决定系数(coefficient of determination),有的教材上翻译为判定系数,也称为拟合优度。
表征依变数Y的变异中有多少百分比,可由控制的自变数X来解释.
相关系数(coefficient of correlation)的平方即为决定系数。它与相关系数的区别在于除掉|R|=0和1情况,

由于R2<R,可以防止对相关系数所表示的相关做夸张的解释。
决定系数:在Y的总平方和中,由X引起的平方和所占的比例,记为R(R的平方)
决定系数的大小决定了相关的密切程度。
当R越接近1时,表示相关的方程式参考价值越高;相反,越接近0时,表示参考价值越低。这是在一元回归分析中的情况。但从本质上说决定系数和回归系数没有关系,就像标准差和标准误差在本质上没有关系一样。
在多元回归分析中,决定系数是通径系数的平方。
表达式:R=SSE/SST=1-SSR/SST
其中:SST=SSR+SSE,SST (sum of squares for total)为总平方和,SSReg (sum of squares for regression为回归平方和,SSE (sum of squares for error) 为残差平方和。
注:(不同书命名不同)
回归平方和:SSR(Sum of Squares for regression) = ESS (explained sum of squares)
残差平方和:SSE(Sum of Squares for Error) = RSS (residual sum of squares)
总离差平方和:SST(Sum of Squares for total) = TSS(total sum of squares)
SSE+SSR=SST RSS+ESS=TSS
意义:拟合优度越大,自变量对因变量的解释程度越高,自变量引起的变动占总变动的百分比高。观察点在回归直线附近越密集。
取值范围:0-1.
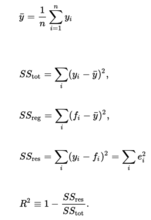
折叠作用
折叠用
例
折区别
判定系数和相关系数的区别
判定系数 |
相关系数 |
就模型而言 |
就两个变量而言 |
说明解释变量对因变量的解释程度 |
度量两个变量线性依存程度。 |
度量不对称的因果关系 |
度量不含因果关系的对称相关关系 |
取值:[0,1] |
取值:[-1,1] |