为什么LinkedIn放弃MySQL slowlog,转用基于网络层的慢查询分析器?
导读:对互联网应用来说,后端需要应付海量请求。如何在这些请求中快速定位出对数据库造成最大影响的部分,是业界难题。如何对线上查询进行科学的分析而不引起性能降低,也是很有技术含量的事情。本文是 LinkedIn 对以上问题的答案。
介绍
LinkedIn 大量使用MySQL,公司内部 500 多个服务依赖于MySQL。 为了方便管理以及提高资源利用率,我们使用多租户架构模式。 然而这种模式的一个主要缺点是,来自一个应用程序的查询可能会影响到其他应用程序。
虽然我们已经通过调整 InnoDB,操作系统和 MySQL 服务器配置来优化数据库,但我们无法控制大家的 schema 和查询。 我们希望通过分析和优化查询来解决这一问题。 为了做到这一点,我们拿到数据库上所有查询的完整信息。
为什么我们需要查询分析器?
为了更好地了解运行时应用程序动态,我们需要深入研究几百个应用程序调用的 SQL 查询,了解其性能特征,然后进一步优化调整它们。
考虑到性能问题,我们没有使用慢查询日志。 我们可以为查询时间设置一个阈值,然后将所有跨越阈值的查询记录在一个文件中,用于事后进行分析。 这种方法的缺点是它无法捕获所有的查询。 如果将阈值设置为 0 可以捕获所有查询,但实际是行不通的,数百万次查询记录进文件会导致海量 IO,并大大降低系统吞吐量。 所以使用慢查询日志是完全不行的。
我们考虑的下一个选项是 MySQL Performance Schema,可以用来在低水平监控 MySQL 服务器运行状态(从MySQL 5.5.3开始提供)。 它提供了一种在运行时检查服务器的内部执行情况的方法。 然而,使用此方法的主要缺点是启用或禁用 performance_schema 需要重新启动数据库。您可以尝试启用 Performance Schema,然后关闭所有调用者,这会导致增加大约 8% 的开销; 如果您启用所有的调用者,会增加大约 20-25% 的开销。 分析 Performance Schema 也非常复杂,为了克服这个问题,MySQL 从 MySQL 5.7.7 版本引入了sys schema。 但是为了查看历史数据,我们仍然需要将数据从 Performance Schema 转储到其他服务器。
因为这两种方法都不能满足我们的所有需求,所以我们构建了运行在网络层的查询分析器,以最小化开销并有效度量所有查询。
查询分析器如何工作?
查询分析器有三个组件:
1)在数据库服务器上运行的 agent。
2)存储查询信息的中心服务器。
3)中心服务器上的 UI,用于显示 SQL 分析结果。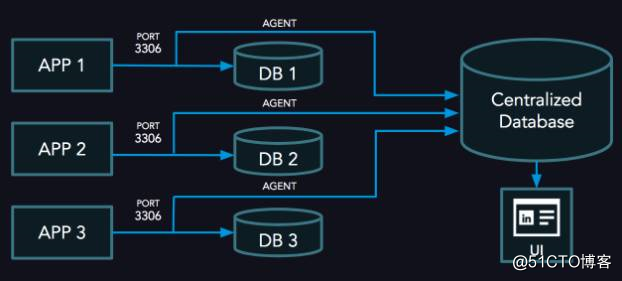
查询分析器的高级体系结构
Agent 代理
Agent 代理是在 MySQL 服务器节点上运行的服务。 它使用 raw socket 捕获 TCP 数据包,然后使用 MySQL 协议从数据包流解码数据包并构建查询。 然后,代理通过记录查询到达端口的时间和发送第一个数据包的时间(数据库响应后)计算查询响应时间。
查询响应时间是第一个分组进入的时间和发送第一个响应分组的时间之差。 然后将查询发送到 go routine,以标识查询的指纹(我们使用 Percona GO 软件包 [1])。 指纹对应数据清洗后的查询。 使用指纹哈希值作为查询的 key。 我们可以通过其哈希值唯一地标识每个查询。
代理将查询的哈希值,总响应时间,计数,用户和数据库名称存储在哈希表中。 如果查询有另一个相同哈希值,代理只需追加计数,并将查询时间添加到总响应时间。 此外,代理还在另一个 hashmap 中维护元数据信息,其中包括查询哈希值和指纹,最大时间,最小时间等。
代理收集一段时间查询信息,然后将信息(查询哈希值,sum_query_time,count 等)发送到中心主机,然后重置计数器。 元数据信息仅在其中发生变化时发送,如出现了新的查询或查询出现了新的最小值或最大值。 代理仅仅使用几 MB 的内存来管理这些数据结构,用于发送查询信息的网络带宽可以忽略不计。
表1:查询指纹示例
询问 指纹
查询A SELECT * FROM table WHERE value1 ='abc' SELECT * FROM table WHEREvalue1 ='?'
查询B SELECT * FROM table WHEREvalue1 ='abc'AND value2 = 430 SELECT * FROM table WHEREvalue1 ='?'AND value2 =?
查询C SELECT * FROM table WHEREvalue1 ='xyz'AND value2 = 123 SELECT * FROM table WHEREvalue1 ='?'AND value2 =?
查询D SELECT * FROM table WHERE VALUES IN(1,2,3) SELECT * FROM table WHERE VALUES IN(?+)请注意,A 和 B 的指纹不同,但 B 和 C 的指纹相同。
表2:hashmap 示例
查询哈希(KEY) 查询时间 计数 用户 DB
3C074D8459FDDCE3 6ms(1ms + 2ms + 3ms) 3 APP1 DB1
B414D9DF79E10545 9s(1s + 3s + 4s + 1s) 4 APP2 DB2
791C5370A1021F19 12ms(5ms + 7ms) 2 APP3 DB3表3:元数据hashmap 示例
查询哈希 指纹 第一次出现 最大时间的查询 最小时间 最大时间
3C074D8459FDDCE3 SELECT * FROM T1 WHERE a>? 1个月 SELECT * FROM T1 WHERE a> 0 1毫秒 为3ms
B414D9DF79E10545 SELECT * FROM T2 WHERE b =? 1天 SELECT * FROM T2 WHERE b = 430 1秒 5S
791C5370A1021F19 SELECT * FROM T3 WHERE c <? 1小时 SELECT * FROM T3 WHERE c <1000000 5ms的 7毫秒UI
用于显示分析的 UI 运行在中心服务器上。 用户可以选择要查看查询的主机名和时间范围,以显示在该时间内运行的每个查询的统计信息,您可以单击任意查询查看查询趋势图。
有趣的方面是查询负载百分比,这是查询在此期间在服务器上运行的查询总数导致的负载。 例如,假设有3个查询。
- 查询 #1 每次花费 2 秒钟,执行 100 次。 它造成的负载为 2 * 100 = 200。
- 查询 #2 每次花费 0.1 毫秒,执行 10M 次。 其造成的负载为 0.0001 * 10,000,000 = 1000。
- 查询 #3 每次花费 10 毫秒,执行了 1M 次。 它造成的负载为 0.01 * 1,000,000 = 10000。
因此,在该间隔期间服务器上的总负载为 200 + 1000 + 10000 = 11200。 每个查询的负载百分比如下。
- 查询#1 为 200/11200 * 100 = 1.78%
- 查询#2 为 1000/11200 * 100 = 8.93%
- 查询#3 为 10000/11200 * 100 = 89.29%
请注意,用户应该查看的查询是 Query#3,因为它导致了 89.29% 的负载,即使它每次执行只需要 10 毫秒。
UI 如下图所示。 出于安全考虑,主机名和表名被屏蔽。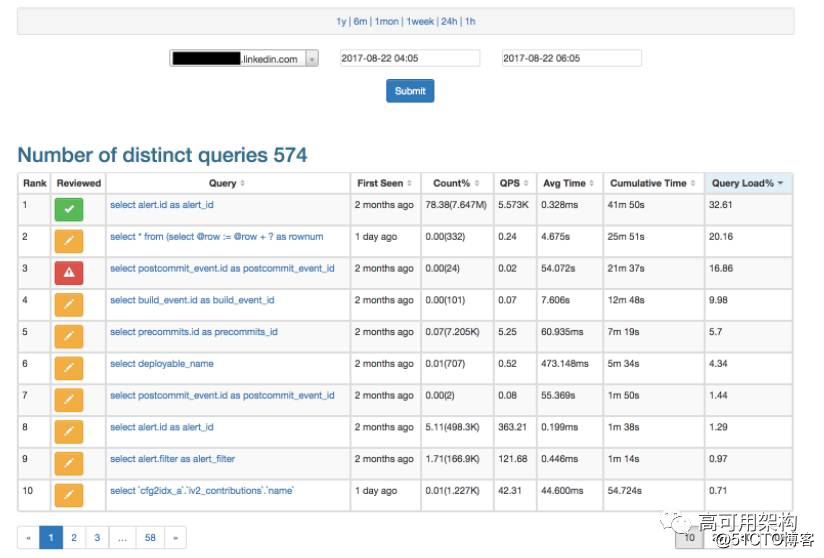
查询分析器UI显示所有不同的查询
单击任意查询可以显示查询的趋势和更多信息。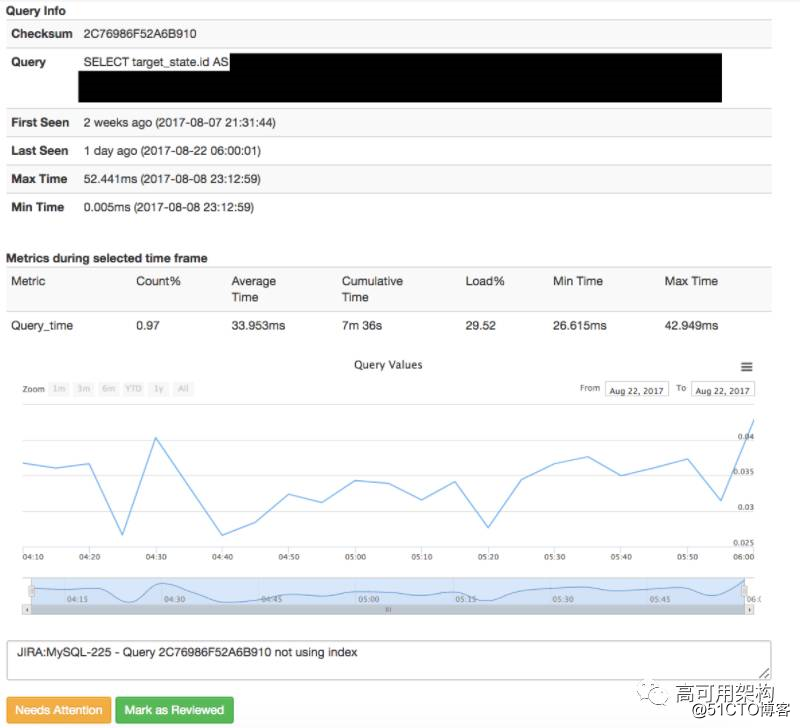
图表显示查询趋势
性能
为了显示对吞吐量(每秒事务)的影响,我们在使用 Intel(R)Xeon(R)CPU E5-2620 0 @ 2.00GHz - 12 核心 CPU 的机器上运行 MySQL 5.6.29-76.2-log Percona 服务器(GPL)。
运行基准测试,之后不断增加 sysbench 线程并测量其性能。 我们发现,在达到 128 个并发线程之前,查询分析器不会影响吞吐量。 对于 256 个线程的情况,我们观察到每秒事务下降了 5%,但这仍然优于 Perfomance Schema(吞吐量下降了 10%)。
在我们的测试中,查询分析器占用不到 1% 的 CPU,而当超过 128 个线程运行时,这个峰值上升到 5%,这个数量仍然可以忽略不计。 请注意,线程数意味着 MySQL 内的并发查询数,其中不包括休眠连接。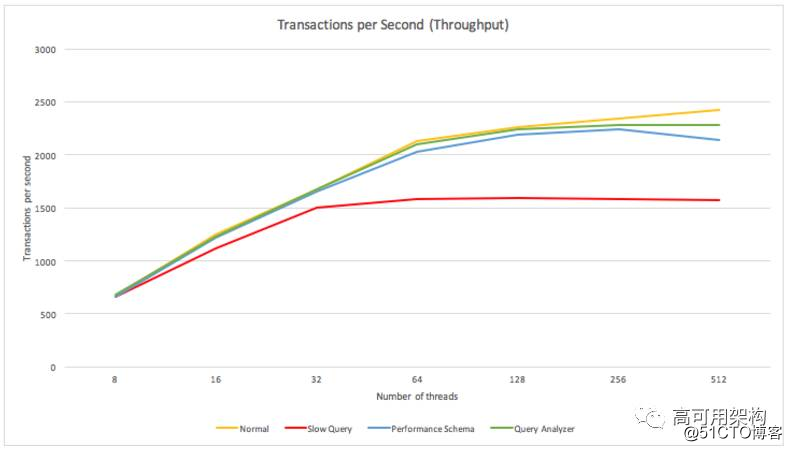
使用各种工具对生产量进行基准测试
使用各种工具对CPU利用率进行基准测试
指标收集
对于查询分析器的原始版本,我们使用 MySQL 来存储数据(基本上是时间序列数据)。 有两个表:query_history 和 query_info。
query_history 是从查询 hashmap 保存信息的位置。 该表具有以下列:hostname, checksum, timestamp, count, query time, user, and db。 主键是(hostname, checksum, timestamp),按 timestamp 进行范围分区,通过 hostname 上的键做子分区。 在(hostname, timestamp, querytime, count)和 checksum 上有索引。
query_info 表用于保存有关查询元数据的信息。 它具有以下列:hostname, checksum, fingerprint, sample, first_seen, mintime, mintime_at, maxtime, maxtime_at, is_reviewed, reviewed_by, reviewed_on, comments。 (hostname, checksum)作为主键并且 checksum 上有索引。
到目前为止,我们还没有遇到任何问题。 偶尔绘制长时间范围的查询趋势图时,会有一些延迟。 为了克服这个问题,我们计划将 MySQL 中的数据存储到内部监控工具(称为 inGraphs[2]) 。
安全
代理需要在 sudo 下运行。 为了减轻潜在的安全问题,您可以给代理提供高级权限 “cap_net_raw”。 此外,通过将执行权限设置为特定用户(chmod 100 或 500),您可以在特定用户下运行代理而不用 sudo。 有关详细信息,请参阅 https://linux.die.net/man/7/capabilities 。
概要
查询分析器的优点很多。 可以让我们的数据库工程师一目了然地识别有问题的查询,以便工程师环比对比每周查询,并快速高效地排除数据库减速。 开发人员和业务分析师能够可视化查询趋势,在进入开发之前检查分段环境中的查询负载,并为每个表和数据库获取指标,例如插入数量,更新,删除的数量,通过它们可以分析业务。 从安全的角度来看,查询分析器允许我们在新查询访问数据库时收到警报,我们还可以审核正在访问敏感信息的查询。最后,分析查询负载使我们能够确保查询在服务器间均匀分配,从而优化我们的硬件。 我们也可以更准确地进行性能规划。
虽然还没有定义时间表,但我们计划最终会开源查询分析器,并希望它对所有其他人都有用。
致谢
感谢 LinkedIn MySQL 团队: Basavaiah Thambara 和 Alex Lurthu 进行设计审查, Kishore Govindaluri 开发 UI,以及 Naresh Kumar Vudutha 进行代码审查。
相关链接
1.https://github.com/percona/go-mysql/tree/master/query
2.https://engineering.linkedin.com/blog/2017/08/ingraphs--monitoring-and-unexpected-artwork
本文作者 Karthik Appigatla,由 Jesse 翻译,转载译文请注明出处,技术原创及架构实践文章,欢迎通过公众号菜单「联系我们」进行投稿。
推荐阅读
- 性能优化利器:剖析MySQL 5.7新特征 sys schema
- 为什么Uber宣布从Postgres切换到MySQL?
- MySQL 5.7 新特性大全和未来展望
- 单表60亿记录等大数据场景的MySQL优化和运维之道
- 系统重构的10点经验总结
高可用架构
改变互联网的构建方式
