目录:
- 一、字符串介绍
- 1、字符的渲染
- 2、字符的编码
- 3、不可变类型
- 二、字符串的基本操作
- 1、字符串声明
- 2、字符串占位符号
- 3、字符串索引切片(包含练习)
- 4、字符串转义
- 三、字符串的高级操作
- 1、字符串变形
- 2、字符串查询
- 3、字符串替换
- 4、字符串拆分和拼接
- 5、字符串修饰(空格处理)
- 6、字符串格式化(重点)
- 7、字符串判断
- 8、字符串编码(加密解密)
- 9、转义字符
- 10、元字字符
- 四、案例操作
- 1、字符串变形
- 2、字符串空格处理
- 3、字符串对齐
- 4、字符串查询
- 5、字符串替换
- 6、字符串拆分
- 7、字符串加密解密(初级)
创作不易,各位看官,点个赞收藏、关注必回关、QAQ、您的点赞是我更新的最大动力!


一、字符串介绍
人一生使用最多的事情什么?那肯定是说话,那么对应到程序当中就是字符串的使用
1、字符的渲染
- 计算机中的数据都是二进制数据,由 0 或 1 组成,这样的数据在屏幕上怎么展示对应的字符信息?
- 计算机屏幕上各种颜色的灯,作为灯来说两种状态[开灯 | 关灯],不同颜色的灯光打开或者关闭的操作方式,形成了屏幕上展示的画面,在这样的情况下完成了数据在屏幕上展示出来的字符串[字母、数字、特殊符号、汉字]
2、字符的编码
-
计算机中怎么描述不同的字符?
英文字母有规律(固定形状的 26 个大小写字母 x2)、数字有规律(0~9 10 个数字),最原始的计算机(M 国)使用 ASCLL 编码,只能表示英文字母、数字、为数不多的特殊符号。
欧洲国家开始出现了计算机[M 国出售],需要计算机表示欧洲各个国家的字符数据,需要在ASCII 编码的基础上进行扩展,出现了拉丁编码:Latin 编码→ ISO-8859-1 编码,西欧字符编码,可以正常描述西欧标准字符数据.
天朝开始意识到计算机的重要性,引入在天朝开始发展计算机中的数据描述方式(二进制方式)对于中文的展示非常不友好,按照四角编码描述汉字的方式开始研发计算机中的字符数据的展示方式:出现了描述繁体中文的 BIG5 编码(大五码), 国家标准编码(GB2312)在后续发展的过程中,出现国家标准扩展编码(GBK)发展到(GB18030)已经可以表示大部分的正常的汉字和各个民族的语言。从此大天朝可以正常使用计算机!
全球不同的国家使用计算机,都有自己各自的编码方式,导致不同的国家的数据信息不好传播和共享!书同文车同轨~ 欧洲计算机制造协会联盟组织**(民间组织|ISO)**统一各国的字符编码方式,让不同的国家的计算机可以正常正确的描述其他国家的语言数据统一字符编码:万国码:编码是一种语法标准 Unicode 编码,使用 1~4 个字节来描述一个英文字母、数字、特殊符号、汉字等等各种语言字符。
随着网络的发展,出现了网络数据传输标准编码:Unicode Transfer Format 8bit 以 8 个字节为单位进行网络数据传输,可以完成正常的大部分数据的正确传输 UTF-8 python 诞生于 89 年,1.x 版本只是在自己的公司,和一些技术爱好者在使用,语法底层采用的是 ascii 编码,所以不能表示汉字.
2.x 版本出现之后,成为了一种通用编程语言,被大量的公司采用用来做服务器操作系统的自动维护,但是 2.x 版本底层采用的依然是 ascii 编码,但是同时支持 utf-8需要在 python 文件的第一行说明支持中文:# -- encoding:utf-8 --
3.x 版本出现之后,底层编码方式进行了改动,使用 unicode 作为统一编码,所以不再纠结 python 中不能正确使用中文的问题了(哪怕使用中文词语作为变量!)

3、不可变类型
字符串由于在项目中经常使用,所以编程语言对于字符串进行了优化,将字符串定义为不可 变类型,所谓不可变类型就是一旦声明初始化,这个字符串常驻内存。 如下代码分析字符串在内存中的创建和赋值


**变量:**在程序中创建和回收非常频繁,所以在栈内存中分配空间,栈内存空间特点分配空间 效率高,缺点不稳定,刚好符合变量的使用特性 对象:在程序中创建和回收复杂对象非常频繁和消耗资源,并且创建的复杂对象我们要求稳 定,堆内存就有这样的特点,堆内存中申请空间比较频繁,一旦申请好空间就会比较稳定, 刚好符合对象的使用特征
如下代码分析字符串在内存中的创建和赋值:


字符串为什么是不可变类型:
- Python 中针对项目中最常见的字符串进行了优化,将字符串的声明和操作定义为了 不可变类型,这样在项目中随时使用任意字符串时都能从内存中直接获取对应的字符 串数据,方便了字符串对象的创建优化
- 内存中字符串一旦创建,该对象就会常驻内存,并且不允许修改,当其他变量需要这 个字符串时会直接赋值,省略了申请空间创建对象的步骤,所以处理效率得到了提升
二、字符串基本操作
1、字符串声明- python 的语法中,使用引号包含的一串字符,就是字符串类型的数据
python 中有三种不同的字符串:长字符串、单引号包含的字符串、双引号包含的字符串
(1) 长字符串
通常是由三对引号包含的字符串,可以包含换行,但是长字符一般情况下不当成字符串使用,都被当成注释进行操作

(2) 单引号包含的字符闯[python的方言]

(3) 双引号包含的字符串[编程语言普通话]

2、字符串占位符号
字符串在程序中的操作,经常做多个字符串数据的拼接!
(1) 常规字符串的拼接操作
info = "我的年龄是:"
info2 = "我的姓名是:"
pirnt(info,str(18),info,稳稳)
print(info+str(18)+info2+稳稳)
备注:传统的字符串拼接方式,太过繁琐!Print()语句中打印多个字符串出现了多个逗号分隔的字符串,拼接输出;多个字符串使用+符号拼接时,就会出现大量的加号、引号、类型转换等等操作,最终可能会因为误操作出现的概率增加导致开发效率下降。
(2)字符串的占位符: %
① 占位符号中、填充一个字符串数据
name = "稳稳"
print("我的姓名是: %s " % name)
# 我的姓名是: 稳稳
② 占位符号中、填充两个字符串数据
name = "稳稳"
gender = "男"
print("我的姓名是:%s,性别:%s " % (name,gender))
# 我的姓名是:稳稳,性别:男
③ 占位符号中、填充三个字符串数据、包含整数数据
name = "稳稳"
gender = "男"
age = 18
print("我的姓名是:%s,性别:%s ,年龄:%s" % (name,gender,age))
# 我的姓名是:稳稳,性别:男 ,年龄:18
④ 占位符的格式化输出
name = "稳稳"
gender = "男"
age = 18
height=1.78624
print("我的姓名是:%s" %name) #我的姓名是:稳稳
print("我的姓名是:%10s" %name) #我的姓名是: 稳稳 默认空格左边10个
print("我的姓名是:%-10s" % name)#我的姓名是:稳稳 空格右边10个
print("我的年龄是:%d" % age) #我的年龄是:18
print("我的年龄是:%8d" % age)#我的年龄是: 18
print("我的年龄是:%08d" % age) #我的年龄是:00000018
print("我的身高是:%f" % height) #我的身高是:1.786240
print("我的身高是:%.2f" % height) #我的身高是:1.79 保留2位小数 并且后面的四舍五入
print("我的身高是:%5.2f" % height) #我的身高是: 1.79 保留5位 前面默认2个空格
print("我的身高是:%05.2f" % height)#我的身高是:01.79 保留5位 前面一个空格一个0
print("我的身高是:%#5.2f" % height)#我的身高是: 1.79
3、字符串索引切片
字符串的切片指的是从字符串中复制出一份指定的内容,存储在另外一个变量中,不会对原 字符串进行修改
切片格式:[起始索引:结束索引:[步长]] 注: 步长可以省略,默认为 1 包括开头不包含结尾

(1) 字符串索引
字符串中每一个个体我们称之为字符或者元素。索引指的是字符的下标 字符串索引正序从 0 开始,倒序从-1 开始


通过字符串的索引可以获取指定的字符 格式:变量名[索引值]
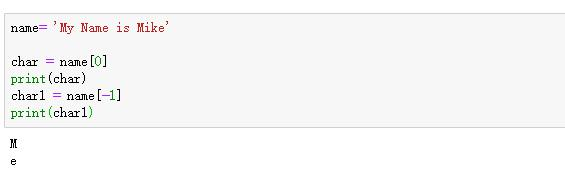
(2) 字符串字符顺序

(3) 字符串的顺序意义
类似列表,按照字符串中的字符位置,获取部分数据:字符串切片
基本语法:S[开始位置:结束位置:间隔字符数]
① 顺序编号切片
header = "c:/images/header.jpg"
print(header[0])# 获取指定索引位置的字符 c
print(header[0:1])# 获取指定索引范围的字符 c
print(header[0:2])# 获取指定索引范围的字符 c:
print(header[0:10])# 获取指定索引范围的字符c:/images/
② 倒叙编号切片
header = "c:/images/header.jpg"
print(header[-1])# g
print(header[-2:-1])# p
print(header[-3:-1])# jp
print(header[-3:])# jpg
print(header[-4:])# .jpg
③ 笔试出现
s = 'hellopython'
print(s[0:8]) #hellopyt
print(s[0:8:2])#hloy
print(s[::-1])#nohtypolleh 翻转打印
(3) 字符串练习
1. 步长练习

2. 结束索引练习
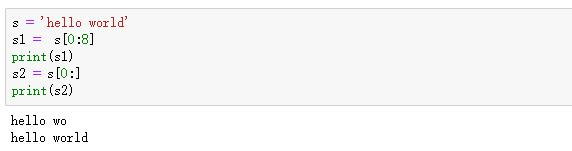
3. 起始索引练习

4. 综合练习

5. 步长为负值练习
步长为负值表示从开始索引位置往左截取

6. 起始索引和结束索引为负值

7. 遍历字符串
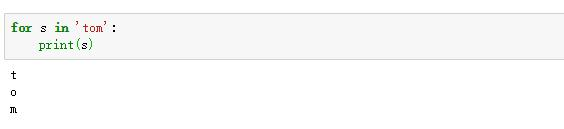
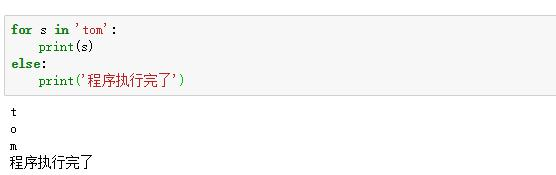
案例1:获取用户上传头像的图片名称(不包含文件夹路径)

4、字符串转义
转义:转变原来的意义的意思!
举例:n 本来就是一个普通小写字母,字母前面添加一个符号\n,这个字母就改变了原来的
意思从一个普通字符,转换成了 superman:换行符号!
在上面的案例中,改变字母意义的符号:(反斜杠),就称为转义符号。
一般情况下,转义符号都是将一个字符串,进行转义的!
- \n:换行
- \r:回车
- \a:警铃
- \t:一个制表符[键盘上的 tab 键
三、字符串高级操作
通过 dir()函数查看 python 中对于使用最为频繁的字符串,都提供了那些操作方法
1、字符串变形
| 方法 | 描述 |
|---|---|
| capitalize | 首字母大写 |
| title | 标题~首字母大写 |
| upper | 全部大写 |
| lower | 全部小写 |
| swapcase | 转换大小写 |
2、字符串查询
| 方法 | 功能 |
|---|---|
| find | 查找,返回从左第一个指定字符的索引,找不到返回-1 |
| rfind | 查找,返回从右第一个指定字符的索引,找不到返回-1 |
| index | 查找,返回从左第一个指定字符的索引,找不到报错 |
| rindex | 查找,返回从右第一个指定字符的索引,找不到报错 |
| count | 计数功能,返回自定字符在字符串当中的个数 |
3、字符串替换
| 描述 | 方法 |
|---|---|
| replace | 从左到右替换指定的元素,可以指定替换的个数,默认全部替换 |
| translate | 按照对应关系来替换内容fromstringimportmaketrans |
4、字符串拆分和拼接
| 描述 | 方法 |
|---|---|
| partition | 把mystr以str分割成三部分,str前,str自身和str后 |
| splitlines | 按照行分隔,返回一个包含各行作为元素的列表,按照换行符分割 |
| split | 按照指定的内容进行分割,maxsplit:默认将指定的所有的内容进行分割,可以指定maxsplit的值,如果maxsplit=1表示只按照第一个指定内容进行分割,后面剩余的不分割 |
| rsplit | |
| join | 按照给定的字符,将多个数据拼接到一起 |
5、字符串修饰(空格处理)
| 方法 | 描述 |
|---|---|
| center | 让字符串在指定的长度居中,如果不能居中左短右长,可以指定填充内容,默认以空格填充 |
| ljust | 让字符串在指定的长度左齐,可以指定填充内容,默认以空格填充 |
| rjust | 让字符串在指定的长度右齐,可以指定填充内容,默认以空格填充 |
| zfill | 将字符串填充到指定的长度,不足地方用0从左开始补充 |
| format | 按照顺序,将后面的参数传递给前面的大括号 |
| strip | 默认去除两边的空格,去除内容可以指定 |
| rstrip | 默认去除右边的空格,去除内容可以指定 |
| lstrip | 默认去除左边的空格,去除内容可以指定 |
6、字符串格式化
字符串有自己的占位符,可以先占位后输出,但是占位符的处理方式并不是特别友好,尤其是占位符的编码~看上去并不是特别规范和标准,所以python3.5+版本添加了字符串的数据格式化输出,并且 python3.7之后添加了格式化字符串,让字符串的操作更加先进和优秀,让开发人员欲罢不能!
分为三种方法:
- ① 百分号% 占位符操作:
- ② format() 字符串格式化
- ③ f 字符串:格式化字符串 [最常用]
① 百分号% 占位符操作
使用%s 占位,操作过程中代码不是特别规范,传统编码中经常使用!
| 格式 | 描述 |
|---|---|
| %% | 百分号标记 |
| %s | 字符串 |
| %d | 有符号整数(十进制) |
| %f | 浮点数字(用小数点符号) |

② format() 字符串格式化
使用字符串 format()方法操作,其实也是一种占位操作,通过方法/函数将占位
的字符串和数据拼接到一起,整体性更好
(1) 使用位置参数

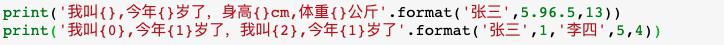
(2) 使用关键字参数

(3) 填充与格式化
格式::[填充字符][对齐方式<^>][宽度]
<表示向左对齐,^表示居中对齐,>表示向右对齐

(4) 精度与进制
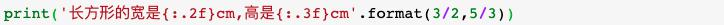

③ f 字符串:格式化字符串
使用格式化字符串,在字符串的双引号前面,加一个字符 f 【format】
name = "稳稳"
print(f"我的姓名是{name}") #我的姓名是稳稳
扩展知识点:
各种格式化字符串 s = “这是一个普通字符串”
s = b”这是一个二进制字符串” b:binary 不常用,了解
s =u”这是一个 unicode 字符串” u: unicode 不常用,了解
s = r”这是一个防止转义字符串” r 开头的字符串中,转义符号没有作用!
s = f”这是一个格式化字符串” f:format 这个字符串中可以直接读取变量数据
7、字符串判断
| 方法 | 描述 |
|---|---|
| isalnum | 判断字符串是否完全由字母或数字组成 |
| isalpha | 判断字符串是否完全由字母组成 |
| isdigit | 判断字符串是否完全由数字组成 |
| isupper | 判断字符串当中的字母是否完全是大写 |
| islower | 判断字符串当中的字母是否完全是小写 |
| istitle | 判断字符串是否满足title格式 |
| isspace | 判断字符串是否完全由空格组成 |
| startswith | 判断字符串的开头字符,也可以截取判断 |
| endswith | 判断字符串的结尾字符,也可以截取判断 |
| split | 判断字符串的分隔符切片 |
8、字符串编码(加密解密)
- ‘maketrans’,
- ‘translate’,
- a,b,c->混淆加密b,d,f->解密abc
- encode 是编码,将字符串转换成字节码。str–>byte
- decode 是解码 ,将字节码转换成字符串。 byte–>str
| 编码方式 | ASCII | Unicode | UTF-8 |
|---|---|---|---|
| 二进制表示字母‘A’ | 01000001 | 0000000001000001 | 01000001 |
| 二进制表示中文‘中’ | 0100111000101101 | 111001001011100010101101 | |
| 十六进制形式 | \u4e2d | b\xe4\xb8\xad | |
| 编码范围 | 只有英文 | 所有语言 | 所有语言 |
| 一个字符占字节数 | 1 | 2(少数偏僻字4) | 英文1,中文3(少数偏僻字4-6) |
| 特点 | 统一,英文就在ASCII前面补一个字节 | 节省,英文跟ASCII一样只有一个字节 | |
| 用处 | 内存中,服务器中,比较统一 | 保存在硬盘时,传输时,需要节省 |
| 在计算机中所有的信息最终都表示为一个二进制的字符串,每一个二进制位有0和1两种状态,通过不同的排列组合,使用0和1就可以表示世界上所有的东西 |
| 在计算机种中,1字节对应8位二进制数,而每位二进制数有0、1两种状态,因此1字节可以组合出256种状态。如果这256中状态每一个都对应一个符号,就能通过1字节的数据表示256个字符。美国人于是就制定了一套编码(其实就是个字典),描述英语中的字符和这8位二进制数的对应关系,这被称为ASCII码 |
| ASCII码一共定义了128个字符,例如大写的字母A是65(这是十进制数,对应二进制是01000001)。这128个字符只使用了8位二进制数中的后面7位,最前面的一位统一规定为0 |


| 但是随着计算机的全球普及,128 个字符无法保存其他国家的字符。因此出现了很多自己国 家的编码,例如中国的 GB2312 编码,日本把日文编到 Shift_JIS 里,韩国把韩文编到 Euc-kr 里。这样就解决了各个国家保存字符的问题。但是,如果在中国使用 GB2312 编码写的内容, 我们使用 U 盘拷一份去日本然后再使用日本的电脑打开,就会出现乱码。为了解决这个问 题,出现了‘万国码’Unicode |
| Unicode 规定了世界上所有的字符都对应一个唯一的编号,但是没有规定在电脑上怎么保存。 例如’我’这个字符对应的编号是‘12345’,这个‘12345’这个编码具体怎么在电脑上保存(占两个字节还是占三个字节)Unicode 没有规定 |
| UTF-8 编码是对 Unicode 的具体实现,UTF-8 规定了字符在电脑上的保存形式 |
| UTF-8 最大特点就是可变长。它可以使用 1 - 4 个字节表示一个字符,根据字符的不同变换长度 |
| 英文还是占 1 个字节,中文占 3 个字节 |
| 注: UTF-8 编码实现了 ASCII 码的向后兼容,对于英文中的 0 - 127 号字符,与 ASCII 码完全相 同。使用 ASCII 码编写的内容,使用 UTF-8 同样能打开 |
9、转义字符
引入: 向控制台 打印 msg=’tom’s phone number is 110’这句话

我们发现报错了,因为程序将’tom’看成了一个字符串而后面的字符串出现了语法错误。怎 么解决这个问题呢?我们可以使用双引号或者使用转义字符来解决
使用双引号

使用转义字符

转义字符:顾名思义改变原有字符的意义
转义字符格式: \特定字符
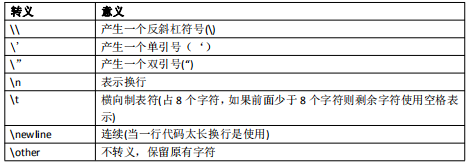

注意”\t”
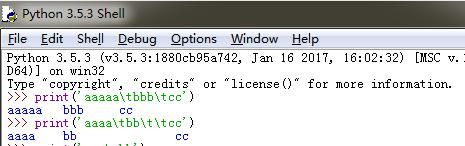
10、元字字符
在任意字符串之前添加字母 r 或者 R,那么当前字符串中所有转义字符在使用时都不会进行 转义操作,这就是元字符串,正则表达式中常见格式
R’锄禾日当午,\n汗滴\禾下土,\n谁知\r盘中餐,\n粒粒\t皆辛苦\n’


四、案例操作
1、字符串变形"""
字符串变形方法的案例
"""
while True:
print("猜数字游戏正在进行中...")
# 大小写无关的提示出现了
# 用户无论输入小写n或者大写N,都可以结束游戏
res = input("是否继续游戏(Y/N)?").upper()
if res == "Y":
print("游戏继续")
continue
elif res == "N":
print("游戏结束")
break
2、字符串空格处理
"""
字符串空格处理
"""
while True:
# 无效空格需要处理
username = input("请输入账号:").strip()
password = input("请输入密码:").strip()
if username == "admin" and password == "123":
input("账号密码正确,登录成功")
else:
input("账号或者密码有误,请重新输入")
3、字符串对齐
"""
字符串对齐操作【了解】
center 居中
ljust 左对齐
rjust 右对齐
"""
s = "hello python"
print(s.center(20))
print(s.ljust(20))
print(s.rjust(20))
'''
>>> s = "hello python"
>>> s.center(20)
' hello python '
>>> s.ljust(20)
'hello python '
>>> s.rjust(20)
' hello python'
>>>
'''
4、字符串查询
"""
字符串查询案例操作
startswith
endswith
find
index
rfind
rindex
"""
# (1) startswith:需求~用户个人主页
# url = input("请输入个人主页:")
# if url.startswith("https://") or url.startswith("http://"):
# input("个人主页合法,请继续完善后续资料")
# else:
# input("个人主页格式非法,请核查后重新输入.")
'''
E:\workfcb\days06>python demo04字符串查询案例.py
请输入个人主页:[email protected]
个人主页格式非法,请核查后重新输入.
E:\workfcb\days06>python demo04字符串查询案例.py
请输入个人主页:https://blod.csdn.net/xxxxxx
个人主页合法,请继续完善后续资料
'''
# (2) endswith 用户电子邮箱~ 中公邮箱
# email = input("请输入您的个人邮箱:")
# if email.endswith("@offcn.com"):
# input("邮箱合法,按任意键继续")
# else:
# input("非法邮箱格式,请核查后重新输入")
'''
E:\workfcb\days06>python demo04字符串查询案例.py
请输入您的个人邮箱:[email protected]
非法邮箱格式,请核查后重新输入
E:\workfcb\days06>python demo04字符串查询案例.py
请输入您的个人邮箱:[email protected]
邮箱合法,按任意键继续
'''
# (3) 敏感词查询:判断某个个人介绍/文件等字符串中,是否包含了敏感数据
# # index / find / rindex / rfind
# introduce = "我的个人介绍,今天去客厅一日游!"
# # 判断个人介绍中是否包含了敏感词语?
# print(introduce.index("游")) # 14
# print(introduce.find("游")) # 14
# # print(introduce.index("中国共产党")) # ValueError: 没有查询到
# print(introduce.find("中国共产党")) # -1
# (4) 用户头像图片的名称
# 注意:我们不知道这张图片的路径有多长
image = "d:/offcn/19ketang/images/img/my_header.jpg"
# 获取最后一个/符号出现的位置
i = image.rindex("/") # 28
i2 = image.rfind("/") # 28
print("图片名称:", image[i+1:])
print("图片名称:", image[i2+1:])
# 获取图片的后缀名[现在]~对图片进行压缩操作[后续]
print("图片后缀名:", image[image.rindex("."):])
print("图片后缀名:", image[image.rfind("."):])
5、字符串替换
"""
敏感词替换案例
1、查询
方便进行数据统计
对后续的业务操作有帮助
2、替换
"""
introduction = """
Python is an easy to learn,
powerful programming language.
It has efficient high-level data
structures and a simple but effective
approach to object-oriented programming.
Python’s elegant syntax and dynamic typing,
together with its interpreted nature, make
it an ideal language for scripting and
rapid application development in many
areas on most platforms.
"""
# 敏感词: syntax 语法
# (1) 查询
# 敏感词的位置: 194
print("敏感词的位置:", introduction.find("syntax"))
# (2) 替换
introduction = introduction.replace("syntax", "******")
print(introduction)
6、字符串拆分
"""
字符串拆分
案例1:用户个人爱好
案例2:用户头像
"""
# 案例1:用户个人爱好
# fav = input("请输入个人爱好(不同爱好使用英文逗号分隔):")
# # python代码中对用户的输入需要进行处理,区分不同的爱好
# fs = fav.split(",")
# print(fs)
'''
请输入个人爱好(不同爱好使用英文逗号分隔):python,java
['python', 'java']
E:\workfcb\days06>python demo06字符串拆分.py
请输入个人爱好(不同爱好使用英文逗号分隔):python,java,王者荣耀,吃鸡
['python', 'java', '王者荣耀', '吃鸡']
'''
# 案例2:用户头像路径[业务上需要将路径和文件分离]
# img_url = "d:/offcn/images/header.jpg"
# urls = img_url.rpartition("/")
# print(urls)
# ('d:/offcn/images', '/', 'header.jpg')
# 案例3:补充
# 用户的爱好:['python', 'java', '王者荣耀', '吃鸡']
# 界面上输出~ 按照字符串输入~
f = ['python', 'java', '王者荣耀', '吃鸡']
# 方案1:麻烦吗? # 1
# fav = ""
# for x in f:
# fav += x + ","
# print(fav)
# 方案2:字符串的方法直接处理 # 2
# fav = ",".join(f) # 使用,符号将列表f中的所有数据进行拼接
# print(fav)
# 案例4:网站中更换头像:网站路径~和头像名称拼接
# 头像
h = "h2.jpg"
img = ["/images/header/", h] # 头像
# 最终的头像
img_url = "".join(img)
print(img_url)
7、字符串加密解密(初级)
"""
加密解密
了解
maketrans 制作密码表
translate 加密
要求:通常注册在软件中的用户,密码必须加密后保存
"""
# 字典映射关系表
e = {"a": "1", "b": "2", "c": "3"}
# 制作密码表
table = str.maketrans(e)
# 明文密码:
s = "abc"
# 加密:使用密码表table加密
s2 = s.translate(table)
print("明文:", s, "; 加密后的密文:", s2)
# --------------------------------------
e2 = {"1": "a", "2": "b", "3": "c"}
table2 = str.maketrans(e2)
# 解密
s3 = s2.translate(table2)
print("密码:", s2, "; 解密后:", s3)