行筛选,因为正则表达式有那么一丢丢复杂,所以我就不介绍了,有需求的朋友可以自行网上了解,也是非常好用。
下图为部分提取信息的代码(可根据自己需求进行调整):
soup=BeautifulSoup(demo,'html.parser')
a=pd.DataFrame()
for link in soup.find_all('li'):
for l in link.find_all('span','title'):
# print(l.string)
b=str(l.string)
a=a.append([b],ignore_index=True)
for i in range(len(a)):
if('/' in str(a.loc[i])):
a=a.drop(index=i)
for lll in link.find_all('span','rating_num'):
c=str(lll.string)
a['评分']=[c]
# a=a.append([c],ignore_index=True)
for ll in link.find_all('span','inq'):
# print(ll.string)
d=str(ll.string)
a['评论']=[d]
a.to_csv('豆瓣爬虫2.0.csv',index=False, mode='a+', header=False) #提取的数据一行一行加入到CSV文件中
a=pd.DataFrame()
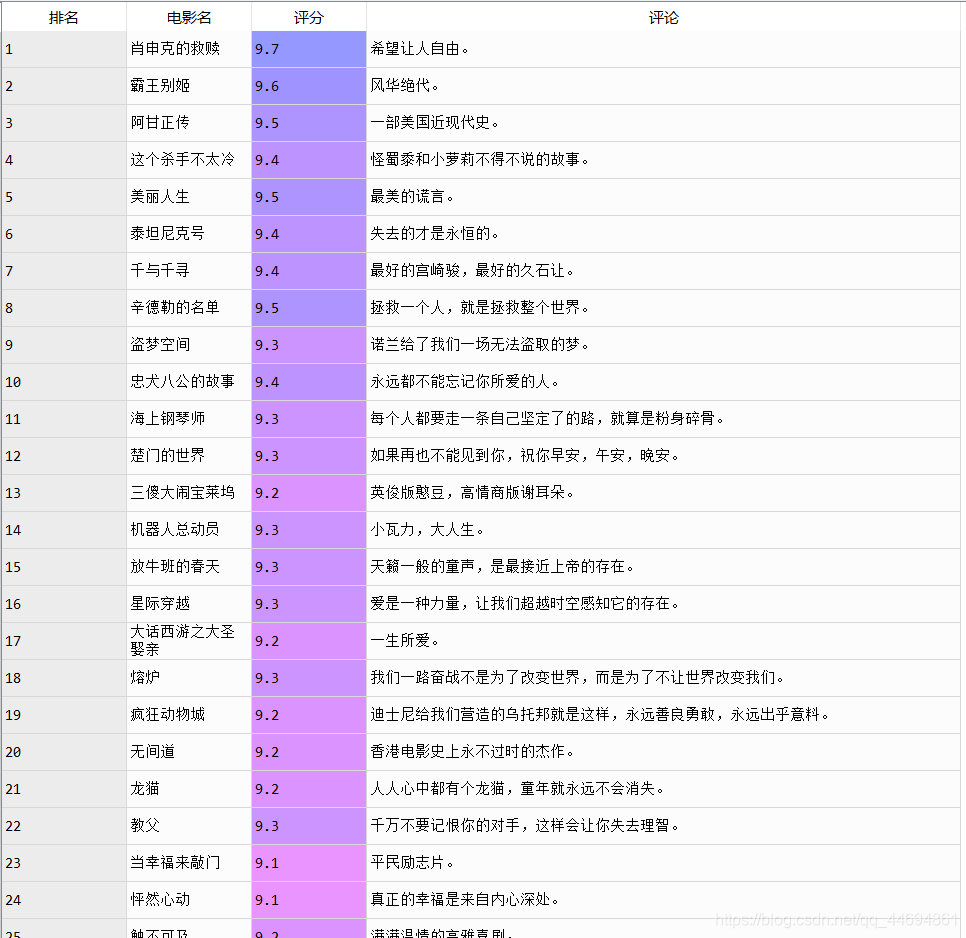
最终提取完成的效果如下图(部分电影):
后话
这就是一个基础的豆瓣电影榜单的python爬虫,其实并不复杂,主要就是要熟练运用爬虫库,后序可能我还会写更加大型的爬虫,逐步扩大爬取范围,当然大家要记住,不是每个网站都允许爬虫程序爬取信息的,爬虫也要遵循信息安全协议,切不可违反某些网站的隐私协议,希望大家正确运用爬虫进行学习。老规矩,大家多多在评论区给我留言,大家一起讨论,我是爱你们的玩物