项目背景及目标
通过银行数据来预测客户是否购买产品。
目标
1.分析各个因素对是否购买产品的影响
2.建立模型预测用户是否购买
数据集
数据集来源:
https://www.kesci.com/home/competition/5c234c6626ba91002bfdfdd3/content/5
代码参考:
https://www.kesci.com/home/project/5ec0c5edb7c5170037f3b74e
数据内容分析
影响是否购买产品的数据分为三个部分:
用户数据:age,job,maritial(是否结婚),education;
行为数据(信用):default(违约),balance(每年账户平均余额),hosing(房贷),loan(借贷)
业务数据:contact(联系方式),day(最后一次联系时间),month最后一次联系时间),duration(联系持续时间),campaign(活动中与客户交流的次数),pdays(距离上次联系的天数),previous(本次活动之前,与客户交流的次数),poutcome (上次活动结果)
分析过程
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
import sklearn
from sklearn.linear_model import LogisticRegression #逻辑回归
from sklearn.model_selection import train_test_split #原始数据照比例分割为测试集,训练集
from sklearn.metrics import roc_auc_score #返回精度值
from sklearn.metrics import classification_report #返回正确率,召回率,F1等
from sklearn import preprocessing #预处理
1. 读取和查看数据
df_train=pd.read_csv('train_set.csv')
df_test=pd.read_csv('test_set.csv')
df_train.info()
df_test.info()
df_train.head()

df_test.head()

字符型特征中存在unkwown值,我们认为unknown值是缺失值。特征为字符串格式,无法放到模型训练,后期需要该字段需要进行离散型特征编码。
我们观察到days(最后一次联系的时间(几号))和month(最后一次联系的时间(月份))与pdays(距离上次活动最后一次联系该客户,过去了多久(999表示没有联系过))之间存在特征重合,保留pdays特征。
df_train.drop(['day','month'],inplace=True,axis=1)
df_test.drop(['day','month'],inplace=True,axis=1)
df_train.describe()

df_test.describe()

2.数据清洗
重复值
df_train.duplicated().all() #重复值
异常值
df_train.boxplot() #箱线图查看是否有正负异常

缺失值
def missing_data(data):
total = data.isin(['unknown']).sum()
percent = (data.isin(['unknown']).sum()/data.isin(['unknown']).count()*100) #count计算总行数,计算0和1个数;sum计算所以0和1的加和
tt = pd.concat([total, percent], axis=1, keys=['Total', 'Percent'])
types = []
for col in data.columns:
dtype = str(data[col].dtype)
types.append(dtype)
tt['types'] = types
return(np.transpose(tt))
missing_data(df_train)

考虑到职业、教育程度、通讯方式都是离散型数据,采用众数进行填补。上一次活动结果poutcome因为是大部分缺失,依据80%原则(非缺失部分低于总样本量的80%)删除poutcome列。
删除poutcome
df_train.drop('poutcome',inplace=True,axis=1)
df_test.drop('poutcome',inplace=True,axis=1)
替换unknown值
df_train['job'].replace(['unknown'],df_train['job'].mode(),inplace=True)
df_test['job'].replace(['unknown'],df_test['job'].mode(),inplace=True)
df_train['education'].replace(['unknown'],df_train['education'].mode(),inplace=True)
df_test['education'].replace(['unknown'],df_test['education'].mode(),inplace=True)
df_train['contact'].replace(['unknown'],df_train['contact'].mode(),inplace=True)
df_test['contact'].replace(['unknown'],df_test['contact'].mode(),inplace=True)
** 3. 分析及可视化**
3.1 label值
查看label的分布,确定数据集是否是偏斜样本
#
client_purchase=df_train[df_train.loc[:,'y']==1].copy()
client_not_purchase=df_train[df_train.loc[:,'y']==0].copy()
#
#两种方法可以计算
#buy_rate=df_buy.shape[0]/df_train.shape[0]或者buy_rate=df_train['y'].sum()/df_train.shape[0]
pie_data = {'purchase rate': client_purchase.shape[0],
'': df_train.shape[0]-client_purchase.shape[0]}
explode = (0.2, 0) # 突出购买率
fig1, ax = plt.subplots()
sizes=pie_data.values()
labels =['{}:{}'.format(key,value) for key,value in pie_data.items()]
ax.pie(sizes, explode=explode, labels=labels, autopct='%1.1f%%',
shadow=True, startangle=90)
ax.axis('equal') # 确保圆形
plt.show()

可以看出,定期理财产品的购买率不高,同时训练样本极其不均衡。后边可以使用过采样解决样本不均衡问题。
3.2 特征分析
分别从用户数据,信用数据和业务数据三个角度分析
年龄:定量数据(连续型),直方图
print("最小的年龄:{}".format(df_train['age'].min()))
print("最大的年龄:{}".format(df_train['age'].max()))
直方图
fg = sns.FacetGrid(data=df_train,height=6,hue='y')
fg = (fg.map(sns.distplot,'age',bins=[20,30,40,50,60,70,80,90])
.add_legend())

通过年龄分布直方图发现:
1.数据样本集中在年龄低的分段
2.年龄超过60岁和年龄低30岁的人更喜欢定期理财
职业:定性数据(离散数据),条形图
fg=sns.catplot(data=df_train,x='job',kind='bar',y='y',ci=None)
fg=(fg.set_xticklabels(rotation=90)
.set_axis_labels('','purchase rate')
.despine(left=True))

通过职业分类查看观察到:
1.退休人员和学生最青睐定期理财,其次是失业人员
2.蓝领定期理财的比率最低
**婚姻:**定性数据(离散型)
fg=sns.catplot(data=df_train,x='marital',kind='bar',y='y',ci=None,aspect=.8)
fg=(fg.set_axis_labels('marital','purchase rate')
.despine(left=True))

按照婚姻情况分类观察到:单身相比离异和已婚倾向于定期理财。
**教育:**定性数据(离散型)
fg=sns.catplot(data=df_train,x='education',kind='bar',y='y',ci=None,aspect=.6)
fg=(fg.set_axis_labels('education','purchase rate')
.despine(left=True))

职业-教育:
g = sns.catplot(x='job', y='y', col='education',
data=df_train, saturation=.5,
kind='bar', col_order=['primary','secondary','tertiary'],
aspect=1.2,ci=None)
g = (g.set_axis_labels('job', 'purchase rate')
.set_xticklabels(rotation=90)
.set_titles('{col_name} {col_var}')
.despine(left=True))

从上图我们观察到:
1.无论接受教育的程度如何,进行定期理财的人主要是退休人员和学生,其次是失业人员。
2.随着教育程度的提高,管理人员、技术人员、行政人员、蓝领、企业家、自由职业者、事业人员越来越倾向接受定期理财。
违约,房贷,借贷:
fg=sns.catplot(data=df_train,x='default',kind='bar',y='y',ci=None,order=['yes','no'])
fg.set_axis_labels("default",'purchase rate')
fg=sns.catplot(data=df_train,x='housing',kind='bar',y='y',ci=None,order=['yes','no'])
fg.set_axis_labels("housing",'purchase rate')
fg=sns.catplot(data=df_train,x='loan',kind='bar',y='y',ci=None,order=['yes','no'])
fg.set_axis_labels("loan",'purchase rate')


观察到:
没有违约的人倾向于定期理财
没有房贷的人倾向于定期理财
没有个人贷款的人倾向于定期理财
业务数据:联系方式,持续时间,活动次数,距离上一次练习时间,上次活动联系次数
fg=sns.catplot(data=df_train,x='contact',kind='bar',y='y',ci=None)
fg.set_axis_labels("contact",'purchase rate')
fg=sns.catplot(data=df_train,x='campaign',kind='bar',y='y',ci=None,aspect=2)
fg.set_axis_labels("campaign",'purchase rate')
fg = sns.FacetGrid(data=df_train,height=6,hue='y')
fg = (fg.map(sns.distplot,'duration',bins=40)
.add_legend())


通过沟通方式等特征分析观察到:
通过移动电话沟通客户定期理财的比率高
沟通次数长并不一定能够提高客户进行定期理财的比率
最后一次沟通的超过一定时长(大约300)后定期理财比率提高
两个特征的相关性
fig,axes=plt.subplots(1,3)
#pearson系数
ax0=axes[0].imshow(X=df_train.corr())
#kendall系数
ax1=axes[1].imshow(X=df_train.corr(method='kendall'))
#spearman系数
ax2=axes[2].imshow(X=df_train.corr(method='spearman'))
fig.colorbar(ax0,ax=[axes[0],axes[1],axes[2]])
fig.set_size_inches(30,8)
##当然可以使用sns.heatmap函数还可以显示对应的值

将相关性数值表示出来
sns.heatmap(data=df_train.corr(),annot=True)

根据previous系数,duration(最后一次联系的交流时长)与预测值成弱相关性,pdays(距离上次活动最后一次联系该客户,过去了多久)和previous(在本次活动之前,与该客户交流过的次数)成相关性。
4.数据模型
数据集预处理
# 采用哑变量进行编码
train_data=pd.get_dummies(df_train.iloc[:,:-1])
train_data.drop('ID',inplace=True,axis=1)
train_target=df_train.loc[:,'y']
print(train_data.head())

建立和训练模型
#划分训练集和验证集
X_train, X_test, y_train, y_test = train_test_split(train_data, train_target, test_size=0.2, random_state=0)
LR=LogisticRegression(solver='liblinear')
#对训练集X_train训练
LR.fit(X_train,y_train)
#给出训练的精度
LR.score(X_train,y_train)
输出:0.892114748432331
#对于验证集x_test进行预测
x_pre_test=LR.predict(X_test) #返回预测标签
x_pre_test
输出:array([0, 0, 0, …, 0, 0, 0], dtype=int64)
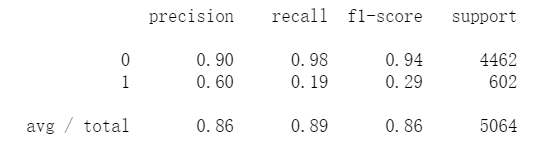
print(classification_report(y_test, x_pre_test)) #文本型预测分类报告
x_pro_test = LR.predict_proba(X_test) #返回预测属于某标签的概率
print("验证集的预测可能性:{}".format(x_pro_test))
#计算验证集的auc值,参数为预测值和概率估计
auc=roc_auc_score(y_test, x_pro_test[:, 1]) #精度值 0.85
print("auc的值:{}".format(auc))

5.结果预测
df_out=pd.DataFrame(df_test['ID'].copy())
df_test.drop('ID',inplace=True,axis=1)
df_test=pd.get_dummies(df_test)
#对测试集df_test进行预测
y_pre_test=LR.predict(df_test)
y_pre_test
输出:array([0, 0, 0, …, 0, 0, 0], dtype=int64)
#预测df_test分类的可能性
y_test_pro=LR.predict_proba(df_test)
y_test_pro

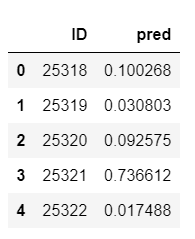
df_out['pred']=y_test_pro[:,1]
df_out=df_out[['ID','pred']]
df_out.head()
df_out.to_csv(r'./result.csv',index=False)