一.HashSet基础学习
1.何为HashSet?
顾名思义,它是哈希集。很明显,它是利用hash原理来存储数据的,hash最大的特点就是无序和无重复性,但查询快。
2.我们为何需要它?
链表和数组可以按照我们的意思排列元素的次序,但是如果我们不知道我们要查找元素的位置,我们就需要遍历数组和链表直到找到为止,可想而知,如果元素很多,那将花费很多的时间。但如果不在意元素的顺序,那么HashSet是个很好的选择。
3.构造方法:
| 构造方法 | 描述 |
|---|---|
| HashSet() | 构造一个新的空集合; 背景HashMap实例具有默认初始容量(16)和负载因子(0.75)。 |
| HashSet(Collection<? extends E> c) | 构造一个包含指定集合中的元素的新集合。 |
| HashSet(int initialCapacity) | 构造一个新的空集合; 背景HashMap实例具有指定的初始容量和默认负载因子(0.75)。 |
| HashSet(int initialCapacity, float loadFactor) | 构造一个新的空集合; 背景HashMap实例具有指定的初始容量和指定的负因子。 |
负载因子决定何时对哈希表再哈希,例如负载因子为0.75,当表中超过75%的位置已经填入元素,这个表进行双倍扩增。
4.其他方法学习
| 方法 | 描述 |
|---|---|
| boolean add(E e) | 将指定的元素添加到此集合(如果尚未存在)。 |
| void clear() | 从此集合中删除所有元素。 |
| Object clone() | 返回此 HashSet实例的浅层副本:元素本身不被克隆。 |
| boolean contains(Object o) | 如果此集合包含指定的元素,则返回 true 。 |
| boolean isEmpty() | 如果此集合不包含元素,则返回 true 。 |
| Iterator iterator() | 返回此集合中元素的迭代器。 |
| boolean remove(Object o) | 如果存在,则从该集合中删除指定的元素。 |
| int size() | 返回此集合中的元素数(其基数)。 |
| Spliterator spliterator() | 在此集合中的元素上创建late-binding和故障快速 Spliterator 。 |
使用例子:
package JavaHeXinJiShu;
import java.io.File;
import java.io.IOException;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Scanner;
import java.util.Set;
public class example9_2 {
public static void main(String[] args) throws IOException {
Set<String> words = new HashSet<>(); // 初始容量为16,负载因子为0.75
long totalTime = 0;
try (Scanner in = new Scanner("we should working hard"))
{
while (in.hasNext())//hashNext()默认以空格为分界符
{
String word = in.next();
words.add(word);//向哈希表中添加元素
}
}
Iterator<String> iter = words.iterator();//得到words的遍历器
for (int i = 1; i <= 20 && iter.hasNext(); i++)
System.out.println(iter.next());
System.out.println(". . .");
}
}
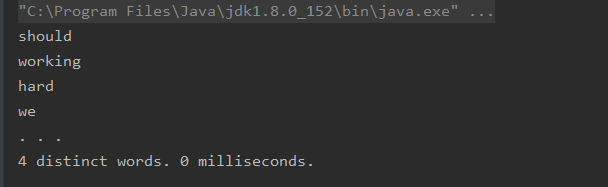
可以明显看到添加后的遍历顺序是无序的。
二.HashSet是如何被实现的?
1.查看源码我们可以看到:
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable
它主要继承了AbstracSet类和实现了Set接口。
2.查看Set接口定义的方法:
boolean add(E e)
如果指定的元素不存在,则将其指定的元素添加(可选操作)。
boolean addAll(Collection<? extends E> c)
将指定集合中的所有元素添加到此集合(如果尚未存在)(可选操作)。
voidclear()
从此集合中删除所有元素(可选操作)。
boolean contains(Object o)
如果此集合包含指定的元素,则返回 true 。
boolean containsAll(Collection<?> c)
返回 true如果此集合包含所有指定集合的元素。
boolean equals(Object o)
将指定的对象与此集合进行比较以实现相等。
int hashCode()
返回此集合的哈希码值。
boolean isEmpty()
如果此集合不包含元素,则返回 true 。
Iterator<E> iterator()
返回此集合中元素的迭代器。
boolean remove(Object o)
如果存在,则从该集合中删除指定的元素(可选操作)。
boolean removeAll(Collection<?> c)
从此集合中删除指定集合中包含的所有元素(可选操作)。
boolean retainAll(Collection<?> c)
仅保留该集合中包含在指定集合中的元素(可选操作)。
int size()
返回此集合中的元素数(其基数)。
default Spliterator<E> spliterator()
在此集合中的元素上创建一个 Spliterator 。
Object[] toArray()
返回一个包含此集合中所有元素的数组。
<T> T[] toArray(T[] a)
返回一个包含此集合中所有元素的数组; 返回的数组的运行时类型是指定数组的运行时类型。
3.我们知道AbstracSet类主要实现了Set接口,我们下面看看它重点实现了那些方法:
boolean equals(Object o)//将指定的对象与此集合进行比较以实现相等。
int hashCode()//返回此集合的哈希码值。
boolean removeAll(Collection<?> c)//从此集合中删除指定集合中包含的所有元素(可选操作)。
源码也不长:
package java.util;
public abstract class AbstractSet<E> extends AbstractCollection<E> implements Set<E> {
protected AbstractSet() {
}
//将指定的对象与此集合进行比较以实现相等。
public boolean equals(Object o) {
if (o == this)
return true;
if (!(o instanceof Set))
return false;
Collection<?> c = (Collection<?>) o;
if (c.size() != size())
return false;
try {
return containsAll(c);
} catch (ClassCastException unused) {
return false;
} catch (NullPointerException unused) {
return false;
}
}
//返回此集合的哈希码值。
public int hashCode() {
int h = 0;
Iterator<E> i = iterator();
while (i.hasNext()) {
E obj = i.next();
if (obj != null)
h += obj.hashCode();
}
return h;
}
//从此集合中删除指定集合中包含的所有元素(可选操作)。
public boolean removeAll(Collection<?> c) {
Objects.requireNonNull(c);
boolean modified = false;
if (size() > c.size()) {
for (Iterator<?> i = c.iterator(); i.hasNext(); )
modified |= remove(i.next());
} else {
for (Iterator<?> i = iterator(); i.hasNext(); ) {
if (c.contains(i.next())) {
i.remove();
modified = true;
}
}
}
return modified;
}
}
4.OK我们了解了HashSet的依赖类,下面我们来分析HashSet类:
1)我们首先学习一个HashSet是如何被建立的:
Set<String> words = new HashSet<>();
通过上面简单的语句我们创建了一个名为words的HashSet的对象,
实际上它背后是这样实现的:
我们知道创建一个实例调用的是构造方法,以上面的空参数构造方法为例,查询源码我们有:
private transient HashMap<E,Object> map;
public HashSet() {
map = new HashMap<>();
}
从上面来看HashSet里面用到了HashMap,下面我们进一步探索:
static final float DEFAULT_LOAD_FACTOR = 0.75f;
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
从上面我们可以看出这里map的负载因子为0.75,也就是设置哈希表的负载因子。
2)然后我们来看add方法:
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
从上面看到,向HashSet中添加元素实际上是利用HashMap来存储元素的。
到此我们可以看出HashSet的基本实现元素了,至于更深入的方法探索,我们可以上面的基础上来探索。