FlatBuffers学习
1. 为什么使用FlatBuffers
使用FlatBuffers的原因很简单,那就是简单、效率高和便利。
为了传输数据,我们做了不少努力,研制出不少编解码方法,如:BER、PER、JSON、BSON、XML、HTML等。然而,不管使用何种方法,最终都是直接对数据进行操作,中间的编码和解码运算似乎是多余的。奥卡姆剃刀告诉我们:“如无必要,勿增实体”。在不增加实体的情况下,直接对数据进行操作,这就是FlatBuffers的开发目的。FlatBuffers仅仅增加了VTable和偏移量两个实体。
FlatBuffers很简单,使用起来一点都不难。首先定义好协议文件(schema),然后使用工具编译成源码文件,然后就可以直接调用源码的接口来操作数据。
FlatBuffers的效率很高。FlatBuffers数据在缓冲区内都是平整的,可以直接访问。
FlatBuffers使用起来很便利。协议文件设计好后就可以发布。任何人拿到这个文件都可以编译成源码来对数据进行操作。这对团队开发很有利。另外使用FlatBuffers不用担心协议文件设计不周到的问题,因为你可以随意往Table里面添加或者删除成员。
对序列化数据的访问不需要打包和拆包——它将序列化数据存储在缓存中,这些数据既可以存储在文件中,又可以通过网络原样传输,而没有任何解析开销;
内存效率和速度——访问数据时的唯一内存需求就是缓冲区,不需要额外的内存分配。 这里可查看详细的基准测试;
扩展性、灵活性——它支持的可选字段意味着不仅能获得很好的前向/后向兼容性(对于长生命周期的游戏来说尤其重要,因为不需要每个新版本都更新所有数据);
最小代码依赖——仅仅需要自动生成的少量代码和一个单一的头文件依赖,很容易集成到现有系统中。再次,看基准部分细节;
强类型设计——尽可能使错误出现在编译期,而不是等到运行期才手动检查和修正;
使用简单——生成的C++代码提供了简单的访问和构造接口;而且如果需要,通过一个可选功能可以用来在运行时高效解析Schema和类JSON格式的文本;
跨平台——支持C++11、Java,而不需要任何依赖库;在最新的gcc、clang、vs2010等编译器上工作良好
为什么不使用Protocol Buffers或者JSON
Protocol Buffers vs FlatBuffers
Protocol Buffers的确和FlatBuffers比较类似,但其主要区别在于FlatBuffers在访问数据前不需要解析/拆包这一步,而且Protocol Buffers没有可选的文本导入/导出功能(FlatBuffers可以直接根据Schema和json文本生成对应的二进制数据文件)。
Protocol Buffers使用一些特殊的数据结构来存储数据,从而在解析数据时需要花费额外的时间。比如,使用varints来存储整型数,varints是一种使用一个或多个字节来序列化整型数的方法,越小的数占用的字节数就越少。同时,代表一个数字的多个字节采用little endian的方式来存储。这就导致在解析数据时,需要判断哪几个字节是表示这个字段的,并进行其他的数学变换来还原出原始数据。
关于protocal buffers具体的数据编码方式,可以参考google开发者网站以及IBM技术博客。
与之相对,FlatBuffers可以直接根据起始位置+偏移量直接获取到数据,无解析过程,效率更高,而伴随的副作用是FlatBuffers需要占用相对更多的空间,因为Protocol Buffers的编码在一定程度上压缩了数据。
网上有人进行了性能对比试验,结果如下图:
JSON vs FlatBuffers
JSON是非常可读的,而且当和动态类型语言(如JavaScript)一起使用时非常方便。然而在静态类型语言中序列化数据时,JSON不但具有运行效率低的明显缺点,而且会让你写更多的代码来访问数据(这个与直觉相反)。
哪些项目使用了FlatBuffers
Cocos2d-x, the #1 open source mobile game engine, uses it to serialize all their game data.
Facebook uses it for client-server communication in their Android app. They have a nice article explaining how it speeds up loading their posts.
Fun Propulsion Labs at Google uses it extensively in all their libraries and games.
FlatBuffers原理
假设我们有一个person类,定义如下:
class Person {
String name;
int friendshipStatus;
Person spouse;
List<Person>friends;
}
其中的spouse(配偶)和friends字段页包含了person对象,这样就形成了一个树结构。
每个对象都被分成两部分:中心点左边的元数据部分(或者叫vtable),和中心点右边的真实数据部分。
每个字段都对应vtable中的一个槽(slot),它存储了那个字段的真实数据的偏移量。例如,John的vtable的第一个槽的值是1,表明John的名字被存储在John的中心点右边的一个字节的位置上。
如果一个字段是一个对象,那么它在vtable中的偏移量会指向子对象的中心点(pivot point)。比如,John的vtable中第三个槽指向Mary的中心点。
要表明某个字段现在没有数据,可以在vtable对应的槽中使用偏移量0来标注。
要了解更复杂的关于FlatBuffers字段修改的实现原理,可以查看facebook的文档中的“Mutation on FlatBuffers”部分。
简明使用步骤
编写一个用来定义你想序列化的数据的schema文件(又称IDL),数据类型可以是各种大小的int、float,或者是string、array,或者另一对象的引用,甚至是对象集合。各个数据属性都是可选的,且可以设置默认值,所以不必要为每个对象实例都去呈现这些字段。
使用FlatBuffer编译器flatc生成C++头文件或者Java类,生成的代码里额外提供了访问、构造序列化数据的辅助类。生成的代码仅仅依赖flatbuffers.h;
使用FlatBufferBuilder类构造一个二进制buffer。你可以向这个buffer里循环添加各种对象,而且很简单,就是一个单一函数调用;
保存或者发送该buffer;
当再次读取该buffer时,你可以得到这个buffer根对象的指针,然后就可以简单的就地读取数据内容。
1.下载编译FlatBuffer
下载地址:https://github.com/fanyun-01/flatbuffers
2.编译FlatBuffer

解压flatbuffers-master.zip文件文件,使用VS2015打开flatbuffers-master\build\VS2015\FlatBuffers.sln文件进行编译。编译后生成的文件如下:
(1).flatc.exe - 编译schema文件、生成代码
(2).flatsamplebinary.exe - 测试程序,将二进制转换为C++对象
(3).flatsampletext.exe - 测试程序,将json转换为C++对象
(4).flattests.exe - 测试flatbuffers
3.编写test.fbs文件
namespace TestApp;
struct KV
{
key: ulong;
value: double;
}
table TestObj
{
id: ulong;
name: string;
flag: ubyte = 0;
list: [ulong];
kv: KV;
}
root_type TestObj;
4.然后利用"flatc.exe"生成.h文件,并使用此.h文件
int _tmain(int argc, _TCHAR* argv[])
{
FlatBufferBuilder fbb;
// 设置数据
std::vector<uint64_t> v = { 1, 2, 3, 4, 5 };
auto kv = KV(1, 1.0);
auto name = fbb.CreateString("123");
auto vec = fbb.CreateVector(v);
TestObjBuilder builder(fbb);
builder.add_id(100);
builder.add_name(name);
builder.add_flag(1);
builder.add_list(vec);
builder.add_kv(&kv);
fbb.Finish(builder.Finish());
// 注册
FlatBufferJsonFactory::Instance().Register<TestApp::TestObj>("E:\\c++\\use_flat_buffers\\use_flat_buffers\\test.fbs");
std::string json = FlatBufferJsonFactory::Instance().toJson<TestApp::TestObj>(fbb.GetBufferPointer());
std::string buffer = FlatBufferJsonFactory::Instance().parserJson<TestApp::TestObj>(json);
const TestApp::TestObj* obj = GetTestObj(buffer.c_str());
const char* names = obj->name()->c_str();
return 0;
}5.json与C++对象相互转换
FlatBuffer的测试程序中有json与c++对象相互转换的例子,但是不够方便,在这里我们可以封装一下。
FlatBufferJsonFactory.h
#include "TypeBind.h" // C++模板之类型与数据绑定"
class FlatBufferJsonFactory {
private:
struct ParserInfo {
ParserInfo(const std::string& _path)
: path(_path), parser(nullptr)
{}
std::string path; // fbs文件路径
flatbuffers::Parser* parser; // flatbuffers解析器
};
public:
// 将json字符串转换为了对象缓冲区
template<class T>
std::string parserJson(const std::string& s) {
const ParserInfo& info = getParser<T>();
info.parser->Parse(s.c_str(), nullptr);
const size_t size = info.parser->builder_.GetSize();
const char* ptr = (const char*)info.parser->builder_.GetBufferPointer();
std::string buffer(ptr, ptr + size);
return buffer;
}
// 将对象缓存转换为json字符串
template<class T>
std::string toJson(const void* buffer) {
std::string json;
const ParserInfo& info = getParser<T>();
flatbuffers::GeneratorOptions options;
options.strict_json = true;
GenerateText(*info.parser, buffer, options, &json);
return json;
}
// 注册
template<class T>
void Register(const std::string& path) {
ParserInfo info(path);
m_map.bind<T>(info);
}
template<class T>
const ParserInfo& getParser() {
ParserInfo& info = m_map.find<T>();
if (!info.parser) {
std::string buf;
flatbuffers::LoadFile(info.path.c_str(), false, &buf);
flatbuffers::Parser* parser = new flatbuffers::Parser();
bool ret = parser->Parse(buf.c_str(), nullptr);
info.parser = parser;
}
return info;
}
static FlatBufferJsonFactory& Instance() {
static FlatBufferJsonFactory* instance = nullptr;
if (!instance)
instance = new FlatBufferJsonFactory();
return *instance;
}
private:
FlatBufferJsonFactory() {}
TypeBind<ParserInfo> m_map;
};2. 为什么不使用FlatBuffers
因为我不关心效率,所以我不使用FlatBuffers。但是能省点CPU资源也没什么不好,至少可以多跑几个服务。
FlatBuffers传输的数据较大,所以我不使用FlatBuffers。其实可以对数据进行压缩再传输。
因为目前开发的项目都使用XML和HTTP,所以我不使用FlatBuffers。建议能在新的模块中使用FlatBuffers。
因为打包后的FlatBuffers中的矢量数据不能随意修改,感觉不爽,所以不使用。对于一般的应用来说,打完包后就会立即发送,很少会修改数据的。
因为目前FlatBuffers的union类型不支持大于256个类型,然而项目中的union将包含超过256个类型的数据结构,所以我不使用FlatBuffers。对于这个问题,可以使用二级或者多级union来解决,即由多个union来实现,如二级union可以至少支持65536个类型。
FlatBuffers传输的数据没有JSON、XML和HTML那么直观,所以不想使用。对于这个问题,可以在收包程序进行LOG来弥补,可以通过查看LOG来获知传输的内容。另外,由于不是明文传输,所以一般的人,如果没有协议文件,即使截取到数据包还得需要花一定的力气才能解开,有利于保密。
FlatBuffers目前没有办法生成C源码,我们的项目使用的都是C源码。对于这个问题,我相信不久就会有版本能生成C源码。
3. FlatBuffers详解
FlatBuffers其实就是一个保存了一系列标量和矢量的缓冲区。这个缓冲区中的标量和矢量可以被直接访问。
缓冲区的数据一旦构造成功,里面的矢量数据一般不能变更,除非矢量的长度不大于构造时的长度,且矢量保存的不是偏移量,否则会产生错误。
3.1. 标量
所有的整形变量(8位~64位)和浮点变量均为标量。标量的特点是长度固定,字节序列为LittleEndian,这和大部分CPU的一样,以加快访问速度。
FlatBuffers中的偏移量也是标量,但是在构造后不能变更。
Struct结构也可以当做是标量来看待。
3.2. 矢量
字符串和数组是矢量。字符串是以'\0'结尾。矢量的开头必须是一个32位的长度,用来指明矢量的长度,这个长度不包括'\0'和长度本身所占的空间。

图 1
如图1所示,STRING和VECTOR都是矢量,唯一的区别是STRING包含一个'\0'结束符合。VECTOR SIZE保存的是VECTOR ELEMENTS的长度,单位是字节。
如果VECTOR ELEMENTS是标量或者STRUCT,那么其中保存的内容就是其数组中的内容;如果是TABLE,那么保存的就是一个偏移量数组,这些偏移量为32位,指向TABLE OBJECT。
3.3. 数据结构
3.3.1. Struct
Struct类型的数据结构是不可以更改的结构。当结构定义好,结构的成员、位置和大小就会固定,不能变更,否则所有的程序都要重新编译和升级。Struct的优点是访问速度快,占用内存少。
3.3.2. Table
Table类型可以随意增加和删除成员,是一个很灵活的类型。当要删除一个成员时,你把它指定为deprecated即可(这个成员必须保存在成员列表内,不能删除)。
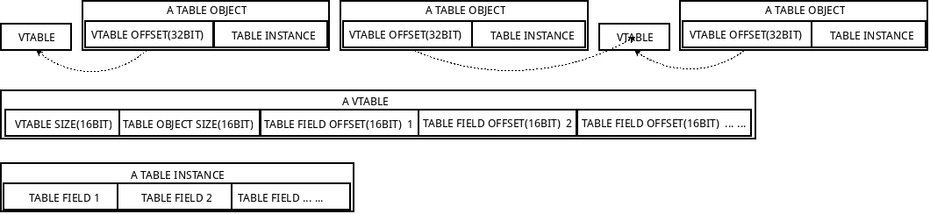
图 2
如图2所示,一个VTABLE可以为多个TABLE OBJECT提供描述信息,每个TABLE OBJECT必须包含一个32位的TABLE OFFSET,指定哪个VTABLE描述它的字段信息。
每个VTABLE都有一个16位的VTABLE SIZE,用来记录本身的大小(包括VTABLE SIZE);TABLE OBJECT SIZE用来记录TABLE OBJECT的大小(包括VTABLE OFFSET这4个字节);TABLE FIELD OFFSET用来记录TABLE INSTANCE内的字段相对TABLE OBJECT的偏移量,即TABLE INSTANCE的第一个字段偏移量必须为4(因为VTABLE OFFSET为32位,占了4个字节)。
每个TABLE INSTANCE保存一系列字段FIELD,这些FIELD可以是普通标量或者struct,也可以是32位的偏移量,指向其它TABLE或者矢量。
3.3.3. ROOT TYPE

图 3
如图3所示,ROOT OFFSET是一个32位的偏移量,指向ROOT DATA;ROOT DATA为封包内容。FILE ID为可选内容,可以不设置,可以用作这个封包的ID,注意无'\0'结尾,可以在协议文件中使用file_identifier来指定。
ROOT DATA为整个封包的数据部分,然而ROOT OFFSET未必指向ROOT DATA的开头,它是指向顶层TABLE的TABLE OBJECT,而不是指向VTABLE。因此,即使不填FILE ID,ROOT DATA的值也可能不为0。
3.3.4. Union
联合类型是一个重要的类型,是封包分支的重要方法。

图4
如图4所示,每个union有两个部分组成,一个部分是TYPE,另外一个是TABLE偏移量。
因为TYPE只要8位,所以联合类型里面最多只能包含256个TABLE类型,否则会出问题。如果想支持大于256个类型,那么必须通过union+table+union这种方法来扩充,如:
// 第二层union
table T2_1_t
{ // 分支1
A1:int;
}
table T2_2_t
{ // 分支2
A2:int;
}
union U2_1_t
{
T2_1_t,
T2_2_t
}
table T2_3_t
{ // 分支3
A1:int;
}
table T2_4_t
{ // 分支4
A2:int;
}
union U2_2_t
{
T2_3_t,
T2_4_t
}
// 第一层union
table T1_1_t
{
u:U2_1_t ( id: 1 ); // 注意,由于union的类型占一个id,所以这里是1,不是0;0已经默认分配给type了
}
table T1_2_t
{
u:U2_2_t ( id: 1 ); // 注意,由于union的类型占一个id,所以这里是1,不是0;0已经默认分配给type了
}
union U1_1_t
{ //可以至少支持多达256*256=65536个消息分支
T1_1_t,
T1_2_t
}
// 应用,这个Table可以至少保存多达256*256=65536种内容
table T_t
{
u:U1_1_t ( id: 1 );// 注意,由于union的类型占一个id,所以这里是1,不是0;0已经默认分配给type了
}4. 总结
FlatBuffers构造的数据总的来说是只要两种,即固定长度数据和可变长度数据,或者说是标量和矢量。可以认为struct也是标量,因为struct的大小也是固定的。在构造数据时,所有的标量都是直接写到缓冲区去的,所有的矢量需要先写到缓冲区,然后获得偏移量(32位),然后再把偏移量写到适当的结构中,每个矢量都离不开一个偏移量。
FlatBuffers和ProtoBuffers都是谷歌开发的开源产品。相对于ProtoBuffers已经在谷歌内部得到广泛的应用,FlatBuffers却是一个新生的事物。然而,FlatBuffers的反序列化速度是ProtoBuffers的百倍,相信将会得到越来越多的应用。