冒泡排序是排序算法中比较经典的算法,首先它的时间复杂度为O(n^2),时间复杂度为平方的算法一般就需要两层嵌套循环。
首先分析一下这个算法,这个算法主要是每次查看的相邻的两个数据进行大小比较,然后将大的数据向后换,这样一趟下来最大数据的就换到数组的最末尾了。
那么由这个思想可以分析到需要两个指针,当然了java里没有指针,那如何进行比较呢?举个例子:
假设有这么一个数组:int[] arr = {3,9,-1,10,6}; 那么设当前循环到的下标为n,那么两个数相比较就是if(arr[n]>arr[n+1]){};既然在一遍循环里出现了访问arr[n],arr[n+1]那么每一次循环理应循环的次数为arr.length-1,不然数组越界。那么有理由推断出内层循环为:
for (int j = 0; j < arr.length - 1; j++) {
if (arr[j] > arr[j + 1]) {
int temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}接下来就是外层循环,可以分析一下假设我的数组后四个都被排列有序了那么也就是说剩下的一个就是最小的数字,也就是说外层循环只需要循环arr.length-1次即可,那么有理由推断出两层循环:
for (int i = 0; i < arr.length - 1; i++) {
for (int j = 0; j < arr.length - 1; j++) {
if (arr[j] > arr[j + 1]) {
int temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
}接下来最后一步就是优化:
在内层循环中当第一趟内层循环结束就代表数组的后几位已经是有序的了,所以在下一趟内层循环也就不需要将全部数据循环一遍。
假设内层循环在一趟循环中一个数据交换操作都没执行,那么代表整个数列已经是有序的数列了,所以此时可以提前跳出循环。
最后冒泡排序的最终代码的是:
public static void bubbleSort(int[] arr) {
boolean flag = false;
for (int i = 0; i < arr.length - 1; i++) {
for (int j = 0; j < arr.length - 1 - i; j++) {
if (arr[j] > arr[j + 1]) {
int temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
flag = true;
}
}
if (!flag) {
break;
} else {
flag = false;
}
}
}
下面来测试一下本算法在处理10w条数据的处理时间
public static void main(String[] args) {
int[] arr = new int[100000];
for (int i = 0; i < arr.length; i++) {
arr[i] = (int) (Math.random() * 100000);
}
// System.out.println(Arrays.toString(arr));
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
String start = sdf.format(new Date());
System.out.println(start);
bubbleSort(arr);
String end = sdf.format(new Date());
System.out.println(end);
}
最终的运行结果为:(具体运行时间与计算机性能有关这里就是宏观展示一下)


可以很直观的看出这个时间还是有点长的哈~~
选择排序算法其实和冒泡排序相似,同样是O(n^2)的复杂度,但具体区别在于冒泡排序在取值判断过程中一直在交换,而选择排序则是将一趟排序中最小的数字保存下来,等待一趟循环过后再进行交换。虽然时间复杂度上两个算法的级别是一样的,但实际上选择排序的性能还是要由于冒泡排序的。
首先定义一个待排序的数组int[] arr = { 3, 9, -1, 10, 6 };
根据选择排序的规则首先需要用数组中的第一个数与后面的数进行比较,然后记下下标与最小值
int min = arr[0];
int minIndex = 0;
for (int j = 0 + 1; j < arr.length; j++) {
if (min > arr[j]) {
// 这块不交换哈 这块只是记录一下最小值的下标和更新一下最小值
minIndex = j;
min = arr[j];
}
}
if (minIndex != 0) {
min = arr[0];
arr[0] = arr[minIndex];
arr[minIndex] = min;
}这样第一趟循环下来之后数组就变成了{-1,9,3,10,6}
将上面的代码循环arr.length-1次就可以得到一个有序的数组。最终的代码为:
public static void selectSort(int[] arr) {
for (int i = 0; i < arr.length - 1; i++) {
int min = arr[i];
int minIndex = i;
for (int j = i + 1; j < arr.length; j++) {
if (min > arr[j]) {
// 这块不交换哈 这块只是记录一下最小值的下标和更新一下最小值
minIndex = j;
min = arr[j];
}
}
if (minIndex != i) {
min = arr[i];
arr[i] = arr[minIndex];
arr[minIndex] = min;
}
}
}下面来测试一下本算法在处理10w条数据的处理时间
public static void main(String[] args) {
int[] arr = new int[100000];
for (int i = 0; i < arr.length; i++) {
arr[i] = (int) (Math.random() * 8000000);
}
// System.out.println(Arrays.toString(arr));
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
String start = sdf.format(new Date());
System.out.println(start);
selectSort(arr);
String end = sdf.format(new Date());
System.out.println(end);
}最终的运行结果为:
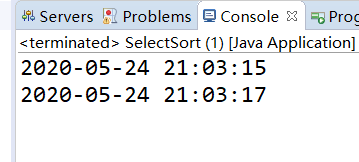
确实是比冒泡排序耗时短。