步骤:
1. 获取x坐标和y坐标(可能有多个y坐标)的数据,注意数据的长度必须相同。
2. x坐标和每一组y坐标组合,将曲线画在画布上。
先看效果:
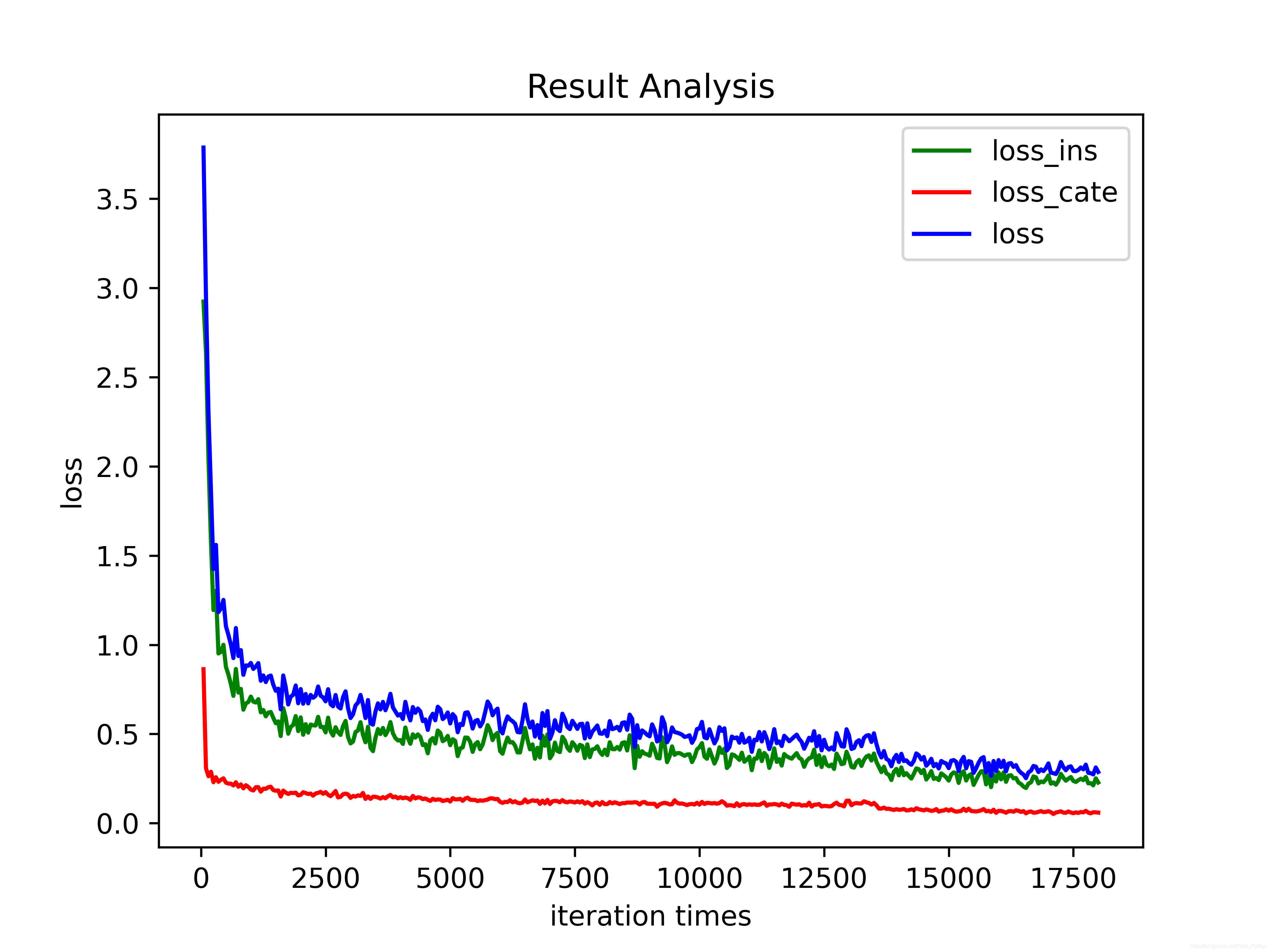
上代码:
#coding=utf-8
import matplotlib.pyplot as plt
def txt_reader(txt_file):
iters, loss_ins, loss_cates, losses = [], [], [], []
with open(txt_file, 'r') as f:
lines = f.readlines()
for idx, line in enumerate(lines):
parts = line.rstrip("\n").split(",")
iters.append((idx+1)*50)
loss_in = float(parts[7].split(" ")[2])
loss_ins.append(loss_in)
loss_cate = float(parts[8].split(" ")[2])
loss_cates.append(loss_cate)
loss = float(parts[9].split(" ")[2][:-1])
losses.append(loss)
return iters, loss_ins, loss_cates, losses
if __name__ == "__main__":
# 获取数据,数据存储在列表当中,列表的长度必须相等
iters, loss_ins, loss_cates, losses = txt_reader("test.txt")
plt.title("Result Analysis")
plt.plot(iters, loss_ins, color='green', label='loss_ins')
plt.plot(iters, loss_cates, color='red', label='loss_cate')
plt.plot(iters, losses, color='blue', label='loss')
plt.legend() # 显示图例
plt.xlabel("iteration times")
plt.ylabel("loss")
plt.savefig("test.png", dpi=600)
plt.show()test.txt数据如下:
{"mode": "train", "epoch": 1, "iter": 50, "lr": 0.00399, "time": 0.40244, "data_time": 0.0079, "memory": 3796, "loss_ins": 2.92358, "loss_cate": 0.86319, "loss": 3.78677}
{"mode": "train", "epoch": 1, "iter": 100, "lr": 0.00465, "time": 0.39973, "data_time": 0.00531, "memory": 3796, "loss_ins": 2.63875, "loss_cate": 0.30817, "loss": 2.94691}
{"mode": "train", "epoch": 1, "iter": 150, "lr": 0.00532, "time": 0.40629, "data_time": 0.00577, "memory": 3822, "loss_ins": 2.03759, "loss_cate": 0.26317, "loss": 2.30076}
{"mode": "train", "epoch": 1, "iter": 200, "lr": 0.00599, "time": 0.41431, "data_time": 0.00564, "memory": 3822, "loss_ins": 1.5731, "loss_cate": 0.28833, "loss": 1.86144}
{"mode": "train", "epoch": 1, "iter": 250, "lr": 0.00665, "time": 0.41081, "data_time": 0.00564, "memory": 3822, "loss_ins": 1.19468, "loss_cate": 0.22969, "loss": 1.42437}
{"mode": "train", "epoch": 1, "iter": 300, "lr": 0.00732, "time": 0.41768, "data_time": 0.00529, "memory": 3822, "loss_ins": 1.30239, "loss_cate": 0.2576, "loss": 1.55999}
{"mode": "train", "epoch": 1, "iter": 350, "lr": 0.00799, "time": 0.41031, "data_time": 0.0054, "memory": 3822, "loss_ins": 0.95138, "loss_cate": 0.23183, "loss": 1.18321}
{"mode": "train", "epoch": 1, "iter": 400, "lr": 0.00865, "time": 0.42539, "data_time": 0.00569, "memory": 3822, "loss_ins": 0.96007, "loss_cate": 0.24343, "loss": 1.20351}
{"mode": "train", "epoch": 1, "iter": 450, "lr": 0.00932, "time": 0.44364, "data_time": 0.00579, "memory": 3822, "loss_ins": 1.0, "loss_cate": 0.25153, "loss": 1.25152}
{"mode": "train", "epoch": 1, "iter": 500, "lr": 0.00999, "time": 0.42731, "data_time": 0.00591, "memory": 3822, "loss_ins": 0.87668, "loss_cate": 0.22732, "loss": 1.10401}
{"mode": "train", "epoch": 1, "iter": 550, "lr": 0.01, "time": 0.42553, "data_time": 0.00556, "memory": 3822, "loss_ins": 0.83301, "loss_cate": 0.22199, "loss": 1.055}
{"mode": "train", "epoch": 1, "iter": 600, "lr": 0.01, "time": 0.43198, "data_time": 0.00533, "memory": 3822, "loss_ins": 0.7791, "loss_cate": 0.22144, "loss": 1.00054}
{"mode": "train", "epoch": 1, "iter": 650, "lr": 0.01, "time": 0.43684, "data_time": 0.00564, "memory": 3822, "loss_ins": 0.71384, "loss_cate": 0.21173, "loss": 0.92557}
{"mode": "train", "epoch": 1, "iter": 700, "lr": 0.01, "time": 0.43482, "data_time": 0.0054, "memory": 3822, "loss_ins": 0.86436, "loss_cate": 0.22944, "loss": 1.0938}
{"mode": "train", "epoch": 1, "iter": 750, "lr": 0.01, "time": 0.4273, "data_time": 0.00564, "memory": 3822, "loss_ins": 0.73229, "loss_cate": 0.20463, "loss": 0.93692}
{"mode": "train", "epoch": 1, "iter": 800, "lr": 0.01, "time": 0.43773, "data_time": 0.00561, "memory": 3822, "loss_ins": 0.75275, "loss_cate": 0.21736, "loss": 0.97012}
{"mode": "train", "epoch": 1, "iter": 850, "lr": 0.01, "time": 0.43426, "data_time": 0.00536, "memory": 3822, "loss_ins": 0.63638, "loss_cate": 0.19536, "loss": 0.83175}
{"mode": "train", "epoch": 1, "iter": 900, "lr": 0.01, "time": 0.43096, "data_time": 0.0057, "memory": 3822, "loss_ins": 0.67119, "loss_cate": 0.21306, "loss": 0.88425}
{"mode": "train", "epoch": 1, "iter": 950, "lr": 0.01, "time": 0.42426, "data_time": 0.00546, "memory": 3822, "loss_ins": 0.67924, "loss_cate": 0.20326, "loss": 0.8825}
{"mode": "train", "epoch": 1, "iter": 1000, "lr": 0.01, "time": 0.42691, "data_time": 0.00574, "memory": 3822, "loss_ins": 0.70954, "loss_cate": 0.18852, "loss": 0.89805}
{"mode": "train", "epoch": 1, "iter": 1050, "lr": 0.01, "time": 0.42939, "data_time": 0.00571, "memory": 3822, "loss_ins": 0.68123, "loss_cate": 0.18355, "loss": 0.86478}
{"mode": "train", "epoch": 1, "iter": 1100, "lr": 0.01, "time": 0.42712, "data_time": 0.00538, "memory": 3822, "loss_ins": 0.67634, "loss_cate": 0.20164, "loss": 0.87798}
{"mode": "train", "epoch": 1, "iter": 1150, "lr": 0.01, "time": 0.43045, "data_time": 0.0055, "memory": 3822, "loss_ins": 0.69543, "loss_cate": 0.20198, "loss": 0.8974}
{"mode": "train", "epoch": 1, "iter": 1200, "lr": 0.01, "time": 0.4271, "data_time": 0.00557, "memory": 3822, "loss_ins": 0.62133, "loss_cate": 0.17701, "loss": 0.79834}
{"mode": "train", "epoch": 1, "iter": 1250, "lr": 0.01, "time": 0.43578, "data_time": 0.00573, "memory": 3822, "loss_ins": 0.63468, "loss_cate": 0.19341, "loss": 0.8281}
{"mode": "train", "epoch": 1, "iter": 1300, "lr": 0.01, "time": 0.44062, "data_time": 0.00562, "memory": 3822, "loss_ins": 0.59891, "loss_cate": 0.19234, "loss": 0.79125}
{"mode": "train", "epoch": 1, "iter": 1350, "lr": 0.01, "time": 0.43352, "data_time": 0.00536, "memory": 3822, "loss_ins": 0.62009, "loss_cate": 0.20177, "loss": 0.82186}
{"mode": "train", "epoch": 1, "iter": 1400, "lr": 0.01, "time": 0.42059, "data_time": 0.00535, "memory": 3822, "loss_ins": 0.62318, "loss_cate": 0.20429, "loss": 0.82746}
{"mode": "train", "epoch": 1, "iter": 1450, "lr": 0.01, "time": 0.4164, "data_time": 0.00504, "memory": 3822, "loss_ins": 0.59074, "loss_cate": 0.18582, "loss": 0.77656}
{"mode": "train", "epoch": 1, "iter": 1500, "lr": 0.01, "time": 0.41437, "data_time": 0.00483, "memory": 3822, "loss_ins": 0.56016, "loss_cate": 0.18197, "loss": 0.74212}OK,画你的训练日志吧!