根据Perl编程语言的作者拉里·沃尔的说法,程序员具有三大美德:懒惰,不耐烦和傲慢。懒惰可以让你全力以赴,降低总能耗,其他人会发现你编写的省力程序很有用。

比尔盖茨的观点是:我选择让懒惰的人完成艰巨的任务,因为他可以找到完成任务的捷径。
网页抓取或许是一个相当简单的编程问题:在文档的源代码中搜索唯一标识符,提取相关数据,但我认为存在一个更“懒惰”的解决方案——更简单,更快,可以生成更多数据。
雅虎财经是财务数据做得最好的网站之一,这也让它成为金融爱好者进行网页抓取的主要目标。几乎每天都有关于StackOverflow的问题,抓取数据的人参考了雅虎财经的某种数据检索(通常是通过网络抓取)。
网页抓取问题1
网页抓取者尝试查找Facebook当前的股票价格。代码如下:
import requests
from bs4 importBeautifulSoup
defparsePrice():
r = requests.get("https://finance.yahoo.com/quote/FB?p=FB")
soup =BeautifulSoup(r.text, "lxml")
price = soup.find( div , { class : My(6px) Pos(r)smartphone_Mt(6px) }).find( span ).text
print(f the current price: {price} ) 该代码输出如下:
the current price: 216.08 使用简单的网页抓取解决方案非常简单,但这还不够“懒惰”,让我们看下一个。
网页抓取问题2
网页抓取者正在尝试从统计标签中查找有关股票的企业价值和空头股票数量的数据。他的问题实际上是检索可能存在或不存在的嵌套字典值,但是在检索数据上,他似乎已经找到了更好的解决方法。
import requests, re, json, pprint
p = re.compile(r root.App.main =(.*); )
tickers = [ AGL.AX ]
results = {}
with requests.Session() as s:
for ticker in tickers:
r = s.get( https://finance.yahoo.com/quote/{}/key-statistics?p={} .format(ticker,ticker))
data = json.loads(p.findall(r.text)[0])
key_stats = data[ context ][ dispatcher ][ stores ][ QuoteSummaryStore ]
print(key_stats)
res = {
Enterprise Value : key_stats[ defaultKeyStatistics ][ enterpriseValue ][ fmt ]
, Shares_Short : key_stats[ defaultKeyStatistics ][ sharesShort ].get( longFmt , N/A )
}
results[ticker] = res
print(results) 看第3行:网页抓取者能够在javascript的变量内找到他要查找的数据:
root.App.main = {.... }; 在那里,只需访问字典中适当的嵌套键,即可轻松检索数据。但是,确实还有更“懒惰”的办法。
“懒惰”的解决方案1
import requests
r = requests.get("https://query2.finance.yahoo.com/v10/finance/quoteSummary/FB?modules=price")
data = r.json()
print(data)
print(f"the currentprice: {data[ quoteSummary ][ result ][0][ price ][ regularMarketPrice ][ raw ]}") 看看第三行的URL,输出如下:
{
quoteSummary : {
error : None,
result : [{
price : {
averageDailyVolume10Day : {},
averageDailyVolume3Month : {},
circulatingSupply : {},
currency : USD ,
currencySymbol : $ ,
exchange : NMS ,
exchangeDataDelayedBy :0,
exchangeName : NasdaqGS ,
fromCurrency : None,
lastMarket : None,
longName : Facebook,Inc. ,
marketCap : {
fmt : 698.42B ,
longFmt : 698,423,836,672.00 ,
raw : 698423836672
},
marketState : REGULAR ,
maxAge : 1,
openInterest : {},
postMarketChange : {},
postMarketPrice : {},
preMarketChange : {
fmt : -0.90 ,
raw : -0.899994
},
preMarketChangePercent :{
fmt : -0.37% ,
raw : -0.00368096
},
preMarketPrice : {
fmt : 243.60 ,
raw : 243.6
},
preMarketSource : FREE_REALTIME ,
preMarketTime :1594387780,
priceHint : {
fmt : 2 ,
longFmt : 2 ,
raw : 2
},
quoteSourceName : Nasdaq Real Time
Price ,
quoteType : EQUITY ,
regularMarketChange : {
fmt : 0.30 ,
raw : 0.30160522
},
regularMarketChangePercent : {
fmt : 0.12% ,
raw : 0.0012335592
},
regularMarketDayHigh : {
fmt : 245.49 ,
raw : 245.49
},
regularMarketDayLow : {
fmt : 239.32 ,
raw : 239.32
},
regularMarketOpen : {
fmt : 243.68 ,
raw : 243.685
},
regularMarketPreviousClose : {
fmt : 244.50 ,
raw : 244.5
},
regularMarketPrice : {
fmt : 244.80 ,
raw : 244.8016
},
regularMarketSource : FREE_REALTIME ,
regularMarketTime :1594410026,
regularMarketVolume : {
fmt : 19.46M ,
longFmt : 19,456,621.00 ,
raw : 19456621
},
shortName : Facebook,Inc. ,
strikePrice : {},
symbol : FB ,
toCurrency : None,
underlyingSymbol : None,
volume24Hr : {},
volumeAllCurrencies : {}
}
}]
}
}the current price: 241.63 “懒惰”的解决方案2
import requests
r = requests.get("https://query2.finance.yahoo.com/v10/finance/quoteSummary/AGL.AX?modules=defaultKeyStatistics")
data = r.json()
print(data)
print({
AGL.AX : {
Enterprise Value : data[ quoteSummary ][ result ][0][ defaultKeyStatistics ][ enterpriseValue ][ fmt ],
Shares Short : data[ quoteSummary ][ result ][0][ defaultKeyStatistics ][ sharesShort ].get( longFmt , N/A )
}
}) 再次看一下第三行的URL,输出如下:
{
quoteSummary : {
result : [{
defaultKeyStatistics : {
maxAge : 1,
priceHint : {
raw : 2,
fmt : 2 ,
longFmt : 2
},
enterpriseValue : {
raw : 13677747200,
fmt : 13.68B ,
longFmt : 13,677,747,200
},
forwardPE : {},
profitMargins : {
raw : 0.07095,
fmt : 7.10%
},
floatShares : {
raw : 637754149,
fmt : 637.75M ,
longFmt : 637,754,149
},
sharesOutstanding : {
raw : 639003008,
fmt : 639M ,
longFmt : 639,003,008
},
sharesShort : {},
sharesShortPriorMonth :{},
sharesShortPreviousMonthDate :{},
dateShortInterest : {},
sharesPercentSharesOut : {},
heldPercentInsiders : {
raw : 0.0025499999,
fmt : 0.25%
},
heldPercentInstitutions : {
raw : 0.31033,
fmt : 31.03%
},
shortRatio : {},
shortPercentOfFloat :{},
beta : {
raw : 0.365116,
fmt : 0.37
},
morningStarOverallRating :{},
morningStarRiskRating :{},
category : None,
bookValue : {
raw : 12.551,
fmt : 12.55
},
priceToBook : {
raw : 1.3457094,
fmt : 1.35
},
annualReportExpenseRatio : {},
ytdReturn : {},
beta3Year : {},
totalAssets : {},
yield : {},
fundFamily : None,
fundInceptionDate : {},
legalType : None,
threeYearAverageReturn :{},
fiveYearAverageReturn :{},
priceToSalesTrailing12Months :{},
lastFiscalYearEnd : {
raw : 1561852800,
fmt : 2019-06-30
},
nextFiscalYearEnd : {
raw : 1625011200,
fmt : 2021-06-30
},
mostRecentQuarter : {
raw : 1577750400,
fmt : 2019-12-31
},
earningsQuarterlyGrowth : {
raw : 0.114,
fmt : 11.40%
},
revenueQuarterlyGrowth :{},
netIncomeToCommon : {
raw : 938000000,
fmt : 938M ,
longFmt : 938,000,000
},
trailingEps : {
raw : 1.434,
fmt : 1.43
},
forwardEps : {},
pegRatio : {},
lastSplitFactor : None,
lastSplitDate : {},
enterpriseToRevenue : {
raw : 1.035,
fmt : 1.03
},
enterpriseToEbitda : {
raw : 6.701,
fmt : 6.70
},
52WeekChange : {
raw : -0.17621362,
fmt : -17.62%
},
SandP52WeekChange : {
raw : 0.045882702,
fmt : 4.59%
},
lastDividendValue : {},
lastCapGain : {},
annualHoldingsTurnover :{}
}
}],
error : None
}
}{ AGL.AX : { Enterprise Value : 13.73B , Shares Short : N/A }} “懒惰”的解决方案只是简单地将请求从使用前端URL更改为某种非官方的返回JSON数据的API端点。这个方案更简单,可以导出更多数据 ,那么它的速度呢?代码如下:
import timeit
import requests
from bs4 importBeautifulSoup
import json
import re
repeat =5
number =5
defweb_scrape_1():
r = requests.get(f https://finance.yahoo.com/quote/FB?p=FB )
soup =BeautifulSoup(r.text, "lxml")
price = soup.find( div , { class : My(6px) Pos(r)smartphone_Mt(6px) }).find( span ).text
returnf the current price: {price}
deflazy_1():
r = requests.get( https://query2.finance.yahoo.com/v10/finance/quoteSummary/FB?modules=price )
data = r.json()
returnf"the currentprice: {data[ quoteSummary ][ result ][0][ price ][ regularMarketPrice ][ raw ]}"
defweb_scrape_2():
p = re.compile(r root.App.main = (.*); )
ticker = AGL.AX
results = {}
with requests.Session() as s:
r = s.get( https://finance.yahoo.com/quote/{}/key-statistics?p={} .format(ticker,ticker))
data = json.loads(p.findall(r.text)[0])
key_stats = data[ context ][ dispatcher ][ stores ][ QuoteSummaryStore ]
res = {
Enterprise Value : key_stats[ defaultKeyStatistics ][ enterpriseValue ][ fmt ],
Shares Short : key_stats[ defaultKeyStatistics ][ sharesShort ].get( longFmt , N/A )
}
results[ticker] = res
return results
deflazy_2():
r = requests.get( https://query2.finance.yahoo.com/v10/finance/quoteSummary/AGL.AX?modules=defaultKeyStatistics )
data = r.json()
return {
AGL.AX : {
Enterprise Value : data[ quoteSummary ][ result ][0][ defaultKeyStatistics ][ enterpriseValue ][ fmt ],
Shares Short : data[ quoteSummary ][ result ][0][ defaultKeyStatistics ][ sharesShort ].get( longFmt , N/A )
}
}
web_scraping_1_times = timeit.repeat(
web_scrape_1() ,
setup= import requests; from bs4 import BeautifulSoup ,
globals=globals(),
repeat=repeat,
number=number)
print(f web scraping #1min time is {min(web_scraping_1_times) / number} )
lazy_1_times = timeit.repeat(
lazy_1() ,
setup= import requests ,
globals=globals(),
repeat=repeat,
number=number
)
print(f lazy #1 min timeis {min(lazy_1_times) / number} )
web_scraping_2_times = timeit.repeat(
web_scrape_2() ,
setup= import requests, re, json ,
globals=globals(),
repeat=repeat,
number=number)
print(f web scraping #2min time is {min(web_scraping_2_times) / number} )
lazy_2_times = timeit.repeat(
lazy_2() ,
setup= import requests ,
globals=globals(),
repeat=repeat,
number=number
)
print(f lazy #2 min timeis {min(lazy_2_times) / number} ) web scraping #1 min time is 0.5678426799999997
lazy #1 min time is 0.11238783999999953
web scraping #2 min time is 0.3731000199999997
lazy #2 min time is 0.0864451399999993 “懒惰”的替代方案比其网页抓取同类产品快4到5倍!
“偷懒”的过程
思考一下上面遇到的两个问题:原来的方案里,代码加载到页面后,我们尝试检索数据。“懒惰”的解决方案直接针对数据源,根本不理会前端页面。当你尝试从网站提取数据时,这是一个重要区别和一个很好的方法。
步骤1:检查XHR请求
XHR(XMLHttpRequest)对象是可用于Web浏览器脚本语言(例如JavaScript)的API,它将HTTP或HTTPS请求发送到Web服务器,并将服务器响应数据加载回脚本中。基本上,XHR允许客户端从URL检索数据,不必刷新整个网页。
笔者将使用Chrome进行以下演示,但是其他浏览器也具有类似的功能。
· 打开Chrome的开发者控制台。要在Google Chrome中打开开发者控制台,请打开浏览器窗口右上角的Chrome菜单,然后选择更多工具>开发者工具。也可以使用快捷键Option + ?+ J(适用于ios系统),或Shift + CTRL + J(适用于Windows / Linux)。
- 选择“网络”选项卡。
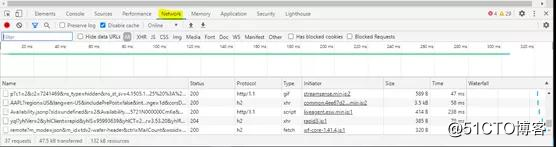
- 然后通过“ XHR”筛选结果
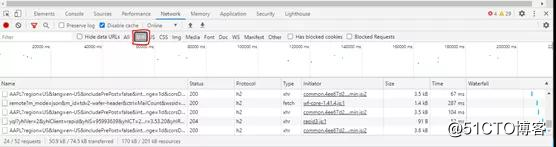
应注意,尽管有些请求包含“ AAPL”,得到的结果将相似但不相同。从调查这些开始,单击最左侧列中包含字符“ AAPL”的链接之一。
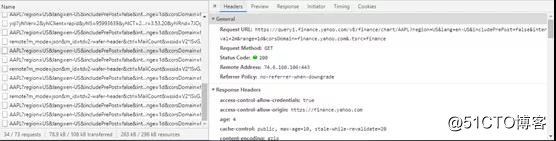
- 选择其中一个链接后会看到一个附加窗口,其中提供了所选请求的详细信息。第一个选项卡Headers,提供有关浏览器请求和服务器响应的详细信息。你应该立即注意到“Headers”选项卡中的“URL请求”与上面的惰性解决方案中提供的URL请求非常相似。
如果选择“预览”选项卡,将看到从服务器返回的数据。
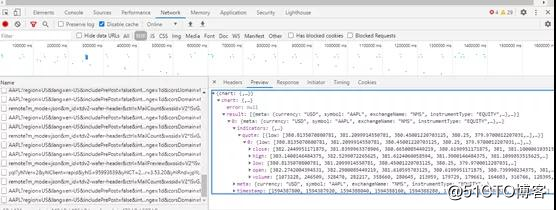
好极了!看来我们找到了获取Apple OHLC数据的URL!
步骤2:搜寻
现在我们已经发现了一些通过浏览器发出的XHR请求。搜索javascript文件,查看是否可以找到更多信息。笔者发现与XHR请求相关的URL共同点是“ query1”和“ query2”。在开发者控制台的右上角,选择三个垂直点,然后在下拉框中选择“搜索”。
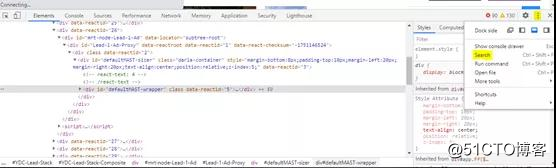
在搜索栏中搜索“ query2”:
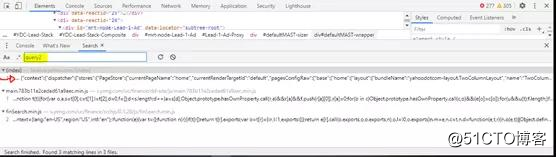
选择第一个选项。将会弹出一个附加选项卡,其中包含找到“ query2”的位置。应该在这里注意到类似的内容:
网页抓取解决方案2提取的数据变量与该变量相同。控制台应提供“优质打印”变量的选项。你可以选择该选项,也可以将整行(上面的第11行)复制并粘贴到https://beautifier.io/。或者如果你使用vscode,下载美化扩展,它会做同样的事情。
正确格式化后,将整个代码粘贴到文本编辑器或类似的编辑器中,然后再次搜索“ query2”。搜索结果应该在 “ Service Plugin” 中。该部分包含雅虎财经用于在其页面中填充数据的URL。以下是该部分的内容:
"tachyon.quoteSummary": {
"path": "/v10/finance/quoteSummary/{symbol}",
"timeout":6000,
"query": ["lang", "region","corsDomain", "crumb", "modules", "formatted"],
"responseField":"quoteSummary",
"get": {"formatted": true}
}, 以上是“懒惰”的解决方案中使用的URL。
“懒惰”人类发展的阶梯,适当偷懒,你会进入新世界。
本文转载自微信公众号「读芯术」,可以通过以下二维码关注。转载本文请联系读芯术公众号。

【编辑推荐】
- 不需要一行 Python 代码,也可以自动获取数据
- 算法博士平均月入4万,数据可视化技能全球吃香
- 90%面试官都会考察的数据分析题:说说业务分析的流程
- 城市CIO必须在新冠时期加强数据工作
- 数据分析在业务中的五个好处
【责任编辑:武晓燕 TEL:(010)68476606】