0 概要
如果不懂迁移学习的概念——> 什么是迁移学习 (Transfer Learning)?
本篇文章的预训练模型是从keras之分类数字图片(二)内获取的。
要求:
- 安装keras库
- 能用gpu跑项目,如果不能,解决方案——>Google colab使用之手把手教学
- 以上两点要求无法满足,你我就改日再见吧
“食用”方式
- 先“食用” keras之分类数字图片(二) 再观看这篇文章,效果更佳(不是捆绑消费)
- 或者通过网盘获取 h5 模型文件,直接看这篇文章,效果略差
- h5 模型文件获取方式:百度网盘 提取码:gedt

1 迁移学习
步骤:
- 载入模型,并了解该模型的基本信息
- 将该模型的网络层全部冻结
- 原模型选择训练层的两种方式
- 自定义自己的网络模型
- 加载数据并在新的模型基础上训练
1.1 模型基本信息
# 1、载入模型,并了解该模型的基本信息
# 由于原模型做的是识别手写数字图片的一个10分类任务,所以原模型最终的全连接层有10个神经元
from keras import models
model = models.load_model("dentify_writtern_number_20210129_1209/epoch:10-loss:0.2525.h5")
from keras.utils import plot_model
for (i,layer) in enumerate(model.layers):
print (i,layer)
print (model.summary())
# plot_model(model,show_shapes="true")
运行效果:这个时候载入的模型,既包括网络结构也包括已经训练好的参数

1.2 冻结原模型
# 2、将该模型的网络层全部冻结
for layer in model.layers:
layer.trainable = False
print (model.summary())
运行效果:将载入模型的参数设置为 “不训练”,之后训练模型的时候,这些参数就不会变化

1.3 选择训练层
关于选择 载入模型 的哪几个训练层,以下讲解了两种方式:
# 3、原模型选择训练层的两种方式
from keras.models import Model
from keras.models import Sequential
# 第一种
# 选取原模型第一层至倒数第二层
model1 = Model(inputs=model.input, outputs=model.layers[-2].output)
# 第二种
# 选取原模型第一层至倒数第二层
model2 = Sequential()
for layer in model.layers[:-1]: # 跳过最后一层
model2.add(layer)
# 我尝试过使用这种方式model2.layers.pop()来删除最后一层训练层,毕竟model2.layers是list数据类型,但是无效
# 所以各位掌握以上两种方式就足够了
print (model.summary())
print (model1.summary())
print (model2.summary())
运行效果:可以相互比对下,更好理解


 而且以上两种方式生成的新模型,参数和原模型的参数是保持一致的。
而且以上两种方式生成的新模型,参数和原模型的参数是保持一致的。
# 看以下输出就知道
w1,b1 = model.layers[1].weights
print (b1)
w,b = model1.layers[2].weights
print (b)
w2,b2 = model2.layers[1].weights
print (b2)
运行效果:

1.4 自定义网络模型
- 由于原模型做的是识别手写数字图片的一个10分类任务,所以原模型最终的全连接层有10个神经元
- 这个Demo目的是掌握迁移学习使用,所以我将该模型的最后的10个神经元的全连接层删除,换成自定义的500个神经元后面再接10个神经元
# 4、自定义自己的网络模型
from keras.layers import Dense
model2.add(Dense(500,activation="relu"))
model2.add(Dense(10,activation="softmax"))
model2.compile(loss="categorical_crossentropy",optimizer="sgd",metrics="acc")
print (model2.summary())
运行效果:

1.5 训练模型
- 先加载数据
- 进行数据预处理
- 再训练模型
- 与 keras之分类数字图片(二)处理数据一致。
# 5、加载数据并在新的模型基础上训练
from keras.datasets import mnist
from keras.utils import np_utils
import numpy as np
# 5.1 加载mnist数据集
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# train中有6万张手写数字图片,test中有1万张手写数字图片
print (x_train.shape)
print (x_test.shape)
# 5.2 数据预处理
# 进行one-hot(独热编码)
# 进行one-hot编码是因为损失函数需要使用交叉嫡函数(cross_entropy)
# 交叉嫡函数详解 https://zhuanlan.zhihu.com/p/35709485
y_train = np_utils.to_categorical(y_train,10)
y_test = np_utils.to_categorical(y_test,10)
# 由于下载数据得到是uint类型,在神经网络无法进行合理运算,在这里将其转化为float32类型
x_train = x_train.astype(np.float32)
x_test = x_test.astype(np.float32)
# 由于conv2D函数需要这四维的图片数据,这里就reshape维度
x_train = x_train.reshape([-1,28,28,1])
x_test = x_test.reshape([-1,28,28,1])
运行效果:

# 由于新增加的Dense层没有训练,其结果也是极差的
eva = model2.evaluate(x_test,y_test,batch_size=1000)
print (eva)
运行效果:
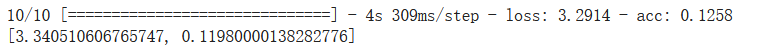
# 开始对自定义的Dense训练
model2.fit(x_train,y_train,batch_size=128,epochs=20)
运行效果:
- 由于在原模型的基础上,做出了一定的改动,现在模型仍保有原模型的一定特征。
- 在这个基础上,再进行训练,效果就会更好。
- 一般来说,手写数字项目第一个epoch的准确度大概是百分之10到20。
- 而这个第一个epoch就有将近百分之90

# 使用测试集合检验模型性能
loss = model2.evaluate(x_test,y_test)
print (loss)
运行效果:准确度大概百分之98,哟西,不错!!!

2 源代码汇总
# 1、载入模型的基本信息
# 由于原模型做的是识别手写数字图片的一个10分类任务,所以原模型最终的全连接层有10个神经元
from keras import models
model = models.load_model("dentify_writtern_number_20210129_1209/epoch:10-loss:0.2525.h5")
from keras.utils import plot_model
for (i,layer) in enumerate(model.layers):
print (i,layer)
print (model.summary())
# plot_model(model,show_shapes="true")
# 2、将该模型的网络层全部冻结
for layer in model.layers:
layer.trainable = False
print (model.summary())
# 3、原模型选择训练层的两种方式
from keras.models import Model
from keras.models import Sequential
# 第一种
model1 = Model(inputs=model.input, outputs=model.layers[-2].output)
# 第二种
model2 = Sequential()
for layer in model.layers[:-1]: # 跳过最后一层
model2.add(layer)
# 我尝试过使用这种方式model2.layers.pop()来删除最后一层训练层,毕竟model2.layers是list数据类型,但是无效
# 所以各位掌握以上两种方式就足够了
print (model.summary())
print (model1.summary())
print (model2.summary())
# 而且以上两种方式生成的新模型,参数和原模型是保持一致的
# 看以下输出就知道
w1,b1 = model.layers[1].weights
print (b1)
w,b = model1.layers[2].weights
print (b)
w2,b2 = model2.layers[1].weights
print (b2)
# 4、自定义自己的网络模型
# 由于原模型做的是识别手写数字图片的一个10分类任务,所以原模型最终的全连接层有10个神经元
# 这个Demo目的是掌握迁移学习使用,所以我将该模型的最后的10个神经元的全连接层删除,换成自定义的500个神经元后面再接10个神经元
from keras.layers import Dense
model2.add(Dense(500,activation="relu"))
model2.add(Dense(10,activation="softmax"))
model2.compile(loss="categorical_crossentropy",optimizer="sgd",metrics="acc")
print (model2.summary())
# 5、加载数据并在新的模型基础上训练
from keras.datasets import mnist
from keras.utils import np_utils
import numpy as np
# 加载mnist数据集
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# train中有6万张手写数字图片,test中有1万张手写数字图片
print (x_train.shape)
print (x_test.shape)
# 进行one-hot(独热编码)
# 进行one-hot编码是因为损失函数需要使用交叉嫡函数(cross_entropy)
# 交叉嫡函数详解 https://zhuanlan.zhihu.com/p/35709485
y_train = np_utils.to_categorical(y_train,10)
y_test = np_utils.to_categorical(y_test,10)
# 由于下载数据得到是uint类型,在神经网络无法进行合理运算,在这里将其转化为float32类型
x_train = x_train.astype(np.float32)
x_test = x_test.astype(np.float32)
# 由于conv2D函数需要这四维的图片数据,这里就reshape维度
x_train = x_train.reshape([-1,28,28,1])
x_test = x_test.reshape([-1,28,28,1])
# 由于新增加的Dense层没有训练,其结果也是极差的
eva = model2.evaluate(x_test,y_test,batch_size=1000)
print (eva)
# 开始对自定义的Dense训练
model2.fit(x_train,y_train,batch_size=128,epochs=20)
# 使用测试集合检验模型性能
loss = model2.evaluate(x_test,y_test)
print (loss)
如有疑惑,以下评论区留言。力所能及,必答之。