clickhouse 应用总结调研:
概述:
clickhouse 是俄罗斯的“百度”Yandex公司在2016年开源的,一款针对大数据实时分析的高性能分布式数据库,与之对应的有hadoop生态hive,Vertica和百度出品的palo。
其作为分析型数据库,有三大特点:一是跑分快,二是功能多,三是文艺范。
背景:
Hadoop 生态体系解决了大数据界的大部分问题,当然其也存在缺点。Hadoop 体系的最大短板在于数据处理时效性。基于 Hadoop 生态的数据处理场景大部分对时效要求不高,按照传统的做法一般是 T + 1 的数据时效进行数据分析
ClickHouse 的产生就是为了解决大数据量处理的时效性。独立于Hadoop生态圈
特性:
(1)采用列式存储
(2)数据压缩
(3)CPU 利用率高,在计算时会使用机器上的所有 CPU 资源
(4)支持分片,并且同一个计算任务会在不同分片上并行执行,计算完成后会将结果汇总
(5)支持SQL,SQL 几乎成了大数据的标准工具,使用门槛较低
(6)支持联表查询
(7)支持实时更新
(8)自动多副本同步
(9)支持索引
(10)分布式存储查询
优劣总结:
优点
1、性能高,列存压缩比高,通过索引实现秒级响应
2、实时性强,支持kafka导入
3、处理方式简单,无需预处理,保存明细数据
4、数据压缩、多核并行处理
5、支持数据复制和数据完整性
shard分片
replica副本
6、多服务器分布式处理。其他列式数据库管理系统中,几乎没有一个支持分布式的查询处理(但 没有完整的事务支持。)
7、支持sql 大部分情况下是与SQL标准兼容的。 支持的查询包括 GROUP BY,ORDER BY,IN,JOIN以及非相关子查询。 不支持窗口函数和相关子查询。(但易用性较弱,SQL语法不标准,不支持窗口函数等;维护成本高)
8、向量引擎、实时数据插入
9、稀疏索引、适合在线查询
缺点
1、数据规模一般
2、灵活性差,不支持任意的adhoc查询,join的支持不好。
3、缺少高频率,低延迟的修改或删除已存在数据的能力。仅能用于批量删除或修改数据,但这符合 GDPR。
稀疏索引使得ClickHouse不适合通过其键检索单行的点查询。
druid 实时数据分析(olap)
背景:
大数据时代,从海量数据中提取有价值的信息,业内出现了众多优秀的开源项目,其中最有名的当属Apache Hadoop生态圈。时至今日,Hadoop已经成为了大数据的“标准”解决方案,其作为海量历史数据保存、冷数据分析,确实是一个优秀的通用解决方案,但是,人们在享受Hadoop便捷数据分析的同时,也必须要忍受Hadoop在设计上的许多“痛点”
(1)、何时能进行数据查询?对于Hadoop使用的Map/Reduce批处理框架,数据何时能够查询没有性能时间保证。
(2)、随机IO问题。Map/Reduce批处理框架所处理的数据需要存储在HDFS上,而HDFS是一个以集群硬盘作为存储资源池的分布式文件系统,那么在海量数据的处理过程中,必然会引起大量的读写操作,此时随机IO就成为了高并发场景下的性能瓶颈。
(3)、数据可视化问题。HDFS是一个优秀的分布式文件系统,但是对于数据分析以及数据的即席查询,HDFS并不是最优的选择
为了保证高并发环境下海量数据的查询分析性能,以及如何实现海量实时数据的查询分析与可视化,MetaMarket开源了druid实时分析数据存储。
druid 原理图:
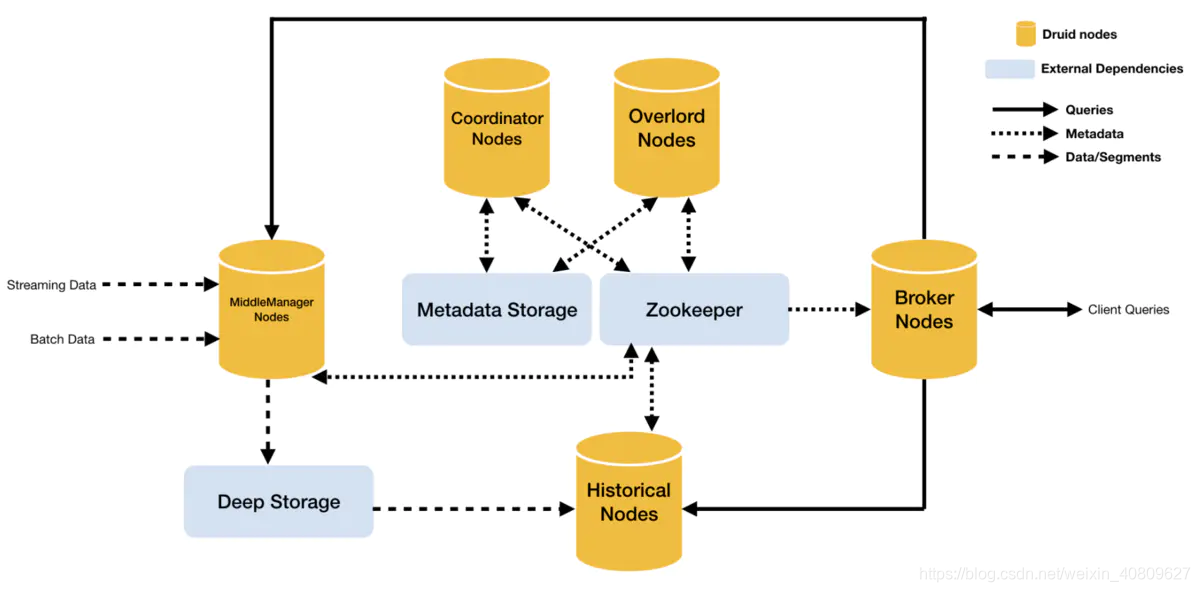
特性:
1.列式存储格式 Druid使用面向列的存储,这意味着它只需要加载特定查询所需的精确列。这为仅查看几列的查询提供了巨大的速度提升。此外,每列都针对其特定数据类型进行了优化,支持快速扫描和聚合。
2.高可用性与高可拓展性 Druid采用分布式、SN(share-nothing)架构,管理类节点可配置HA,工作节点功能单一,不相互依赖,这些特性都使得Druid集群在管理、容错、灾备、扩容等方面变得十分简单。Druid通常部署在数十到数百台服务器的集群中,并且可以提供数百万条记录/秒的摄取率,保留数万亿条记录,以及亚秒级到几秒钟的查询延迟。
3.大规模并行处理 Druid可以在整个集群中并行处理查询。
**4.实时或批量摄取 实时流数据分析。**区别于传统分析型数据库采用的批量导入数据进行分析的方式,Druid提供了实时流数据分析,采用LSM(Long structure-merge)-Tree结构使Druid拥有极高的实时写入性能;同时实现了实时数据在亚秒级内的可视化。
5.自愈,自平衡,易于操作 要将群集扩展或缩小,只需添加或删除服务器,群集将在后台自动重新平衡,无需任何停机时间。如果任何Druid服务器发生故障,系统将自动路由损坏,直到可以更换这些服务器。Druid旨在全天候运行,无需任何原因计划停机,包括配置更改和软件更新。
**6.云原生,容错的架构,不会丢失数据 一旦Druid摄取了您的数据,**副本就会安全地存储在深层存储(通常是云存储,HDFS或共享文件系统)中。即使每个Druid服务器都出现故障,您的数据也可以从深层存储中恢复。对于仅影响少数Druid服务器的更有限的故障,复制可确保在系统恢复时仍可进行查询。
7.亚秒级的OLAP查询分析 Druid采用了列式存储、倒排索引、位图索引等关键技术,能够在亚秒级别内完成海量数据的过滤、聚合以及多维分析等操作。
8.近似算法 Druid包括用于近似计数 - 不同,近似排序以及近似直方图和分位数的计算的算法。这些算法提供有限的内存使用,并且通常比精确计算快得多。对于精确度比速度更重要的情况,Druid还提供精确计数 - 不同且精确的排名。
9.丰富的数据分析功能针对不同用户群体,Druid提供了友好的可视化界面、类SQL查询语言以及REST 查询接口。
**10、Druid则是轻量级的提前聚合(roll-up),**同时根据倒排索引以及bitmap提高查询效率的时间序列数据和存储引擎。
11、**druid 原生状态是不支持精确去重功能的,**但是可以采用一些外部方案去实行,具体参考:https://www.infoq.cn/article/YdPlYzWCCQ5sPR_iKtVz
druid 索引构建(位图索引倒排索引)
Druid数据实时写入节点采用LSM结构保证数据的写入性能。数据先写入内存,每隔10min(可配)会将内存中的数据persist到本地硬盘形成文件,然后会有一个线程再每隔1h(可配)将本地硬盘的多个文件合并成一个segment。
ClickHouse Druid/Pinot
具备C++经验的组织 具备Java经验的组织
小型集群 大型集群
少量表 大量表
单一数据集 多个不相关的数据集(多租户)
表和数据集永久驻留在集群中 表和数据集定期出现并从群集中退出
表格大小(以及它们的查询强度)在时间上是稳定的 表格随时间热度降低
查询的同质性(其类型,大小,按时间分布等) 异质性
存在可以用于分区的维度,且经过该维度分区后,几乎不会触发跨分区的数据查询 没有这样的维度,查询经常触及整个集群中的数据
不使用云,集群部署在特定的物理服务器上 群集部署在云中
无需依赖现有的Hadoop或Spark集群 Hadoop或Spark的集群已经存在并且可以使用
优缺点:
优点:
1、支持的数据规模大(本地存储+DeepStorage–HDFS)
2、性能高,列存压缩,预聚合加上倒排索引以及位图索引,秒级查询
3、实时性高,可以通过kafka实时导入数据
缺点:
1、灵活性适中,虽然维度之间随意组合,但不支持adhoc查询,不能自由组合查询,且丢失了明细数据(不采用roll-up情况下可以进行明细查询)
2、易用性较差,不支持join,不支持更新,sql支持很弱(有些插件类似于pinot的PQL语言),只能JSON格式查询;对于去重操作不能精准去重。
3、处理方式复杂,需要流处理引擎将数据join成宽表,维护相对复杂;对内存要求较高。
三、不同应用场景分析:
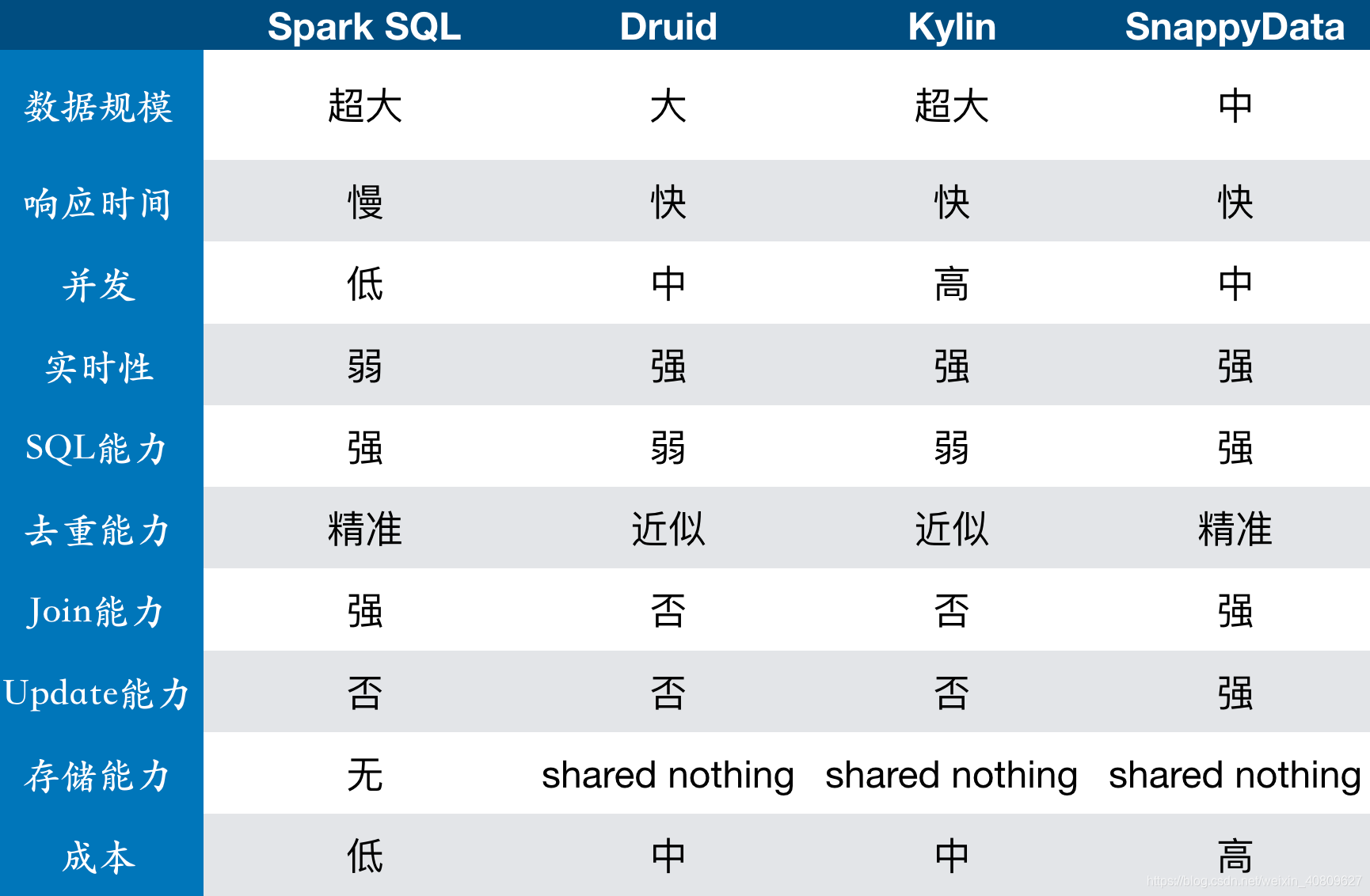

参考文章:olap引擎分析
https://snappydata-cn.github.io/2018/04/04/SnappyData%E4%B8%8EPresto-Druid-Kylin-ES%E7%9A%84%E5%AF%B9%E6%AF%94-2/