#include <iostream>
#include <omp.h>
#include <pthread.h>
#include <cmath>
#include <sys/time.h>
using namespace std;
typedef struct {
int thread_id;
double a;
double b;
int n;
int thread_num;
double* global_val;
}thread_parm;
pthread_mutex_t mutex1;
double f(double);
void* omp1_area(double, double, int, double*);
void* omp2_area(double, double, int, double*);
void* omp3_area(double, double, int, double*);
void* serial_area(double, double, int, double*);
void* pthread_area(void*);
long test_time(int, int, double*);
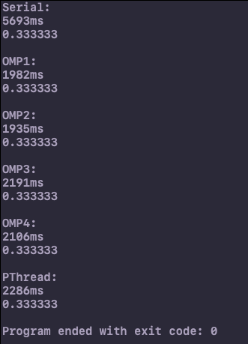
int main(int argc, const char * argv[]) {
int n = 100000000;
for (int i = 0; i <= 5; i++){
double global_val = 0;
cout<<test_time(i, n, &global_val)<<"ms"<<endl;
cout<<global_val<<endl<<endl;
}
return 0;
}
double f(double x) {
return pow(x, 2);
}
void* omp1_area(double a, double b, int n, double* global_val) {
int my_rank = omp_get_thread_num();
int thread_count = omp_get_num_threads();
double h;
double local_a, local_b, my_result;
int local_n;
h = (b - a) / n;
local_n = n/thread_count;
local_a = a + my_rank * local_n * h;
local_b = local_a + local_n * h;
my_result = (f(local_a) + f(local_b)) / 2;
for (int i = 1; i < local_n; i++) {
double x = local_a + i * h;
my_result += f(x);
}
my_result = my_result * h;
# pragma omp critical
*global_val += my_result;
return nullptr;
}
void* omp2_area(double a, double b, int n, double* global_val) {
int my_rank = omp_get_thread_num();
int thread_count = omp_get_num_threads();
double h;
double local_a, local_b;
double* my_result = (double*)malloc(sizeof(double));
int local_n;
h = (b - a) / n;
local_n = n/thread_count;
local_a = a + my_rank * local_n * h;
local_b = local_a + local_n * h;
*my_result = (f(local_a) + f(local_b)) / 2;
for (int i = 1; i < local_n; i++) {
double x = local_a + i * h;
*my_result += f(x);
}
*my_result = *my_result * h;
return (void*)my_result;
}
void* omp3_area(double a, double b, int n, double* global_val) {
double h, approx;
h = (b - a) / n;
approx = (f(a) + f(b)) / 2;
#pragma omp parallel for num_threads(4) reduction(+:approx)
for (int i = 1; i < n; i++) {
approx += f(a + i * h);
}
*global_val = approx * h;
return nullptr;
}
void* pthread_area(void* parm) {
thread_parm* p = (thread_parm*)parm;
int thread_id = p->thread_id;
int thread_num = p->thread_num;
double a = p->a;
double b = p->b;
int n = p->n;
double* global_val = p->global_val;
double h = (b - a) / n;
int local_n = n / thread_num;
double local_a = a + thread_id * h * local_n;
double local_b = local_a + h * local_n;
double my_result = (f(local_a) + f(local_b)) / 2;
double x;
for (int i = 1; i < local_n; i++) {
x = local_a + h * i;
my_result += f(x);
}
my_result *= h;
pthread_mutex_lock(&mutex1);
*global_val += my_result;
pthread_mutex_unlock(&mutex1);
pthread_exit(nullptr);
}
void* serial_area(double a, double b, int n, double* global_val) {
double h, approx;
h = (b - a) / n;
approx = (f(a) + f(b)) / 2;
for (int i = 1; i < n; i++) {
approx += f(a + i * h);
}
*global_val = approx * h;
return nullptr;
}
long test_time(int algorithm_type, int n, double* global_val) {
struct timeval start, end;
long total;
if (algorithm_type == 0) {
cout<<"Serial:"<<endl;
gettimeofday(&start, NULL);
serial_area(0, 1, n, global_val);
}
else if (algorithm_type == 1) {
cout<<"OMP1:"<<endl;
gettimeofday(&start, NULL);
# pragma omp parallel num_threads(4)
omp1_area(0, 1, n, global_val);
}
else if (algorithm_type == 2) {
cout<<"OMP2:"<<endl;
gettimeofday(&start, NULL);
# pragma omp parallel num_threads(4)
{
double my_result = 0;
double* result_ptr = (double*)omp2_area(0, 1, n, global_val);
my_result += *result_ptr;
# pragma omp critical
*global_val += my_result;
free(result_ptr);
}
}
else if (algorithm_type == 3) {
cout<<"OMP3:"<<endl;
double temp = 0;
gettimeofday(&start, NULL);
# pragma omp parallel num_threads(4) reduction(+:temp)
{
double* result_ptr = (double*)omp2_area(0, 1, n, global_val);
temp += *result_ptr;
}
*global_val = temp;
}
else if (algorithm_type == 4) {
cout<<"OMP4:"<<endl;
gettimeofday(&start, NULL);
omp3_area(0, 1, n, global_val);
}
else if (algorithm_type == 5) {
cout<<"PThread:"<<endl;
mutex1 = (pthread_mutex_t)PTHREAD_MUTEX_INITIALIZER;
pthread_t thread[4];
thread_parm thread_parm[4];
for (int i = 0; i < 4; i++) {
thread_parm[i].a = 0;
thread_parm[i].b = 1;
thread_parm[i].thread_id = i;
thread_parm[i].thread_num = 4;
thread_parm[i].global_val = global_val;
thread_parm[i].n = n;
}
gettimeofday(&start, NULL);
for (int i = 0; i < 4; i++) {
pthread_create(&thread[i], NULL, pthread_area, (void*)&thread_parm[i]);
}
for (int i = 0; i < 4; i++) {
pthread_join(thread[i], nullptr);
}
pthread_mutex_destroy(&mutex1);
}
gettimeofday(&end, NULL);
total = (1000000 * (end.tv_sec - start.tv_sec) + (end.tv_usec - start.tv_usec)) / 1000;
return total;
}
clang++ -Xpreprocessor -fopenmp -lomp main.cpp -o main